Chris Woodroofe, Gatwick's chief operating officer, said on Thursday afternoon there had been another drone sighting which meant it was impossible to say when the airport would reopen.
He told BBC News: "There are 110,000 passengers due to fly today, and the vast majority of those will see cancellations and disruption. We have had within the last hour another drone sighting so at this stage we are not open and I cannot tell you what time we will open.
"It was on the airport, seen by the police and corroborated. So having seen that drone that close to the runway it was unsafe to reopen."
The economics of this kind of thing isn't in our favor. A drone is cheap. Closing an airport for a day is very expensive.
I don't think we're going to solve this by jammers, or GPS-enabled drones that won't fly over restricted areas. I've seen some technologies that will safely disable drones in flight, but I'm not optimistic about those in the near term. The best defense is probably punitive penalties for anyone doing something like this -- enough to discourage others.
There are a lot of similar security situations, in which the cost to attack is vastly cheaper than 1) the damage caused by the attack, and 2) the cost to defend. I have long believed that this sort of thing represents an existential threat to our society.
Shamoon is the Iranian malware that was targeted against the Saudi Arabian oil company, Saudi Aramco, in 2012 and 2016. We have no idea if this new variant is also Iranian in origin, or if it is someone else entirely using the old Iranian code base.
Here is my testimony before before the House Subcommittee on Digital Commerce and Consumer Protection last November.
Defacement: Sellers armed with the accounts of Amazon distributors (sometimes legitimately, sometimes through the black market) can make all manner of changes to a rival's listings, from changing images to altering text to reclassifying a product into an irrelevant category, like "sex toys."
Phony fires: Sellers will buy their rival's product, light it on fire, and post a picture to the reviews, claiming it exploded. Amazon is quick to suspend sellers for safety claims.
[...]
Over the following days, Harris came to realize that someone had been targeting him for almost a year, preparing an intricate trap. While he had trademarked his watch and registered his brand, Dead End Survival, with Amazon, Harris hadn't trademarked the name of his Amazon seller account, SharpSurvival. So the interloper did just that, submitting to the patent office as evidence that he owned the goods a photo taken from Harris' Amazon listings, including one of Harris' own hands lighting a fire using the clasp of his survival watch. The hijacker then took that trademark to Amazon and registered it, giving him the power to kick Harris off his own listings and commandeer his name.
[...]
There are more subtle methods of sabotage as well. Sellers will sometimes buy Google ads for their competitors for unrelated products -- say, a dog food ad linking to a shampoo listing -- so that Amazon's algorithm sees the rate of clicks converting to sales drop and automatically demotes their product.
What's also interesting is how Amazon is basically its own government -- with its own rules that its suppliers have no choice but to follow. And, of course, increasingly there is no option but to sell your stuff on Amazon.
If you haven’t seen Advent of Code, give it a look. A new puzzle each day in December until Christmas. This is the fourth year running, and you can go back and look at the past years (and days).
My presentation landing page has links to the slides and the code.
The presentation took a particular Advent of Code puzzle (December 14, 2016) and explained out a few different solutions, with a small detour into unit testing.
The code shows a few different ways to deal with the problem:
- a simple implementation for part 1
- a global cache dictionary
- a local cache dictionary in a closure
- a cache decorator, similar to the @lru_cache decorator in the standard library
- finally, a PeekableIterable class to use more pure iteration
Sorry I didn’t write out the text of the talk itself...
Python has a limit on how large its stack can grow, 1000 frames by default. If you recur more than that, a RecursionError will be raised. My recursive summing function seemed simple enough. Here are the relevant methods:
class Leaf:
def __init__(self):
self.val = 0 # will have a value.
def value(self):
return self.val
class Node:
def __init__(self):
self.children = [] # will have nodes added to it.
def value(self):
return sum(c.value() for c in self.children)
My code made a tree about 600 levels deep, meaning the recursive builder function had used 600 stack frames, and Python had no problem with that. Why would value() then overflow the stack?
The answer is that each call to value() uses two stack frames. The line that calls sum() is using a generator comprehension to iterate over the children. In Python 3, all comprehensions (and in Python 2 all except list comprehensions) are actually compiled as nested functions. Executing the generator comprehension calls that hidden nested function, using up an extra stack frame.
It’s roughly as if the code was like this:def value(self):
def _comprehension():
for c in self.children:
yield c.value()
return sum(_comprehension())
Here we can see the two function calls that use the two frames: _comprehension() and then value().
Comprehensions do this so that the variables set in the comprehension don’t leak out into the surrounding code. It works great, but it costs us a stack frame per invocation.
That explains the difference between the builder and the summer: the summer is using two stack frames for each level of the tree. I’m glad I could fix this, but sad that the code is not as nice as using a comprehension:class Node:
...
def value(self):
total = 0
for c in self.children:
total += c.value()
return total
Oh well.
There are some interesting ideas being considered about how to improve GC safety in Servo.
Planning and Status
Our roadmap is available online, including the overall plans for 2018.This week’s status updates are here.
Exciting works in progress
- mandreyel is adding support for parallel CSS parsing.
- SimonSapin is slowly but surely converting buildbot CI jobs to run on Taskcluster.
- paulrouget is converting the
simpleservocrate into an API to embed Servo on new platforms without worrying about the details. - jdm is fixing the longstanding bug preventing iframes from knowing their own sizes on creation.
- oOIgnitionOo is making it easier to find regression ranges in Servo nightlies.
- cbrewster is adding profiling support for WebGL APIs.
- jdm is synchronizing WebGL rendering with WebRender’s GL requirements.
- paulrouget is separating the compositor from the rest of the browser to support more complex windowing requirements.
Notable Additions
- dlrobertson documented the ipc-channel crate.
- lucasfantacuci added support for changing the volume of media elements.
- ferjm removed a race in the media playback initialization.
- SimonSapin converted the buildbot job that publishes Servo’s documentation to run on Taskcluster.
- cdeler added support for bootstrapping a Servo build on Linux Mint.
- jdm made CSS animations expire if the animating node no longer participates in layout.
- SimonSapin wrote a lot of documentation for the new Taskcluster/Treeherder integration.
- nox implemented support for non-UTF8
Content-Typecharset values for documents.
New Contributors
Interested in helping build a web browser? Take a look at our curated list of issues that are good for new contributors!欢迎投稿,或推荐你自己的项目,请前往 GitHub 的ruanyf/weekly提交 issue。

(题图:安吉,浙江,2018)
美国一个编程培训班的老板,写了一篇文章。他说自己很担忧。现在,那么多人学习编程,他的公司全靠培训赚钱,将来会不会程序员过剩?
培训班的目的,就是让那些没有受过四年计算机教育的人,经过四个月的培训,找到一份软件开发的工作。某种程度上,这种做法是可行的,大量的程序员就是通过这种模式生产出来。
但是,人工智能正变得越来越强,终有一天,简单代码都会由计算机自已生成,低级程序员的需求将会大量减少。另一方面,云服务的兴起,使得很多任务不需要自己编程,可以购买云服务,这也减少了程序员的需求。
同时,由于不断的抽象和封装,应用层的软件开发正变得越来越简单,如果只是简单地遵循在线教程,就能编写软件,或者将一系列API混合在一起,就能做出一个服务,有必要向开发人员支付高额薪水吗?毕竟开发过程是那么简单。
他认为,学习编程是值得的,它可以帮助你理解世界。但是,梦想仅仅学会软件开发,就能解决你的人生问题是不现实的。"只是能够编写一个安卓程序,不会为你赢得竞争优势,也没法在这个超级饱和的科技世界里,获得自己的一席之地。这个世界里,每个想法都已由十位企业家在你前面完成了。"
由于其他行业不景气,大量年轻人正在转向软件业就业。但是,程序员的淘汰也很厉害,上车的人多,下车的人也多。大家应该对这一点有清醒的认识。
新闻
1、维珍银河试飞成功
12月13日,维珍银河公司(Virgin Galactic)的航天飞机试飞成功。它先由一架双头的牵引飞机载到半空,在那里再点燃火箭加速,飞到距地面82.7公里的高空。
维珍银河是2004年由维珍航空公司的创始人理查德·布兰森爵士(Sir Richard Branson)创建的,目标是开展太空旅行服务。乘客可以绕地球几圈,体验几分钟的失重。整个航天过程会持续90分钟,每次收费25万美元,已经有超过600人购买了机票或者支付了订金。
SpaceX 公司和亚马逊老板贝佐斯投资的 Blue Origin 公司,也有计划开展太空旅行服务。维珍银河将与他们展开竞争。
2、离子风飞机

麻省理工学院的科学家发明了,世界上第一架没有活动部件并且不依靠化石燃料飞行的"固态"飞机。该飞机利用"离子风"飞行,比传统飞机更安静,机械更简单,并且不会排放燃烧废物。
这种飞机内部有电池组,机翼下方有一排电线产生2万伏的电力。这个电场在机翼后部会产生氮离子流,就有足够的推力以进行持续飞行。研发团队制造了一个原型飞机,重约5磅,翼展5米,成功飞行了60米。
3、ARM 服务器

亚马逊公司开发了一款自己的64位 ARM 服务器处理器 Graviton,已经用于该公司的网络服务 AWS 的云主机,并且 ARM 虚拟机比 x86 虚拟机价格便宜45%。
由于 ARM CPU 的能耗和成本都较低,所以 ARM 服务器一直被看好。上个月,ARM 公司声称2018年 ARM 服务器将达到数百万台,其中很大部分就属于亚马逊公司。微软 Azure 云服务也希望至少一半的服务器是 ARM。这对 x86 芯片的主要生产商 Intel 公司造成了巨大压力。
4、家庭电池计划

南澳大利亚州计划提供7200万美元,在当地居民家中安装特斯拉公司的家用蓄电池。每户居民可以得到4300美元的补助,用于购买电池。
电池可以用太阳能充电,也可以在夜晚从电网充电(因为晚上的电费便宜),然后在白天使用。这样可以节省能源。
5、机器狗的人造手

波士顿动力公司唯一的公开出售产品是机器狗 SpotMini,现在有一家创业公司为这只狗加上了一对人造手。这对手目前没有实际作用,只是 3D 打印模型,售价179美元。但是,如果一旦可以编程控制,它就为这只机器狗带来了无限的可能。
6、美国汽车公司可能退出轿车生产

有消息称,通用汽车公司和福特汽车公司很快将退出美国的轿车市场,专注于生产高利润的卡车和 SUV。原因是他们的轿车销量下降得非常厉害,福特福克斯的销量从2013年的235,000辆降至2018年的115,000辆。通用汽车公司的雪佛兰科鲁兹的销量从2014年的273,000辆下降到2018年的145,000辆。
消费者更喜欢皮卡和 SUV。2018年美国排名前20位最畅销的汽车,14种是卡车或SUV。五年前,轿车占美国市场的50%,今天这个数字下降到三分之一。另一方面,美国轿车与日本轿车相比,也不占任何优势,反而成本更高。
7、Instagram 影响自然保护

美国怀俄明州的一个县旅游局,要求游客将照片发到社交媒体时,不得标识地理位置,以保护该州原始森林和偏远湖泊。
该州的三角洲湖原来是一个偏远湖泊(上图),偶尔才有人步行15公里到达。但是,自从这个湖泊上了 Instagram 的热门照片,现在每天有多达145人在那里徒步旅行,拍摄订婚照片等等。鲜为人知的小径被大量践踏,对公园资源造成负担。
8、贫穷的千禧一代

1981年至1997年之间出生的人,在美国称为"千禧一代"。美联储的一项新研究称,他们的消费比前几代人同龄时低,原因是他们的资产较少,没有能力多消费。也就是说,他们是最贫穷的一代人。
研究人员发现,千禧一代的消费比他们的父母、祖父母年轻时都要少。另一方面,他们面临的大学学费、医疗费用是几代人里面最高的。
9、窗户涂料

很多大楼的夏季空调费非常高,据统计,空调占美国总电力支出的6%。 如果有其他手段为大楼降温,就能节省大量能源。
麻省理工学院发明了一种新的窗户涂料。32摄氏度以下时,这种涂料是透明的,太阳光可以通过。一旦超过32度,这种涂料就会反射70%的太阳光,降低了大楼内部的温度。
10、一句话新闻
- 联合国预计,2019年底,全世界的上网人口将达到50%。也就是说,还有50%的人口没有互联网。
- 美国国家科学院委托一个专家委员会,评估量子计算的前景。委员会的结论是,未来十年内,建造有实用能力的量子计算机的可能性微乎其微。
- 微软宣布,Windows Server 2019 内置 OpenSSH,也就是说可以用 ssh 登陆 Windows 服务器了。
- 美国国税局(IRS)在 Instagram 开了账户,专门发布介绍税收知识的短视频。

教程
1、高级 Web 安全主题(英文)本文收集各种网页入侵的技术,已经收集了十多种。
2、何时不使用微服务?(英文)

微服务是目前流行的架构,但是会增加复杂性,比如一个 API 变成多个 API(上图)。本文讨论了哪些情况不应该使用微服务。
3、使用 Cloudflare Worker 加速谷歌字体加载(英文)
网页加载谷歌字体的最大问题是加载速度较慢,会影响网页体验。Cloudflare 提供 Worker 方案,可以改写用户的字体请求,从而加速字体加载。
4、Vue.js 框架的作者尤雨溪专访(英文)
介绍了 Vue.js 的发展历程,以及背后的想法。(@M1seRy_ _投稿)
5、Flutter 框架印象(英文)
作者较深入地评论了目前 Flutter 框架开发手机应用的优缺点,总体上还是鼓励大家使用它。
6、MVC 框架的误解(英文)

作者提出,现在那些 MVC 应用其实改叫 MVA 更合适,也就是把 Controller(控制器)改成 Adapter(适配器)。
7、QUIC 协议的注意事项(英文)
本文介绍了 QUIC 协议的一些优点。作者提出,QUIC 与其称为 HTTP/3,不如称为 TCP/2。
8、target = "_blank" 的危险性(英文)
HTML 网页的<a>元素打开的子网页,可以用window.opener.location.replace()方法替换掉父窗口的网址,这会带来风险。
9、一个人如何开发游戏《星露谷》(英文)

畅销游戏《星露谷》(Stardew Valley)作者只有一个人埃里克·巴罗恩,从编码到美术音乐都靠自己。大学毕业后,他没找工作,而是待在公寓写了四年游戏。唯一收入是晚上打工,在电影院门口收电影票。
上线前,唯一测试就是女朋友玩了几天。如果卖不出去(绝大多数游戏的结局),四年就浪费了,幸好成功了。不过,这个游戏借鉴了任天堂的《牧场物语》,有人认为他抄袭了。
10、如何编写一个硬盘启动程序?(英文)
本文教你如何向硬盘的主引导扇区 MBR 写入程序,使得计算机可以在没有操作系统的情况下运行程序,显示 Hello World。
资源
1、Pwned Passwords该网站收集已经泄漏的密码。你可以输入自己的密码,看看有没有泄漏。(@DoctorLai_ _投稿)
2、机器学习书籍清单

这份书目的特别之处在于,它是一份树状的互动图表。(@nivance投稿)
3、3D 病毒浏览器

该网站对各种病毒 3D 建模,可以缩放、旋转观看病毒模型。
4、Chinese-Podcasts
收集中文播客资源。(@alaskasquirrel投稿)
5、C ++ Annotations(英文)
C++ 开源教程,主要针对那些了解 C 语言,希望学习 C++ 的程序员。
6、程序员的实用密码学(英文)
密码学开源教材,全面介绍的密钥相关的各种基本知识。
7、DOS 游戏博物馆
该站收集 DOS 游戏,可以在线游戏。另外还有一个"中文家用游戏博物馆"。(@Brenner8023投稿)
8、HelloGitHub
一个分享 GitHub 上有趣的、入门级开源项目的月刊,每个月 28 号发布。(@521xueweihan投稿)
10、旅行者二号的海报

1977年发射的旅行者二号(Voyager 2)最近飞出了太阳系,成为飞得最远的人类飞行器。美国宇航局为了庆祝这个事件,在官网发布了一系列可以下载的海报。
工具
1、react-text一个简单的 React 国际化解决方案。
2、strapi

一个 Node 的图形界面的 API 生成框架。(@JsonLeex投稿)
3、snyk
一个在线工具,检查项目的依赖模块有没有漏洞。(@Chorola投稿)
4、q
一个对 CSV 文件使用 SQL 数据查询的工具。
5、sr.ht
一个提供代码基础服务(比如 Git 和持续构建)的网站,界面简单,具有黑客风格。
6、betwixt

一个使用 Chrome 控制台的网络面板,可以查看命令行 HTTP 请求的工具。
7、Vimium
Chrome 浏览器的扩展,使用类似 Vim 的快捷键,通过键盘操作浏览器。(@Seven-Steven投稿)
8、Squoosh
谷歌推出的图像压缩工具,代码开源。官网可以在线压缩图片,而且可以转换图片格式(比如 webp 转 jpg)。(@Seven-Steven投稿)
9、Emoji Builder

自定义 Emoji 图片。(@kt286_ _投稿)
10、lint-md
Markdown 的 lint 工具,检查编写格式是否规范。(@hustcc_ _投稿)
11、Get Github User's Public Events
查看某个用户的所有 GitHub 公开活动。(@able8投稿)
文摘
1、午夜队长20世纪20年代,电视机发明以后,电视节目都是免费的。后来,卫星电视出现了,也是免费的,只要买一个卫星天线收到信号就可以了。
1986年,HBO 公司开始对自家的卫星信号加密,用户必须缴纳每月12.95美元的订阅费,购买专用解码器才能观看。HBO 成为第一家对用户收费的卫星电视公司。这引起了很多用户的不满。
HBO 对信号加密四个月后,1986年4月26日的晚上,美国佛罗里达州的一个销售卫星电视器材的经销商约翰·迈克道格尔,利用自己商店里的设备,在0点32分向 HBO 卫星发送了干扰信号,压过了 HBO 的官方信号,导致美国东部的所有 HBO 用户看到了他设置的画面。

GOODEVENING HBO
晚上好,HBO
FROM CAPTAIN MIDNIGHT
(这条消息)来自午夜队长
\$12.95/MONTH ?
每月(要支付)12.95美元?
NO WAY !
别想啦!
[SHOWTIME/MOVIE CHANNEL BEWARE!]
[娱乐时间电视网、电影频道(即美国的两个付费影视频道),给我小心一点!]
HBO 发现信号异常以后,试图加大上传功率,压过迈克道格尔的信号,但是又担心损坏卫星而放弃了。最后,迈克道格尔自动放弃干扰,整个事件大约持续了四分半钟。
事后,美国联邦通信委员会(FCC)确定美国2,000个登记过的卫星信号发射设备之中,有580个有足够大的天线,能够覆盖 HBO 的信号。通过查阅当天是否开机,将可疑名单减少到12个。现场走访之后,将嫌疑人缩小到三个,其中就有迈克道格尔。
迈克道格尔迫于压力而自首,他被判处一年缓刑并被罚款5000美元。由于该事件,美国国会通过了新的法律,规定卫星信号劫持是联邦重罪。
2、马云如何打败 eBay
2004年,eBay 在中国拥有85%的网络拍卖市场份额。当时阿里巴巴只有 B2B 业务,很担心 eBay 影响到 B2B 市场。于是,马云开始筹备一个叫做淘宝的网站,作为 eBay 的直接竞争对手。
当时,eBay 基本上是照搬他们在美国的做法,没有为中国市场定制产品。淘宝上线后,马云尝试了各种创新,试图将自己与 eBay 区分开来,但是成效不大。
但是,eBay 有一个致命的缺点,就是他们要从交易中收费,这是 eBay 赚钱的方式。为了达到收费的目的,他们想尽办法,将买家和卖家尽可能分开,防止他们直接接触,绕过平台,私下交易。马云看到了这点,宣布淘宝不收费,并且推出了聊天功能,允许买卖双方直接聊天,这一招让 eBay 逐渐失去市场份额。
2007年,eBay 终于认输,开始退出中国市场。但是,阿里巴巴的代价也很高,就是无法从淘宝的用户交易中直接赚钱,不得不从其他渠道赚钱,比如关键词的竞价排名、店铺装修等等,后面推出天猫也是这个原因。
本周图片
1、从地心计算的地球最高点
从海平面开始计算,地球最高点是珠穆朗玛峰。
但是,地球是一个椭圆,赤道比南北极多出了几十公里。这导致从地心开始计算,最高点是厄瓜多尔的钦博拉索山( Chimborazo,海拔6268米),这座山在赤道附近,比珠穆朗玛峰高出了2公里。

钦博拉索山顶是地球上距离地心最远的地方。

2、80年代的游戏背景图案
上个世纪80年代,电脑游戏的图案一般先是手绘,然后再用数字转换仪转成像素图。



3、欧洲的空气质量
有人画了欧洲空气质量的数据图,结果发现东欧和西欧的界线,完全可以根据空气质量划分。

本周金句
1、2006年,两名美国学生完成了一个名为"发送阳光"的项目。如果手机发现,你的朋友在天气不好的地方,而你在天气很好的地方,那么手机就会提示你,拍一张照片发送给朋友,让他们振作起来。
后来,两人当中的 Mike Krieger 创建了 Instagram。
--《经济学人》
2、
在技术行业,简历几乎已经死了,我都不记得上次发送简历的时间。人们会在网上找到你,了解你正在做的事情,然后直接与你联系。
--《技术博客的重要性》
3、
最好的学生想要去最好的公司。最终,那些最好的公司有更多的人才、更多的钱、更多的数据,太多的权力将会集中在少数人手中。
--《AI 的未来》
4、
34年前,我拿到物理硕士学位以后,就离开了物理,去其他领域工作了。我喜欢理论物理,但是我要说,我觉得自己离开物理学是对的,过去34年中,理论物理的进展很少,远远不如其他领域。
理论物理没有进展的原因,主要是实验数据枯竭,没有新的粒子,没有新的空间维度,没有新的对称性。这导致了没有足够材料来发展新的物理理论。
--Robin Hanson
欢迎订阅
这个专栏每周五发布,同步更新在我的个人网站、微信公众号和语雀。微信搜索"阮一峰的网络日志 "或者扫描二维码,即可订阅。

(完)
文档信息
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)
- 发表日期:2018年12月21日
- 更多内容:档案»剪贴板
- 文集:《前方的路》,《未来世界的幸存者》
- 社交媒体:
twitter,
weibo


 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
To teach my daughters programming, I read some books about Arduino. In the process of learning Arduino, I became more and more interested in electronics on myself! After reading more technical documents about electronics (diode, transistor, capacitor, relay, thyristor etc.), Microcontrollers (Atmega from Atmel, MSP430 from Texas Instruments, STM8 from ST and so on), I had opened my view to a new area.
History books are always my favorite type. The most astonishing history book I have read in 2018 is“The Last Panther”. This book tells us an extremely cruel but real story in WWII.
Kazuo Inamoriis a famous entrepreneur in Japan. I read some books written by him at the end of this year. Surprisingly, his books definitely inspired me and even changed some parts of my mind. I really want to thank him for his teaching.
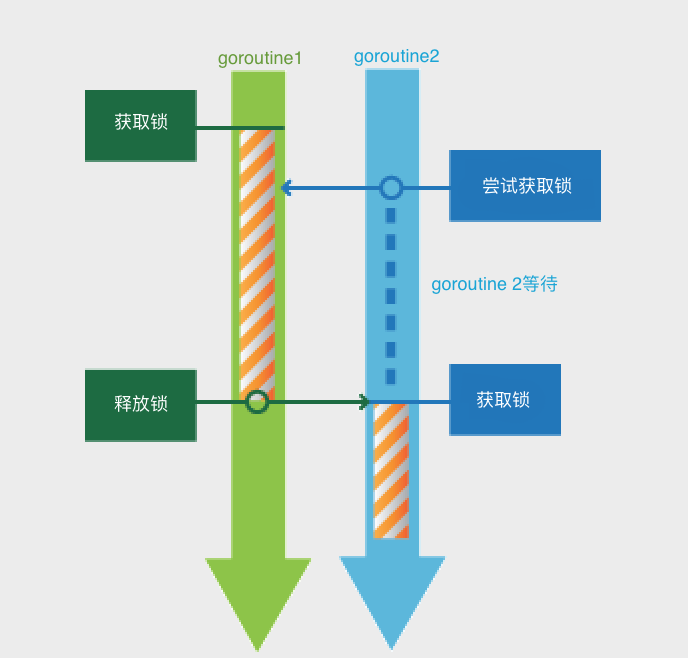
sync.Mutex的实现也是经过多次的演化,功能逐步加强,增加了公平的处理和饥饿机制。
初版的Mutex
首先我们来看看Russ Cox在2008提交的第一版的Mutex实现。12345678910111213141516171819202122232425262728293031 |
type Mutex struct { key int32; sema int32;} func xadd(val *int32, delta int32) (new int32) { for { v := *val; if cas(val, v, v+delta) { return v+delta; } } panic("unreached")} func (m *Mutex) Lock() { if xadd(&m.key, 1) == 1 { // changed from 0 to 1; we hold lock return; } sys.semacquire(&m.sema); } func (m *Mutex) Unlock() { if xadd(&m.key, -1) == 0 { // changed from 1 to 0; no contention return; } sys.semrelease(&m.sema); } |
2012年, commitdd2074c8做了一次大的改动,它将waiter count(等待者的数量)和锁标识分开来(内部实现还是合用使用state字段)。新来的 goroutine 占优势,会有更大的机会获取锁。
获取锁
, 指当前的gotoutine拥有锁的所有权,其它goroutine只有等待。
2015年, commitedcad863, Go 1.5中mutex实现为全协作式的,增加了spin机制,一旦有竞争,当前goroutine就会进入调度器。在临界区执行很短的情况下可能不是最好的解决方案。
2016年 commit0556e262, Go 1.9中增加了饥饿模式,让锁变得更公平,不公平的等待时间限制在1毫秒,并且修复了一个大bug,唤醒的goroutine总是放在等待队列的尾部会导致更加不公平的等待时间。
目前这个版本的mutex实现是相当的复杂, 如果你粗略的瞄一眼,很难理解其中的逻辑, 尤其实现中字段的共用,标识的位操作,sync函数的调用、正常模式和饥饿模式的改变等。
本文尝试解析当前sync.Mutex的实现,梳理一下Lock和Unlock的实现。
源代码分析
根据Mutex的注释,当前的Mutex有如下的性质。这些注释将极大的帮助我们理解Mutex的实现。互斥锁有两种状态:正常状态和饥饿状态。
在正常状态下,所有等待锁的goroutine按照FIFO
顺序等待。唤醒的goroutine不会直接拥有锁,而是会和新请求锁的goroutine竞争锁的拥有。新请求锁的goroutine具有优势:它正在CPU上执行,而且可能有好几个,所以刚刚唤醒的goroutine有很大可能在锁竞争中失败。在这种情况下,这个被唤醒的goroutine会加入到等待队列的前面。 如果一个等待的goroutine超过1ms没有获取锁,那么它将会把锁转变为饥饿模式。
在饥饿模式下,锁的所有权将从unlock的gorutine直接交给交给等待队列中的第一个。新来的goroutine将不会尝试去获得锁,即使锁看起来是unlock状态, 也不会去尝试自旋操作,而是放在等待队列的尾部。
如果一个等待的goroutine获取了锁,并且满足一以下其中的任何一个条件:(1)它是队列中的最后一个;(2)它等待的时候小于1ms。它会将锁的状态转换为正常状态。
正常状态有很好的性能表现,饥饿模式也是非常重要的,因为它能阻止尾部延迟的现象。
在分析源代码之前, 我们要从多线程(goroutine)的并发场景去理解为什么实现中有很多的分支。
当一个goroutine获取这个锁的时候, 有可能这个锁根本没有竞争者, 那么这个goroutine轻轻松松获取了这个锁。
而如果这个锁已经被别的goroutine拥有, 就需要考虑怎么处理当前的期望获取锁的goroutine。
同时, 当并发goroutine很多的时候,有可能会有多个竞争者, 而且还会有通过信号量唤醒的等待者。
sync.Mutex只包含两个字段:
1234 |
type Mutex struct { state int32 sema uint32} |
第1个 bit 标记这个mutex是否已唤醒, 也就是有某个唤醒的goroutine要尝试获取锁。
第2个 bit 标记这个mutex状态, 值为1表明此锁已处于饥饿状态。
同时,尝试获取锁的goroutine也有状态,有可能它是新来的goroutine,也有可能是被唤醒的goroutine, 可能是处于正常状态的goroutine, 也有可能是处于饥饿状态的goroutine。
Lock
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136 |
func (m *Mutex) Lock() { // 如果mutext的state没有被锁,也没有等待/唤醒的goroutine, 锁处于正常状态,那么获得锁,返回. // 比如锁第一次被goroutine请求时,就是这种状态。或者锁处于空闲的时候,也是这种状态。 if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) { return } // 标记本goroutine的等待时间 var waitStartTime int64 // 本goroutine是否已经处于饥饿状态 starving := false // 本goroutine是否已唤醒 awoke := false // 自旋次数 iter := 0 // 复制锁的当前状态 old := m.state for { // 第一个条件是state已被锁,但是不是饥饿状态。如果时饥饿状态,自旋时没有用的,锁的拥有权直接交给了等待队列的第一个。 // 第二个条件是还可以自旋,多核、压力不大并且在一定次数内可以自旋, 具体的条件可以参考`sync_runtime_canSpin`的实现。 // 如果满足这两个条件,不断自旋来等待锁被释放、或者进入饥饿状态、或者不能再自旋。 if old&(mutexLocked|mutexStarving) == mutexLocked && runtime_canSpin(iter) { // 自旋的过程中如果发现state还没有设置woken标识,则设置它的woken标识, 并标记自己为被唤醒。 if !awoke && old&mutexWoken == 0 && old>>mutexWaiterShift != 0 && atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) { awoke = true } runtime_doSpin() iter++ old = m.state continue } // 到了这一步, state的状态可能是: // 1. 锁还没有被释放,锁处于正常状态 // 2. 锁还没有被释放, 锁处于饥饿状态 // 3. 锁已经被释放, 锁处于正常状态 // 4. 锁已经被释放, 锁处于饥饿状态 // // 并且本gorutine的 awoke可能是true, 也可能是false (其它goutine已经设置了state的woken标识) // new 复制 state的当前状态, 用来设置新的状态 // old 是锁当前的状态 new := old // 如果old state状态不是饥饿状态, new state 设置锁, 尝试通过CAS获取锁, // 如果old state状态是饥饿状态, 则不设置new state的锁,因为饥饿状态下锁直接转给等待队列的第一个. if old&mutexStarving == 0 { new |= mutexLocked } // 将等待队列的等待者的数量加1 if old&(mutexLocked|mutexStarving) != 0 { new += 1 << mutexWaiterShift } // 如果当前goroutine已经处于饥饿状态, 并且old state的已被加锁, // 将new state的状态标记为饥饿状态, 将锁转变为饥饿状态. if starving && old&mutexLocked != 0 { new |= mutexStarving } // 如果本goroutine已经设置为唤醒状态, 需要清除new state的唤醒标记, 因为本goroutine要么获得了锁,要么进入休眠, // 总之state的新状态不再是woken状态. if awoke { if new&mutexWoken == 0 { throw("sync: inconsistent mutex state") } new &^= mutexWoken } // 通过CAS设置new state值. // 注意new的锁标记不一定是true, 也可能只是标记一下锁的state是饥饿状态. if atomic.CompareAndSwapInt32(&m.state, old, new) { // 如果old state的状态是未被锁状态,并且锁不处于饥饿状态, // 那么当前goroutine已经获取了锁的拥有权,返回 if old&(mutexLocked|mutexStarving) == 0 { break } // 设置/计算本goroutine的等待时间 queueLifo := waitStartTime != 0 if waitStartTime == 0 { waitStartTime = runtime_nanotime() } // 既然未能获取到锁, 那么就使用sleep原语阻塞本goroutine // 如果是新来的goroutine,queueLifo=false, 加入到等待队列的尾部,耐心等待 // 如果是唤醒的goroutine, queueLifo=true, 加入到等待队列的头部 runtime_SemacquireMutex(&m.sema, queueLifo) // sleep之后,此goroutine被唤醒 // 计算当前goroutine是否已经处于饥饿状态. starving = starving || runtime_nanotime()-waitStartTime > starvationThresholdNs // 得到当前的锁状态 old = m.state // 如果当前的state已经是饥饿状态 // 那么锁应该处于Unlock状态,那么应该是锁被直接交给了本goroutine if old&mutexStarving != 0 { // 如果当前的state已被锁,或者已标记为唤醒, 或者等待的队列中不为空, // 那么state是一个非法状态 if old&(mutexLocked|mutexWoken) != 0 || old>>mutexWaiterShift == 0 { throw("sync: inconsistent mutex state") } // 当前goroutine用来设置锁,并将等待的goroutine数减1. delta := int32(mutexLocked - 1<<mutexWaiterShift) // 如果本goroutine是最后一个等待者,或者它并不处于饥饿状态, // 那么我们需要把锁的state状态设置为正常模式. if !starving || old>>mutexWaiterShift == 1 { // 退出饥饿模式 delta -= mutexStarving } // 设置新state, 因为已经获得了锁,退出、返回 atomic.AddInt32(&m.state, delta) break } // 如果当前的锁是正常模式,本goroutine被唤醒,自旋次数清零,从for循环开始处重新开始 awoke = true iter = 0 } else { // 如果CAS不成功,重新获取锁的state, 从for循环开始处重新开始 old = m.state } }} |
Unlock
1234567891011121314151617181920212223242526272829303132333435363738 |
func (m *Mutex) Unlock() { // 如果state不是处于锁的状态, 那么就是Unlock根本没有加锁的mutex, panic new := atomic.AddInt32(&m.state, -mutexLocked) if (new+mutexLocked)&mutexLocked == 0 { throw("sync: unlock of unlocked mutex") } // 释放了锁,还得需要通知其它等待者 // 锁如果处于饥饿状态,直接交给等待队列的第一个, 唤醒它,让它去获取锁 // 锁如果处于正常状态, // new state如果是正常状态 if new&mutexStarving == 0 { old := new for { // 如果没有等待的goroutine, 或者锁不处于空闲的状态,直接返回. if old>>mutexWaiterShift == 0 || old&(mutexLocked|mutexWoken|mutexStarving) != 0 { return } // 将等待的goroutine数减一,并设置woken标识 new = (old - 1<<mutexWaiterShift) | mutexWoken // 设置新的state, 这里通过信号量会唤醒一个阻塞的goroutine去获取锁. if atomic.CompareAndSwapInt32(&m.state, old, new) { runtime_Semrelease(&m.sema, false) return } old = m.state } } else { // 饥饿模式下, 直接将锁的拥有权传给等待队列中的第一个. // 注意此时state的mutexLocked还没有加锁,唤醒的goroutine会设置它。 // 在此期间,如果有新的goroutine来请求锁, 因为mutex处于饥饿状态, mutex还是被认为处于锁状态, // 新来的goroutine不会把锁抢过去. runtime_Semrelease(&m.sema, true) }} |
出个问题
最后我出一个问题,你可以根据Unlock的代码分析,下面的哪个答案正确?如果一个goroutineg1通过Lock获取了锁, 在持有锁的期间, 另外一个goroutineg2调用Unlock释放这个锁, 会出现什么现象?
- A 、g2调用Unlockpanic
- B 、g2调用Unlock成功,但是如果将来g1调用Unlock会 panic
- C 、g2调用Unlock成功,如果将来g1调用Unlock也成功
答案 : B
运行下面的例子试试:
1234567891011121314151617181920 |
package mainimport ( "sync" "time")func main() { var mu sync.Mutex go func() { mu.Lock() time.Sleep(10 * time.Second) mu.Unlock() }() time.Sleep(time.Second) mu.Unlock() select {}} |

This board is cool. I’m working on making this hardware available to builds.sr.ht users in the next few months, where I intend to use it to automate the remainder of the Alpine Linux port and make it available to any other operating systems (including non-Linux) and userspace software which are interested in working on a RISC-V port. I’m fairly certain that this will be the first time hardware-backed RISC-V cycles are being made available to the public.
There are two phases to porting an operating system to a new architecture: bootstrapping and, uh, porting. For lack of a better term. As part of bootstrapping, you need to obtain a cross-compiler, port libc, and cross-compile the basics. Bootstrapping ends once the system is self-hosting: able to compile itself. The “porting” process involves compiling all of the packages available for your operating system, which can take a long time and is generally automated.
The first order of business is the cross-compiler. RISC-V support landed in binutils 2.28 and gcc 7.1 several releases ago, so no need to worry about adding a RISC-V target to our compiler. Building both with
--target=riscv64-linux-musl is sufficient to complete this step. The other
major piece is the C standard library, or libc. Unlike the C compiler, this step
required some extra effort on my part - the RISC-V port of musl libc, which
Alpine Linux is based on, is a work-in-progress and has not yet been upstreamed.There does exist a patch for RISC-V support, though it had never been tested at a scale like this. Accordingly, I ran into several bugs, for which I wrote several patches (1 2 3). Having a working distro based on the RISC-V port makes a much more compelling argument for the maturity of the port, and for its inclusion upstream, so I’m happy to have caught these issues. Until then, I added the port and my patches to the Alpine Linux musl package manually.
A C compiler and libc implementation open the floodgates to porting a huge volume of software to your platform. The next step is to identify and port the essential packages for a self-hosting system. For this, Alpine has a great bootstrapping script which handles preparing the cross-compiler and building the base system. Many (if not most) of these packages required patching, tweaks, and manual intervention - this isn’t a turnkey solution - but it is an incredibly useful tool. The most important packages at this step are the native toolchain1, the package manager itself, and various other useful things like tar, patch, openssl, and so on.
Once the essential packages are built and the system can compile itself, the long porting process begins. It’s generally wise to drop the cross-compiler here and start doing native builds, if your hardware is fast enough. This is a tradeoff, because the RISC-V system is somewhat slower than my x86_64 bootstrap machine - but many packages require lots of manual tweaks and patching to get cross-compiling working. The time saved by not worrying about this makes up for the slower build times2.
There are thousands of packages, so the next step for me (and anyone else working on a port) is to automate the remainder of the process. For me, an intermediate step is integrating this with builds.sr.ht to organize my own work and to make cycles available to other people interested in RISC-V. Not all packages are going to be ported for free - but many will! Once you unlock the programming languages - C, Python, Perl, Ruby3, etc - most open source software is pretty portable across architectures. One of my core goals with sr.ht is to encourage portable software to proliferate!
If any readers have their own RISC-V hardware, or want to try it with qemu, I have a RISC-V Alpine Linux repository here4. Something like this will install it to /mnt:
apk add \
-X https://mirror.sr.ht/alpine/main/ \
--allow-untrusted \
--arch=riscv64 \
--root=/mnt \
alpine-base alpine-sdk vim chrony
/bin/busybox --install and apk fix on first boot. This is still a work
in progress, so configuring the rest is an exercise left to the reader until I
can clean up the process and make a nice install script. Good luck!Closing note: big thanks to the help from the community in #riscv on Freenode, and to the hard work of the Debian and Fedora teams paving a lot of the way and getting patches out there for lots of software! I still got to have all the fun working on musl so I wasn’t entirely on the beaten path :)
-
Meaning a compiler which both targets RISC-V and runs on RISC-V. ↩
-
I was actually really impressed with the speed of the HiFive Unleashed. The main bottleneck is the mmcblk driver - once you get files in the kernel cache things are quite pleasant and snappy. ↩
-
I have all four of these now! ↩
-
main, community, testing ↩
年底的钉钉四周年发布会上,CEO陈航高调宣布了钉钉的行业领先的地位,并且带来了围绕企业管理中“人、财、事、物”的多元场景解决方案。
这次的升级,被视为钉钉的“重装上阵”,作为高效的企业IM,加上数字化的各类办公场景解决方案,外界解读是阿里对腾讯进军B端形成了新一轮遏制。
而同样在今年,腾讯也宣布接来下进军B端的战略重点,其中企业微信更是被提高到了腾讯未来拥抱产业互联网的“七种武器”之一。海水正在变红,过去沉醉在流量温室里的微信终于开始重视了钉钉在企服市场巨大影响力,行业迎来了巨头们亲自上阵的短兵相接。

1.阿里的反戈一击
为什么钉钉这样的产品,却没有诞生在更擅长IM领域的腾讯?
这还得从2014年马云强推来往的惨痛失败说起。
现在回头看,来往的失败是注定的,但经此一役,阿里终于看清了自己的基因,以及在推广来往过程中,展现出了对B端强有力的号召力;而对于微信,阿里内部也知道了不能死磕,要寻找信息碎片化下的软肋。
寻找突破口的机会,是陈航抢来的,注定了钉钉诞生在求生和雪恨的欲望中。
陈航是当时来往是负责人,也是阿里有名的“连续失败者”,做一淘,没成功;做“来往”,还是不行。在阿里这样的公司,连续失败意味着机会会越来越少。
每天都看着来往的数据在掉,陈航的压力巨大,“人都是有感情的,一帮兄弟跟着你混,如果说就地解散那是什么感觉?必须要给他们一个交代,怎么办?这个战场不行换个战场打!”
“成功就是从失败到失败,也依然不改热情”丘吉尔说出这句名言时正值他人生的至暗时刻,面对滞留在敦刻尔克三十万年轻士兵的生死,丘吉尔顶住巨大的压力做出了宣战选择。
陈航也需要做一个选择,接受失败的结果,还是重新开始,对他来说,钉钉是自己最后一次机会。“如果再次失败,团队会解散,资源会重组” 陈航后来自己也说“当时没有什么高大上的想法,就是想要活下去。”
带着来往的一帮“残兵败将”,陈航和团队一头扎进了湖畔花园,对阿里人来说,这里是一切故事开始的地方。

采用民房创业的好处就是,团队可以近乎不眠不休地专注于项目研发,湖畔花园有一个游泳池。每次工作得焦头烂额时,陈航和其他人就会一头扎进游泳池里。通过这种方式,度过了最难熬的日子。
事实上,陈航的洞察没有错,在钉钉之前,中小企业内部沟通的替代品就是QQ和微信,但这显然没有真正满足管理的潜在需求。
企业最大的痛点在沟通达成协同的成本,对于一条工作指令,在微信时代可能被忽视,被搁置,进而影响目标的执行力和达成效率,这会让企业主极度缺乏掌控感。
这就给了钉钉机会。
现在看,钉钉从一开始就围绕企业老板的需求做的思路无疑是正确的,虽然在这一点上,团队也有过争议,但是陈航认为,只有企业的老板认为这款软件有用才可能让自己的员工都使用。
消息必达是钉钉最核心的功能,也是外界争议和吐槽最多的地方,因为它让管理者给了执行者直接的压力。钉钉发出的消息可以看到阅读状态,在钉钉群聊中,不仅可以显示阅读状态以及哪几位未读,并且可以选择把消息通过钉一下的形式推送给未读者,推送的途径是通过电话形式到达对方手机,确保信息及时传达到。
从钉钉的在线沟通,到短信,再到电话,一直确保信息必达为止。
“我们做的最核心的技术创新,是把互联网与电话网络无缝融合。”陈航说,原来在微信上聊天聊很长时间,但效率没有提高,因为微信只是一个聊天的工具,但是工作是有强制性的。
这些功能并不是来自于产品经理的YY,为了搞清楚企业沟通中的痛点到底是什么,钉钉团队曾经疯狂地对 1200家中小企业做了调研,“有时候用户自己也不知道到底要什么,你去问是问不出来的,但是需求是可以从观察中感受的,我们当时的要求就是让团队待在用户企业里去看每一件事,但用户是有戒心的,所以必须要和他们吃在一起喝在一起。”
获得了核心的场景洞察,还要懂得如何推向市场,从钉钉最早的三板斧中,我们不难看出钉钉接地气的打法。
首先是抓住企业经营者最核心的痛点,但同时,也要给出一条决策者和工作者都能接受的目标——大家都要增加工作效率。
第二,完善的使用教育——企业申请钉钉后,首先可以得到完整的使用培训。
第三,免费——想想360当年如何拿下了杀毒市场,而当时国内的同行们,更多的是在苦大仇深的强调收费必要性。
在这三板斧之下,钉钉在市场上的成功是可以预见的。从2015年1月钉钉在北京正式发布开始,三年时间,钉钉的企业组织超过700万家; 2017年底,钉钉的个人用户突破一亿。
“一开始我们只想活下去,后来发现踩到了企业服务市场的大风口”陈航总结。
2.企鹅toB的缓慢转身
就在陈航一行人跑到湖畔花园创业的时候,腾讯这边也发生了一件大事。
2014年4月腾讯与京东宣布合作:京东将收购腾讯B2C平台QQ网购和C2C平台拍拍网的100%权益、物流人员和资产。
促成这笔交易的是高瓴资本的张磊,据说当时腾讯内部对于电商的“卖身”有过反对,但张磊靠着“库存”说服了马化腾:做电商要做库存管理,做到1000亿元的时候,可能会有两三百亿元的库存,每天都要检查,否则会被人偷、被人贪污、被人损耗。张磊最后对马化腾说:“腾讯最大的问题不是赚钱,而是要减少不该花的时间和精力”马化腾想了想,同意了。
这个故事后来被写进了《创京东》中,现在看来,腾讯toB焦虑的种子,很早就种下了。
微信曾经给整个腾讯带来了巨大的流量和安全感,但这种安全感并不是永久的,微信没有经历过失败,它的很多理念都成了权威,这是很危险的。
事实上,市面上很多产品的都很尴尬的发现,在微信几乎覆盖了几乎全部智能手机用户的时代,任何获取用户的行为看上去都像是虎口拔牙。
腾讯上一次忌惮的产品,是抖音,想想抖音连社区都还没发展起来,却在短时间就成了微信生态的大敌,因为它准确切入了用户生活娱乐的场景,找到了微信没有满足用户的那个点。
但随着用户场景的变化,和用户需求的加深,微信一定会迎来一个流量逐渐流失的周期。这个周期和更多元的场景有关,也和用户在沟通中扮演的不同角色有关。
因为企业沟通是有强制性的,所以冲破流量封锁,首当其冲的机会就在这里。
但要说腾讯不重视企业IM的市场,似乎也不尽然。
腾讯通RTX是腾讯最早推出的企业级服务产品,试图以实时通信切入企业服务市场,它的前身是BQQ,企业版QQ。除此之外,腾讯在近年还推出过TIM,以及刚刚被扶正的企业微信。
也许你很容易就发现一个问题,腾讯内部的多款同类产品赛马竞争,却没有做出一款可以直接挑战钉钉的杀手级应用,而企业微信开始受到重视,已经是2018年的消息了。
黄铁鸣是腾讯企业微信的产品部总经理,同时,也是张小龙团队的成员。2005年 Foxmail 被腾讯收购后,黄铁鸣便跟随张小龙进入腾讯,共同完成了 QQ 邮箱、微信等腾讯关键产品的创立,被不少人认为他是张小龙的门徒。
对张小龙来说,微信的成功,很大程度上来源于功能上极致的简洁,张小龙曾经不止一次地向团队强调功能聚焦的重要性“一个APP只做一件事情,一个大而全的APP意味着全面的平庸。”
时至今日,在企业微信上,我们依然能看到这种“简洁”的产品观,除了核心的沟通,企业微信相比钉钉并没有太多功能。

打开企业微信,你会发现这款软件构建了工作中基础的内部通讯模块,同时配备了简单的日程管理、审批报备、文件云盘等基础功能,而对于企业工作流程中诸如销售 CRM、行政管理、薪酬社保等其他应用,只能选择“第三方应用”的中心化入口(一个类似于微信小程序的入口)。
相反的,“连接器”却是出现频率最高的词语,这也与腾讯集团在“3Q 大战”之后腾讯提倡的“连接”定位一致。
腾讯在移动办公的战略非常简单:用社交产品中 IM(即时通讯)的强项,辅以开放的接口与插件,最终希望通过ISV 提供各个细分场景的应用,希望用“连接器”搞定办公软件的一体化。
但在对ISV的态度上,钉钉CEO陈航就有自己的看法,“钉钉与ISV要做融合,不做连接。”他认为唯有融合,才能让双方在资源投入最大化的前提下做好产品,而后者只是对平台流量的贪念。
3. 要庞然大物还是要简洁
一位SaaS领域的资深人士在评价两者时表示:现在腾讯还在用“沟通”来诠释企业办公,在当下显得太肤浅了,在更复杂的企业管理场景下,企业会希望有一整套的解决方案,而不是一个聊天的功能。
相比企业微信,钉钉要庞大得多。
“现在越来越难回答钉钉是什么,因为产品的边界在不断拓展以适应更复杂的场景。”这是陈航的观点,和腾讯的产品所强调的简洁完全不同。
比赛中最可怕的一点是什么?前面领先的对手,一直比你跑得快!
在诞生1400天之后,钉钉已经从一个移动办公的IM工具,变成了如今一套覆盖各种工作场景的企业服务生态。
从软件层面的 IM、OA 延伸到HR SaaS、智能客服,再跨出企业软件的范畴研发硬件,钉钉可能是国内最为痴迷推销硬件的企业服务公司。

在今年,钉钉连续发布的智能前台M2(考勤机)、智能通讯中心C1(路由器)、智能投屏FOCUS等办公产品;配合阿里云和其他商旅产品,钉钉可以对企业经营中更多的类似打卡、会议、审批、出差、报销等工作场景达到覆盖。
同时,在餐饮、零售、快消、物流等垂直领域,钉钉联合西贝莜面村、大润发等各行业的头部公司,输出企业办公管理解决方案。
软件、硬件、解决方案是钉钉如今的“三驾马车”。
陈航后来这样解释钉钉:“工具属性只是载体,而真正能产生重要影响的,是钉钉通过日志周报、已读回执、DING一下等功能体现出的管理思想——对工作效率的尊重。”
免费依然是撒手锏,巨头的涌入和关注并没有带给行业春天,一位业内人士透露,目前国内大量SaaS公司都处在活得不那么滋润,但也死不了的状态。当免费成为市场主流,SaaS企业不得不去面对“难以收费”的行业现实。“但我们也会积极寻求和大公司合作”这位SaaS行业人士最后说。
而在市值4000亿美元的阿里巴巴庇护下,钉钉得以用自己的节奏野蛮生长,而不用像其他SaaS企业的同行们那样,对收费使用、续费率这些事苦大仇深。
2018年秋冬发布会上,陈航公布了钉钉创业四周年的成果,企业管理中的各种场景被归纳在“人、财、物、事”四个关键词后面。
和往常一样,陈航照例在发布会结尾,强调了钉钉脱胎于来往的失败。是“向死而生”的产物。用一个工具连接市场,再辅以各种场景化的服务和可落地的管理解决方案,钉钉作为入口的背后,是数万亿的企服市场。
4.腾讯不会做另一个钉钉
对腾讯来说,要想打败钉钉,就不可能做下一个钉钉。
在企业微信的显眼位置,有一个“下班了”的功能,目前这也是用户点赞最多的功能,能够看出,企业微信希望在产品端尽量减少办公沟通时的员工压力,用腾讯的话说:“愿意在非工作时间工作的人打造一个纯粹的工作沟通环境。”

这些都是腾讯产品“善良”“有温度”的价值观体现,但这项很受员工欢迎的功能却被一些资深的行业人士所批评,行业人士认为从这个功能可以看出,企业微信思考的是如何更少地去打扰到用户,这依然是腾讯toC的产品思维,“工作上需要协同的,你休息一下,他也休息一下,怎么开展工作?”
对这些功能陈航不以为然,“至少我不用担心他们会再做出一个钉钉,以我的了解,今天他们不会做这个事情。因为我们追求的人性诉求和微信追求的人性诉求不一样,微信追求接收者的诉求,我们面对的是发送者的诉求,要用直接手段提升工作效率。”
围绕B端领域,阿里和腾讯已经开始了短兵相接,不再是投资小巨头的“代理人战争”,这次是双方亲自下场,刺刀都拿在手上了。
面对关于腾讯toB重心是否带来压力的疑问,陈航偶尔也会私下承认“微信拥有7亿用户,可以迅速获得第一批种子用户,轻松起跑。这对钉钉未来来说,也会有潜在的压力。”
一定程度而言,钉钉和企业微信的差异,是中国最大的两家互联网公司所展现出的产品哲学的差异,以及背后大相庭径的企业管理方式和价值观的体现。
在这个冬天 ,如果一定要让人选择一款企业im。
员工也许会喜欢企业微信,但是老板一定会选择钉钉。
但问题是,谁才是决策者呢?
本文由舍予兄(VX:shuyang9451)原创,刊登与转载请尊重版权,保留此句,也欢迎toB领域的探讨与交流。
原文链接:《钉钉刺痛腾讯,万亿企服市场的沉默战争》
有腾讯内部人士转发有关ofo的评论文章《谁杀死了ofo》,并援引文章内容:如果说ofo的成功是过去几年中国市场资本力量无往不胜的幻觉,那么ofo的溃败则是这种幻觉的破灭。
该人士进一步指出,ofo排斥智能化,在智能化浪潮中必然不堪一击,资本最终也无能为力。而马化腾认为,原因“不是这个,是一个veto right(否决权)”。
据知情人士透露,在ofo董事会中,戴威、滴滴、经纬都有一票否决权。
欢聚时代董事长兼CEO李学凌也在其朋友圈发出了相同的观点,称ofo真正的死因在于“一票否决权”。
他解释称,目前,戴威、阿里、滴滴、经纬都拥有一票否决权。“5个一票否决权,啥事都不通过。很多创业公司不太注意法律的设定,留下很多的法律漏洞,这样的情况下对公司来讲可能造成致命的威胁。”李学凌表示。
原文链接:《马化腾评ofo溃败原因:否决权问题》


































The post KubeCon NA 2018 Wrap Up: Docker and the Kubernetes Community appeared first on Docker Blog.
The post Desigual Transforms the In-Store Customer Experience with Docker Enterprise appeared first on Docker Blog.
The post Speak at DockerCon San Francisco 2019 – Call for Papers is Open appeared first on Docker Blog.
What a year!
2018 was a great year for the Go ecosystem, with package management as one of our major focuses. In February, we started a community-wide discussion about how to integrate package management directly into the Go toolchain, and in August we delivered the first rough implementation of that feature, called Go modules, in Go 1.11. The migration to Go modules will be the most far-reaching change for the Go ecosystem since Go 1. Converting the entire ecosystem—code, users, tools, and so on—from GOPATH to modules will require work in many different areas. The module system will in turn help us deliver better authentication and build speeds to the Go ecosystem.This post is a preview of what the Go team is planning relating to modules in 2019.
Releases
Go 1.11, released in August 2018, introduced preliminary support for modules. For now, module support is maintained alongside the traditional GOPATH-based mechanisms. Thego command defaults to module mode when run
in directory trees outside GOPATH/src and
marked by go.mod files in their roots.
This setting can be overridden by setting the transitional
environment variable $GO111MODULE to on or off;
the default behavior is auto mode.
We’ve already seen significant adoption of modules across the Go community,
along with many helpful suggestions and bug reports
to help us improve modules.
Go 1.12, scheduled for February 2019, will refine module support but still leave it in
auto mode by default.
In addition to many bug fixes and other minor improvements,
perhaps the most significant change in Go 1.12
is that commands like go run x.go
or go get rsc.io/2fa@v1.1.0
can now operate in GO111MODULE=on mode without an explicit go.mod file.
Our aim is for Go 1.13, scheduled for August 2019, to enable module mode by default (that is, to change the default from
auto to on)
and deprecate GOPATH mode.
In order to do that, we’ve been working on better tooling support
along with better support for the open-source module ecosystem.
Tooling & IDE Integration
In the eight years that we’ve had GOPATH, an incredible amount of tooling has been created that assumes Go source code is stored in GOPATH. Moving to modules requires updating all code that makes that assumption. We’ve designed a new package, golang.org/x/tools/go/packages, that abstracts the operation of finding and loading information about the Go source code for a given target. This new package adapts automatically to both GOPATH and modules mode and is also extensible to tool-specific code layouts, such as the one used by Bazel. We’ve been working with tool authors throughout the Go community to help them adopt golang.org/x/tools/go/packages in their tools.As part of this effort, we’ve also been working to unify the various source code querying tools like gocode, godef, and go-outline into a single tool that can be used from the command line and also supports the language server protocol used by modern IDEs.
The transition to modules and the changes in package loading also prompted a significant change to Go program analysis. As part of reworking
go vet to support modules,
we introduced a generalized framework for incremental
analysis of Go programs,
in which an analyzer is invoked for one package at a time.
In this framework, the analysis of one package can write out facts
made available to analyses of other packages that import the first.
For example, go vet’s analysis of the log package
determines and records the fact that log.Printf is a fmt.Printf wrapper.
Then go vet can check printf-style format strings in other packages
that call log.Printf.
This framework should enable many new, sophisticated
program analysis tools to help developers find bugs earlier
and understand code better.
Module Index
One of the most important parts of the original design forgo get
was that it was decentralized:
we believed then—and we still believe today—that
anyone should be able to publish their code on any server,
in contrast to central registries
such as Perl’s CPAN, Java’s Maven, or Node’s NPM.
Placing domain names at the start of the go get import space
reused an existing decentralized system
and avoided needing to solve anew the problems of
deciding who can use which names.
It also allowed companies to import code on private servers
alongside code from public servers.
It is critical to preserve this decentralization as we shift to Go modules.
Decentralization of Go’s dependencies has had many benefits, but it also brought a few significant drawbacks. The first is that it’s too hard to find all the publicly-available Go packages. Every site that wants to deliver information about packages has to do its own crawling, or else wait until a user asks about a particular package before fetching it.
We are working on a new service, the Go Module Index, that will provide a public log of packages entering the Go ecosystem. Sites like godoc.org and goreportcard.com will be able to watch this log for new entries instead of each independently implementing code to find new packages. We also want the service to allow looking up packages using simple queries, to allow
goimports to add
imports for packages that have not yet been downloaded to the local system.
Module Authentication
Today,go get relies on connection-level authentication (HTTPS or SSH)
to check that it is talking to the right server to download code.
There is no additional check of the code itself,
leaving open the possibility of man-in-the-middle attacks
if the HTTPS or SSH mechanisms are compromised in some way.
Decentralization means that the code for a build is fetched
from many different servers, which means the build depends on
many systems to serve correct code.
The Go modules design improves code authentication by storing a
go.sum file in each module;
that file lists the cryptographic hash
of the expected file tree for each of the module’s dependencies.
When using modules, the go command uses go.sum to verify
that dependencies are bit-for-bit identical to the expected versions
before using them in a build.
But the go.sum file only lists hashes for the specific dependencies
used by that module.
If you are adding a new dependency
or updating dependencies with go get -u,
there is no corresponding entry in go.sum and therefore
no direct authentication of the downloaded bits.
For publicly-available modules, we intend to run a service we call a notary that follows the module index log, downloads new modules, and cryptographically signs statements of the form “module M at version V has file tree hash H.” The notary service will publish all these notarized hashes in a queryable, Certificate Transparency-style tamper-proof log, so that anyone can verify that the notary is behaving correctly. This log will serve as a public, global
go.sum file
that go get can use to authenticate modules
when adding or updating dependencies.
We are aiming to have the
go command check notarized hashes
for publicly-available modules not already in go.sum
starting in Go 1.13.
Module Mirrors
Because the decentralizedgo get fetches code from multiple origin servers,
fetching code is only as fast and reliable as the slowest,
least reliable server.
The only defense available before modules was to vendor
dependencies into your own repositories.
While vendoring will continue to be supported,
we’d prefer a solution that works for all modules—not just the ones you’re already using—and
that does not require duplicating a dependency into every
repository that uses it.
The Go module design introduces the idea of a module proxy, which is a server that the
go command asks for modules,
instead of the origin servers.
One important kind of proxy is a module mirror,
which answers requests for modules by fetching them
from origin servers and then caching them for use in
future requests.
A well-run mirror should be fast and reliable
even when some origin servers have gone down.
We are planning to launch a mirror service for publicly-available modules in 2019.
JFrog’s GoCenter and Microsoft’s Athens projects are planning mirror services too.
(We anticipate that companies will have multiple options for running
their own internal mirrors as well, but this post is focusing on public mirrors.)
One potential problem with mirrors is that they are precisely man-in-the-middle servers, making them a natural target for attacks. Go developers need some assurance that the mirrors are providing the same bits that the origin servers would. The notary process we described in the previous section addresses exactly this concern, and it will apply to downloads using mirrors as well as downloads using origin servers. The mirrors themselves need not be trusted.
We are aiming to have the Google-run module mirror ready to be used by default in the
go command starting in Go 1.13.
Using an alternate mirror, or no mirror at all, will be trivial
to configure.
Module Discovery
Finally, we mentioned earlier that the module index will make it easier to build sites like godoc.org. Part of our work in 2019 will be a major revamp of godoc.org to make it more useful for developers who need to discover available modules and then decide whether to rely on a given module or not.Big Picture
This diagram shows how module source code moves through the design in this post.
go command
and any sites like godoc.org—fetched code directly from each code host.
Now they can fetch cached code from a fast, reliable mirror,
while still authenticating that the downloaded bits are correct.
And the index service makes it easy for mirrors, godoc.org,
and any other similar sites to keep up with all the great new
code being added to the Go ecosystem every day.
We’re excited about the future of Go modules in 2019, and we hope you are too. Happy New Year!
In this blog post I'll cover Clippy and Rustfmt – two tools that have been around for a few years and are now stable and ready for general use. I'll also cover IDE support – a key workflow for many users which is now much better supported. I'll start by talking about Rustfix, a new tool which was central to our edition migration plans.
Rustfix
Rustfix is a tool for automatically making changes to Rust code. It is a key part of our migration story for the 2018 edition, making the transition from 2015 to 2018 editions much easier, and in many cases completely automatic. This is essential, since without such a tool we'd be much more limited in the kinds of breaking changes users would accept.A simple example:
trait Foo {
fn foo(&self, i32);
}
trait Foo {
fn foo(&self, _: i32);
}
cargo fix --edition.Rustfix can do a lot, but it is not perfect. When it can't fix your code, it will emit a warning informing you that you need to fix it manually. We're continuing to work to improve things.
Rustfix works by automatically applying suggestions from the compiler. When we add or improve the compiler's suggestion for fixing an error or warning, then that improves Rustfix. We use the same information in an IDE to give quick fixes (such as automatically adding imports).
Thank you to Pascal Hertleif (killercup), Oliver Scherer (oli-obk), Alex Crichton, Zack Davis, and Eric Huss for developing Rustfix and the compiler lints which it uses.
Clippy
Clippy is a linter for Rust. It has numerous (currently 290!) lints to help improve the correctness, performance and style of your programs. Each lint can be turned on or off (allow), and configured as either an error (deny) or
warning (warn).An example: the
iter_next_loop
lint checks that you haven't made an error by iterating on the result of next
rather than the object you're calling next on (this is an easy mistake to make
when changing a while let loop to a for loop).for x in y.next() {
// ...
}
error: you are iterating over `Iterator::next()` which is an Option; this will compile but is probably not what you want
--> src/main.rs:4:14
|
4 | for x in y.next() {
| ^^^^^^^^
|
= note: #[deny(clippy::iter_next_loop)] on by default
= help: for further information visit https://rust-lang.github.io/rust-clippy/master/index.html#iter_next_loop
With Rust 1.31 and the 2018 edition, Clippy is available on stable Rust and has backwards compatibility guarantees (if it had a version number, it would be 1.0). Clippy has the same stability guarantees as rustc: new lints may be added, and lints may be modified to add more functionality, however lints may never be removed (only deprecated). This means that code that compiles with Clippy will continue to compile with Clippy (provided there are no lints set to error via
deny), but may throw new warnings.Clippy can be installed using
rustup component add clippy, then use it with
cargo clippy. For more information, including how to run it in your CI, see
the repo readme.Thank you Clippy team (Pascal Hertleif (killercup), Oliver Scherer (oli-obk), Manish Goregaokar (manishearth), and Andre Bogus (llogiq))!
Rustfmt
Rustfmt is a tool for formatting your source code. It takes arbitrary, messy code and turns it into neat, beautifully styled code.Automatically formatting saves you time and mental energy. You don't need to worry about style as you code. If you use Rustfmt in your CI (
cargo fmt --check), then you don't need to worry about code style in review. By using a
standard style you make your project feel more familiar for new contributors and
spare yourself arguments about code style. Rust's standard code
style is
the Rustfmt default, but if you must, then you can customize Rustfmt
extensively.Rustfmt 1.0 is part of the 2018 edition release. It should work on all code and will be backwards compatible until the 2.0 release. By backwards compatible we mean that if your code is formatted (i.e., excluding bugs which prevent any formatting or code which does not compile), it will always be formatted in the same way. This guarantee only applies if you use the default formatting options.
Rustfmt is not done. Formatting is not perfect, in particular we don't touch comments and string literals and we are pretty limited with macro definitions and some macro uses. We're likely to improve formatting here, but you will need to opt-in to these changes until there is a 2.0 release. We are planning on having a 2.0 release. Unlike Rust itself, we think its a good idea to have a breaking release of Rustfmt and expect that to happen some time in late 2019.
To install Rustfmt, use
rustup component add rustfmt. To format your project,
use cargo fmt. You can also format individual files using rustfmt (though
note that by default rustfmt will format nested modules). You can also use
Rustfmt in your editor or IDE using the RLS (see below; no need to install
rustfmt for this, it comes as part of the RLS). We recommend configuring your
editor to run rustfmt on save. Not having to think about formatting at all as
you type is a pleasant change.Thank you Seiichi Uchida (topecongiro), Marcus Klaas, and all the Rustfmt contributors!
IDE support
For many users, their IDE is the most important tool. Rust IDE support has been in the works for a while and is a highly demanded feature. Rust is now supported in many IDEs and editors: IntelliJ, Visual Studio Code, Atom, Sublime Text, Eclipse (and more...). Follow each link for installation instructions.Editor support is powered in two different ways: IntelliJ uses its own compiler, the other editors use the Rust compiler via the Rust Language Server (RLS). Both approaches give a good but imperfect IDE experience. You should probably choose based on which editor you prefer (although if your project does not use Cargo, then you won't be able to use the RLS).
All these editors come with support for standard IDE functions including 'go to definition', 'find all references', code completion, renaming, and reformatting.
The RLS has been developed by the Rust dev tools team, it is a bid to bring Rust support to as many IDEs and editors as possible. It directly uses Cargo and the Rust compiler to provide accurate information about a program. Due to performance constraints, code completion is not yet powered by the compiler and therefore can be a bit more hit and miss than other features.
Thanks to the IDEs and editors team for work on the RLS and the various IDEs and extensions (alexheretic, autozimu, jasonwilliams, LucasBullen, matklad, vlad20012, Xanewok), Jonathan Turner for helping start off the RLS, and phildawes, kngwyu, jwilm, and the other Racer contributors for their work on Racer (the code completion component of the RLS)!
The future
We're not done yet! There's lots more we think we can do in the tools domain over the next year or so.We've been improving rust debugging support in LLDB and GDB and there is more in the works. We're experimenting with distributing our own versions with Rustup and making debugging from your IDE easier and more powerful.
We hope to make the RLS faster, more stable, and more accurate; including using the compiler for code completion.
We want to make Cargo a lot more powerful: Cargo will handle compiled binaries as well as source code, which will make building and installing crates faster. We will support better integration with other build systems (which in turn will enable using the RLS with more projects). We'll add commands for adding and upgrading dependencies, and to help with security audits.
Rustdoc will see improvements to its source view (powered by the RLS) and links between documentation for different crates.
There's always lots of interesting things to work on. If you'd like to help chat to us on GitHub or Discord.
As one of Uber’s summer 2018 interns, I could not have been more excited to work on the technologies used by my friends and family on the Uber platform every day. Working on a computer science degree, …
The post Interning at Uber: Building the Uber Eats Menu Scheduler appeared first on Uber Engineering Blog.
For those unfamiliar with the work of Uber’s Visualization group, our team focuses on delivering data products for a variety of customers, from city authorities to self-driving engineers. We support the organization with advanced products to …
The post Four Ways Uber Visualization Made an Impact in 2018 appeared first on Uber Engineering Blog.
The diversity of Uber’s open source offerings speaks to the complexity of our technology stack and the business problems we use these projects to solve. Open source also gives our engineers, data scientists, and researchers the opportunity …
The post Year in Review: 2018 Highlights from Uber Open Source appeared first on Uber Engineering Blog.
In 2018, we published articles on topics spanning the breadth and depth of our technical stack, from a …
The post Year in Review: 2018 Highlights from the Uber Engineering Blog appeared first on Uber Engineering Blog.
The post Learning PHP, MySQL & JavaScript, 5th Edition appeared first on All IT eBooks.
The post Developing Games on the Raspberry Pi appeared first on All IT eBooks.