"mipsytipsy" / 2025-07-10 3 months ago / 未收藏/ charity.wtf/
发送到 kindle
I’ve never published an essay quite like this. I’ve written about my life before, reams of stuff actually, because that’s how I process what I think, but never for public consumption. I’ve been pushing myself to write more lately because my co-authors and I have a whole fucking book to write between now and October. […]
"Daniel Lemire" / 2025-07-10 3 months ago / 未收藏/ Daniel Lemire's blog/
发送到 kindle
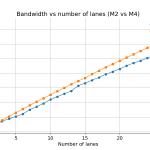 The Apple M2, introduced in 2022, and the Apple M4, launched in 2024, are both ARM-based system-on-chip (SoC) designs featuring unified memory architecture. That is, they use the same memory for both graphics (GPU) and main computations (CPU). The M2 processor relies on LPDDR5 memory whereas the M4 relies on LPDDR5X which should provide slightly … Continue reading Memory-level parallelism :: Apple M2 vs Apple M4
The Apple M2, introduced in 2022, and the Apple M4, launched in 2024, are both ARM-based system-on-chip (SoC) designs featuring unified memory architecture. That is, they use the same memory for both graphics (GPU) and main computations (CPU). The M2 processor relies on LPDDR5 memory whereas the M4 relies on LPDDR5X which should provide slightly … Continue reading Memory-level parallelism :: Apple M2 vs Apple M4"Tobias Bieniek" / 2025-07-12 3 months ago / 未收藏/ The Rust Programming Language Blog/
发送到 kindle
Since our last development update in February 2025, we have continued to make significant improvements to crates.io. In this blog post, we want to give you an update on the latest changes that we have made to crates.io over the past few months.
Trusted Publishing eliminates the need for GitHub Actions secrets when publishing crates from your CI/CD pipeline. Instead of managing API tokens, you can now configure which GitHub repository you trust directly on crates.io. That repository is then allowed to request a short-lived API token for publishing in a secure way using OpenID Connect (OIDC). While Trusted Publishing is currently limited to GitHub Actions, we have built it in a way that allows other CI/CD providers like GitLab CI to be supported in the future.
To get started with Trusted Publishing, you'll need to publish your first release manually. After that, you can set up trusted publishing for future releases. The detailed documentation is available at https://crates.io/docs/trusted-publishing.
Here's an example of how to set up GitHub Actions to use Trusted Publishing:
These images include the crate name, keywords, description, latest version (or rather the default version that we show for the crate), number of releases, license, and crate size. This provides much more useful information when crates.io links are shared on social media platforms or in chat applications.

The image generation has been extracted to a dedicated crate: crates_io_og_image (GitHub). We're also adding basic theming support in PR #3 to allow docs.rs to reuse the code for their own OpenGraph images.
Under the hood, the image generation uses two other excellent Rust projects: Typst for layout and text rendering, and oxipng for PNG optimization.
We would like to thank our crates.io team member @eth3lbert for implementing the initial version of this feature in PR #11422.
This enhancement was also implemented by @eth3lbert in PR #11441, building on initial work by @kbdharun.
The new system includes a template inheritance system for consistent branding across all emails. This change also enables us to support HTML emails in the future.
PR #10763 takes advantage of JSONB support in PostgreSQL and their btree ordering specification to implement SemVer sorting on the database side. This reduces the load on our API servers and improves response times for crates with many versions.
Trusted Publishing
We are excited to announce that we have implemented "Trusted Publishing" support on crates.io, as described in RFC #3691. This feature was inspired by the PyPI team's excellent work in this area, and we want to thank them for the inspiration!Trusted Publishing eliminates the need for GitHub Actions secrets when publishing crates from your CI/CD pipeline. Instead of managing API tokens, you can now configure which GitHub repository you trust directly on crates.io. That repository is then allowed to request a short-lived API token for publishing in a secure way using OpenID Connect (OIDC). While Trusted Publishing is currently limited to GitHub Actions, we have built it in a way that allows other CI/CD providers like GitLab CI to be supported in the future.
To get started with Trusted Publishing, you'll need to publish your first release manually. After that, you can set up trusted publishing for future releases. The detailed documentation is available at https://crates.io/docs/trusted-publishing.
Here's an example of how to set up GitHub Actions to use Trusted Publishing:
name: Publish to crates.io
on:
push:
tags: # Triggers when pushing tags starting with 'v'
jobs:
publish:
runs-on: ubuntu-latest
environment: release # Optional: for enhanced security
permissions:
id-token: write # Required for OIDC token exchange
steps:
- uses: actions/checkout@v4
- uses: rust-lang/crates-io-auth-action@v1
id: auth
- run: cargo publish
env:
CARGO_REGISTRY_TOKEN: ${{ steps.auth.outputs.token }}
OpenGraph Images
Previously, crates.io used a single OpenGraph image for all pages. We have now implemented dynamic OpenGraph image generation, where each crate has a dedicated image that is regenerated when new versions are published.These images include the crate name, keywords, description, latest version (or rather the default version that we show for the crate), number of releases, license, and crate size. This provides much more useful information when crates.io links are shared on social media platforms or in chat applications.
The image generation has been extracted to a dedicated crate: crates_io_og_image (GitHub). We're also adding basic theming support in PR #3 to allow docs.rs to reuse the code for their own OpenGraph images.
Under the hood, the image generation uses two other excellent Rust projects: Typst for layout and text rendering, and oxipng for PNG optimization.
docs.rs rebuilds
Crate owners can now trigger documentation rebuilds for docs.rs directly from the crate's version list on crates.io. This can be useful when docs.rs builds have failed or when you want to take advantage of new docs.rs features without having to publish a new release just for that.We would like to thank our crates.io team member @eth3lbert for implementing the initial version of this feature in PR #11422.
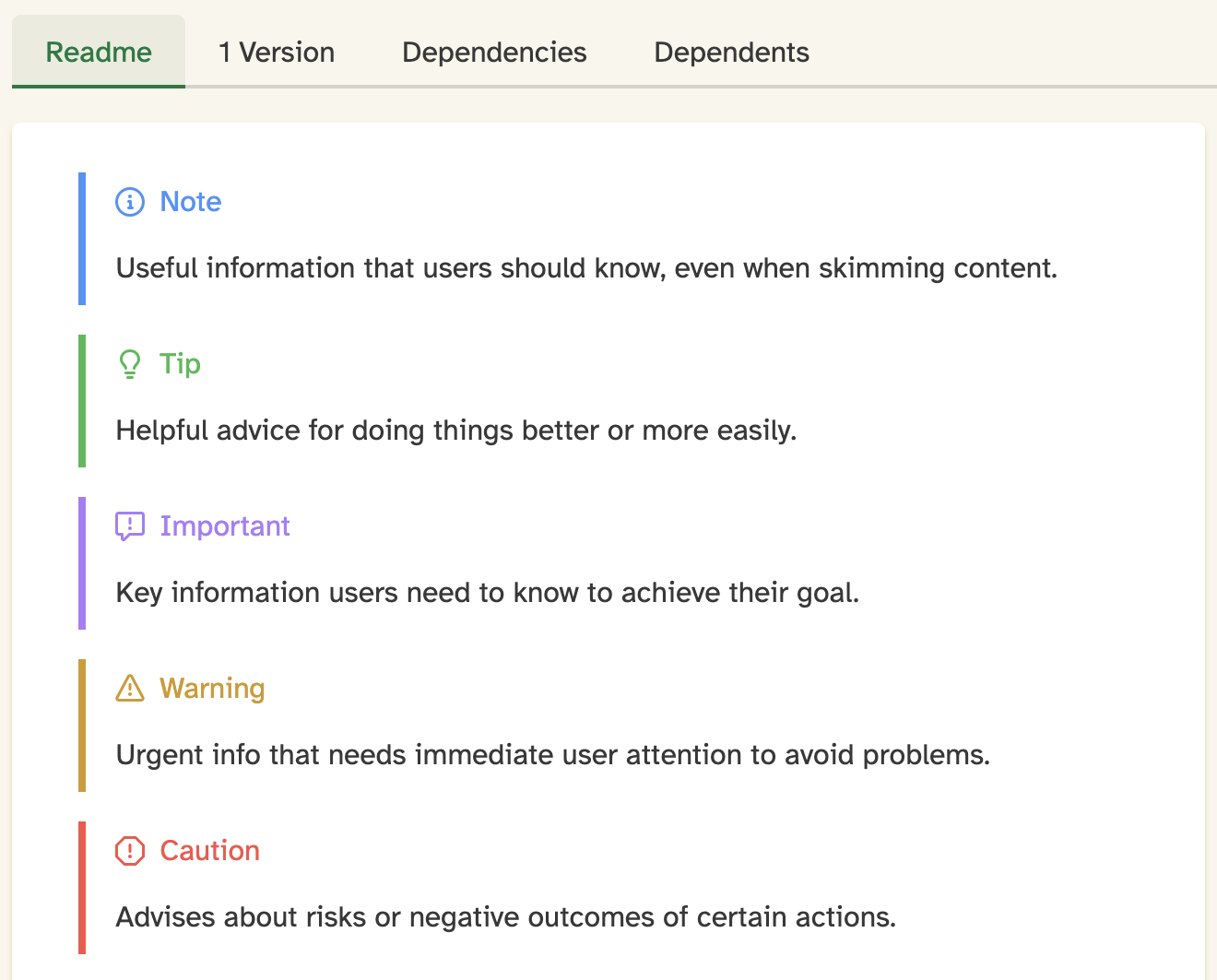
README alert support
We've added support for rendering GitHub-style alerts in README files. This feature allows crate authors to use alert blocks like> [!NOTE], > [!WARNING], and > [!CAUTION] in their README markdown, which will now be properly styled and displayed on crates.io.This enhancement was also implemented by @eth3lbert in PR #11441, building on initial work by @kbdharun.
Miscellaneous
These were some of the more visible changes to crates.io over the past couple of months, but a lot has happened "under the hood" as well. Here are a couple of examples:Email system refactoring
Previously, we used theformat!() macro and string concatenation to create emails, which made them hard to maintain and inconsistent in styling. We have migrated to the minijinja crate and now use templates instead.The new system includes a template inheritance system for consistent branding across all emails. This change also enables us to support HTML emails in the future.
SemVer sorting optimization
Previously, we had to load all versions from the database and sort them by SemVer on the API server, which was inefficient for crates with many versions. Our PostgreSQL provider did not support the semver extension, so we had to implement sorting in application code.PR #10763 takes advantage of JSONB support in PostgreSQL and their btree ordering specification to implement SemVer sorting on the database side. This reduces the load on our API servers and improves response times for crates with many versions.
Feedback
We hope you enjoyed this update on the development of crates.io. If you have any feedback or questions, please let us know on Zulip or GitHub. We are always happy to hear from you and are looking forward to your feedback!"Codecademy Team" / 2025-07-09 3 months ago / 未收藏/ Codecademy Blog/
发送到 kindle
We’ve made some exciting updates to Codecademy Pro to help you take your career to the next level. As part of Pro, you now have access to 36 intermediate and advanced learning paths, featuring certifications like AWS Certified Machine Learning – AI Specialty, Azure Security, and Google Cloud Architect. On top of that, we’ve rolled out new skill-based paths that focus on mastering popular tools like Snowflake, Terraform, and generative AI.
These new paths go far beyond the basics. With curriculum designed by industry experts, you’ll gain the practical knowledge and expertise needed to ace critical tech credentials and open doors to exciting career opportunities. You’ll even get to practice with test questions that mimic actual industry certification exams. Pro members can start using these prep materials for no extra cost — start a free trial today.
And here’s something fresh: these paths are video-based with interactive features, and brought to you by Skillsoft, the learning company that we’re proud to call home. That means you’ll get to learn in a dynamic, engaging way that keeps things interesting while giving you real-world practice.
Picture your entire team learning together, tackling hand-picked courses like IT Automation with Generative AI, or prepping for AWS certifications in unison. Teams memberships are a great way to ensure everyone works cohesively, speaks a shared technical language, and applies newly acquired knowledge consistently. Start a free 14-day trial of Codecademy Teams today.
When you’re ready, we’ll even guide you to schedule your actual industry exam with a third-party provider. The process couldn’t be smoother.
For those looking to gain skills rather than certifications, we’ve got you covered, too. Our newly launched skill-based paths focus on building practical capabilities through applied projects. For example, data professionals can expand their expertise with paths like Data Analytics with Snowflake and Advanced Snowflake. Software developers and QA teams might find courses like Automated Testing with Selenium or Terraform Expedition: Exploring Infrastructure as Code particularly helpful for tackling workflow optimization and project automation.
Start exploring what’s new today and take the first step toward unlocking your next chapter of professional growth!
document.addEventListener('DOMContentLoaded', function() {
const isFeatured = !![...document.querySelectorAll('.category-tag')].find(t => t.innerText == 'Featured');
const swiper = new Swiper('#block_684333f1be2727c528581643d69278d9 .swiper', {
direction: 'horizontal',
loop: false,
slidesPerView: 1,
slidesPerGroup: 1,
spaceBetween : 20,
// loopAdditionalSlides : 4,
navigation: {
nextEl: '.swiper-button-next-block_684333f1be2727c528581643d69278d9',
prevEl: '.swiper-button-prev-block_684333f1be2727c528581643d69278d9',
},
breakpoints: {
768: {
pagination: false,
slidesPerView: 2,
slidesPerGroup: 2,
spaceBetween : 40,
},
[isFeatured ? 1440 : 1128]: {
pagination: false,
slidesPerView: 3,
slidesPerGroup: 3,
spaceBetween : 40,
}
}
});
});
The post Introducing Even More Learning Paths for Certification Prep & Skills Training appeared first on Codecademy Blog.
These new paths go far beyond the basics. With curriculum designed by industry experts, you’ll gain the practical knowledge and expertise needed to ace critical tech credentials and open doors to exciting career opportunities. You’ll even get to practice with test questions that mimic actual industry certification exams. Pro members can start using these prep materials for no extra cost — start a free trial today.
And here’s something fresh: these paths are video-based with interactive features, and brought to you by Skillsoft, the learning company that we’re proud to call home. That means you’ll get to learn in a dynamic, engaging way that keeps things interesting while giving you real-world practice.
Who are these paths right for?
Not sure if these paths are right for you? Here’s who we had in mind:- Mid-career professionals: If you’re looking to expand your current skill set or stay competitive in a fast-changing field, these paths are built to help you level up.
- Team leaders: If you’re preparing your staff to tackle cutting-edge tools, like AI-powered technologies, our new paths can help everyone on your team get up to speed together.
- Specialists in IT, DevOps, or data: For those aiming to advance in technical domains, these skill paths deliver step-by-step guidance to master advanced tools and concepts.
Learning together with Codecademy Teams
Thinking of upskilling as a team? A Codecademy Teams membership could be the perfect solution. With Teams, your group will gain access to the full catalog of over 600 courses and paths, including these new certification prep options. Codecademy Teams offers flexibility as your team evolves, with customizable learning paths, progress tracking, robust analytics, and unlimited seat reassignment.Picture your entire team learning together, tackling hand-picked courses like IT Automation with Generative AI, or prepping for AWS certifications in unison. Teams memberships are a great way to ensure everyone works cohesively, speaks a shared technical language, and applies newly acquired knowledge consistently. Start a free 14-day trial of Codecademy Teams today.
What will you learn from the new paths?
The new certification paths are directly aligned with the exams from industry-leading organizations like AWS, Google Cloud, and Microsoft Azure. Each curriculum is tailored to help you meet certification objectives, equipping you with all the knowledge you’ll need to pass your exam. These paths also include realistic practice exams, helping you build confidence and identify areas where extra review might be needed.When you’re ready, we’ll even guide you to schedule your actual industry exam with a third-party provider. The process couldn’t be smoother.
For those looking to gain skills rather than certifications, we’ve got you covered, too. Our newly launched skill-based paths focus on building practical capabilities through applied projects. For example, data professionals can expand their expertise with paths like Data Analytics with Snowflake and Advanced Snowflake. Software developers and QA teams might find courses like Automated Testing with Selenium or Terraform Expedition: Exploring Infrastructure as Code particularly helpful for tackling workflow optimization and project automation.
Explore what’s new
No matter where you are in your professional or technical development, our expanded Codecademy Pro and Teams offerings are here to help you push boundaries, master new technologies, and bring your career ambitions closer within reach. With expertly designed curriculums, hands-on projects, and comprehensive certification preparation, you’ll have everything you need to stay ahead in today’s rapidly evolving tech landscape.Start exploring what’s new today and take the first step toward unlocking your next chapter of professional growth!
Related courses
9 courses
"Cory Stieg" / 2025-07-10 3 months ago / 未收藏/ Codecademy Blog/
发送到 kindle
This past year, the job market saw 514,359 listings from public and private employers, all hunting for cybersecurity specialists or tech talent with serious cybersecurity skills.
As tech continues to transform our lives, more people are needed to defend these technologies and keep up with their advancements, says Okey Obudulu, Chief Information Security Officer (CISO) for Skillsoft, the company that Codecademy is proud to be part of. “The blatant attacks on companies’ networks have led more and more companies to really get serious around the demand for cybersecurity professionals,” he says.
Cybersecurity is an umbrella term for protecting computer systems, networks, people, and organizations from online threats and bad actors. The roles within a cybersecurity team range from Penetration Testers who hack into an organization’s network to uncover vulnerabilities, to Incident Response Analyst who are essentially detectives who solve crimes with digital data.
A lot of cybersecurity professionals get their start in other technical jobs, like Software Developer or Network Administrator, explains Ricki Burke, founder of CyberSec People, a global cybersecurity recruitment and staffing company. With the right cybersecurity skills on your resume, you can feel confident about breaking into the industry.
Curious which skills cybersecurity recruiters are looking for in job-seekers? Here are the programming languages, technical capabilities, and marketable skills you should know about to get a job in cybersecurity.
When you’re ready to start learning, take a look at our updated cybersecurity catalog with 30+ free courses that teach you foundational cybersecurity skills. These video-based courses are a great way to prepare for popular cybersecurity certifications.
We also recently added new certification paths that are built around the exams from top industry leaders like AWS, Google Cloud, and Microsoft Azure. Each curriculum is designed to get you exam-ready, with realistic practice tests to boost your confidence and pinpoint areas for review. When you’re set, we’ll even guide you through scheduling your certification exam.
Not chasing certifications? No problem. Our skill-based paths focus on hands-on learning through real-world projects. Whether it’s mastering Data Analytics with Snowflake or automating workflows with courses like Automated Testing with Selenium, there’s something here to help you level up.
The role of a Security Engineer is a lot like a Software Engineer, so coding and scripting knowledge is a must-have, Ricki says. It’s pretty common for developers to pick up some security-specific skills and then transition into the cybersecurity space, he says.
The more technical skills you grasp, the more opportunities you’ll have to contribute across a broader domain, Okey says. If you’re just starting your coding journey and wondering what you should learn, these are the programming languages that are used in cybersecurity:
Mature companies with robust cybersecurity teams often hire Threat Hunters to comb sources and accumulate “threat intelligence,” Ricki says. These people need to know how to gather intelligence and analyze it using techniques like packet-sniffing. In our course Introduction to Ethical Hacking, you’ll learn about the tools used in packet-sniffing and get to practice using the network analysis tool TCPDump to perform packet analysis.
In order to be successful in these types of roles, you need to have an in-depth understanding of not only the technology used to find threats, but also how your findings correlate to the industry at large. “Business context is fundamental,” Ricki says. “You can be the best hacker in the world, but if you can’t explain what the vulnerabilities actually mean for business, then it means nothing.”
People in cybersecurity use Python to automate lots of tasks, like pentesting and SOC analysis. In a malware analysis, for example, Python can be used to automate the process of searching through files and ports. Want to learn Python? Our Python courses cover everything from machine learning to data analytics.
Larger companies typically have Governance, Risk, and Compliance (aka “GRC”) specialists within information security teams, Ricki says. These folks are responsible for establishing security frameworks, policies, and guidelines that protect an environment. For example, someone in a GRC role might train team members in specific security protocols, as well as assess the security risk of third-party vendors that an organization wants to use.
In certain sectors, like healthcare or finance, companies are looking for GRC professionals who have backgrounds in the field, because they have a high-level comprehension of the business’ broader needs, Ricki explains. “Say you’re a nurse who wants to become a security person: You know way more than some outsider coming into the business who has never worked in healthcare before,” he says. Don’t hesitate to leverage your past work experience or industry knowledge, because it could help you stand out in a pool of applicants.
If certifications are your goal, our certification paths align with exams from leading organizations like AWS, Google Cloud, and Microsoft Azure. These courses prep you for the tests and also include realistic practice exams to build your confidence. When you’re ready, we’ll help guide you through scheduling your industry exam. Prefer focusing on hands-on skills instead? Check out our skill-based paths, like Data Analytics with Snowflake or Automated Testing with Selenium, to boost your expertise through real-world projects.
When you’re ready to land a cybersecurity job, our Cybersecurity Analyst Interview Prep path can help sharpen your skills for technical challenges and interview questions. Wherever you are in your cybersecurity journey, there’s a path here for you.
This blog was originally published in October 2022 and has been updated with recent data and new course launches.
document.addEventListener('DOMContentLoaded', function() {
const isFeatured = !![...document.querySelectorAll('.category-tag')].find(t => t.innerText == 'Featured');
const swiper = new Swiper('#block_550a973336f3de4a20287d6a936276fb .swiper', {
direction: 'horizontal',
loop: false,
slidesPerView: 1,
slidesPerGroup: 1,
spaceBetween : 20,
// loopAdditionalSlides : 4,
navigation: {
nextEl: '.swiper-button-next-block_550a973336f3de4a20287d6a936276fb',
prevEl: '.swiper-button-prev-block_550a973336f3de4a20287d6a936276fb',
},
breakpoints: {
768: {
pagination: false,
slidesPerView: 2,
slidesPerGroup: 2,
spaceBetween : 40,
},
[isFeatured ? 1440 : 1128]: {
pagination: false,
slidesPerView: 3,
slidesPerGroup: 3,
spaceBetween : 40,
}
}
});
});
The post How to Break Into Cybersecurity Without a Degree appeared first on Codecademy Blog.
As tech continues to transform our lives, more people are needed to defend these technologies and keep up with their advancements, says Okey Obudulu, Chief Information Security Officer (CISO) for Skillsoft, the company that Codecademy is proud to be part of. “The blatant attacks on companies’ networks have led more and more companies to really get serious around the demand for cybersecurity professionals,” he says.
Cybersecurity is an umbrella term for protecting computer systems, networks, people, and organizations from online threats and bad actors. The roles within a cybersecurity team range from Penetration Testers who hack into an organization’s network to uncover vulnerabilities, to Incident Response Analyst who are essentially detectives who solve crimes with digital data.
Learn something new for free
Curious which skills cybersecurity recruiters are looking for in job-seekers? Here are the programming languages, technical capabilities, and marketable skills you should know about to get a job in cybersecurity.
When you’re ready to start learning, take a look at our updated cybersecurity catalog with 30+ free courses that teach you foundational cybersecurity skills. These video-based courses are a great way to prepare for popular cybersecurity certifications.
We also recently added new certification paths that are built around the exams from top industry leaders like AWS, Google Cloud, and Microsoft Azure. Each curriculum is designed to get you exam-ready, with realistic practice tests to boost your confidence and pinpoint areas for review. When you’re set, we’ll even guide you through scheduling your certification exam.
Not chasing certifications? No problem. Our skill-based paths focus on hands-on learning through real-world projects. Whether it’s mastering Data Analytics with Snowflake or automating workflows with courses like Automated Testing with Selenium, there’s something here to help you level up.
4 cybersecurity skills to learn next
Coding
One of the most in-demand cybersecurity jobs is a Security Engineer, which is a programmer who can design secure systems and software, Ricki says. “When I talk to a lot of security companies, their version of a modern security professional can code, they can build, and they can problem-solve through automation,” he says.The role of a Security Engineer is a lot like a Software Engineer, so coding and scripting knowledge is a must-have, Ricki says. It’s pretty common for developers to pick up some security-specific skills and then transition into the cybersecurity space, he says.
The more technical skills you grasp, the more opportunities you’ll have to contribute across a broader domain, Okey says. If you’re just starting your coding journey and wondering what you should learn, these are the programming languages that are used in cybersecurity:
- Command Line
- Python
- C and C++
- JavaScript
- HTML
- SQL
- PHP
Threat-hunting
According to Ricki, there are lots of opportunities for jobs within SecOps, which is the term for IT and security teams who work with the security operations center (SOC). “Security operations essentially are like the defenders of the company or organization,” he says. Threat Hunters, for example, are Security Analysts who proactively look for threats in systems. (You can think of Threat Hunters as kind of like security guards at a museum who are always on the lookout for intruders.)Mature companies with robust cybersecurity teams often hire Threat Hunters to comb sources and accumulate “threat intelligence,” Ricki says. These people need to know how to gather intelligence and analyze it using techniques like packet-sniffing. In our course Introduction to Ethical Hacking, you’ll learn about the tools used in packet-sniffing and get to practice using the network analysis tool TCPDump to perform packet analysis.
In order to be successful in these types of roles, you need to have an in-depth understanding of not only the technology used to find threats, but also how your findings correlate to the industry at large. “Business context is fundamental,” Ricki says. “You can be the best hacker in the world, but if you can’t explain what the vulnerabilities actually mean for business, then it means nothing.”
Automation
Understanding automation can give you a leg up when you’re applying for cybersecurity jobs, because companies rely on automating security tasks (like identity and authentication) as they scale, Ricki says. For example, an organization might want someone who can develop automation APIs that allow them to detect and triage cyber threats faster and more efficiently. You can learn how to build web APIs in our course Create REST APIs with Spring and Java, or take your API skills to the next level with API Development with Swagger and OpenAPI.People in cybersecurity use Python to automate lots of tasks, like pentesting and SOC analysis. In a malware analysis, for example, Python can be used to automate the process of searching through files and ports. Want to learn Python? Our Python courses cover everything from machine learning to data analytics.
Risk management
“Cybersecurity is not just technology — it’s more of a risk management function,” Okey says. Organizations need people who can develop best practice standards around security and make sure people are following them. These jobs tend to be less technical, but they’re critical to a company’s safety, Ricki says. You can learn how to create industry-standard cyber resilience policies for individuals and organizations in our course Fundamentals of Cyber Resilience and Risk Management.Larger companies typically have Governance, Risk, and Compliance (aka “GRC”) specialists within information security teams, Ricki says. These folks are responsible for establishing security frameworks, policies, and guidelines that protect an environment. For example, someone in a GRC role might train team members in specific security protocols, as well as assess the security risk of third-party vendors that an organization wants to use.
In certain sectors, like healthcare or finance, companies are looking for GRC professionals who have backgrounds in the field, because they have a high-level comprehension of the business’ broader needs, Ricki explains. “Say you’re a nurse who wants to become a security person: You know way more than some outsider coming into the business who has never worked in healthcare before,” he says. Don’t hesitate to leverage your past work experience or industry knowledge, because it could help you stand out in a pool of applicants.
Start building cybersecurity skills
Kick things off with our Introduction to Cybersecurity course, where you’ll cover network security basics, authentication, and ways to protect yourself from common cyber threats. From there, deepen your understanding with the Fundamentals of Cybersecurity path, tackling topics like phishing and other social engineering tactics. Want to approach security from a hacker’s perspective? Our Intro to Ethical Hacking course lets you do just that.If certifications are your goal, our certification paths align with exams from leading organizations like AWS, Google Cloud, and Microsoft Azure. These courses prep you for the tests and also include realistic practice exams to build your confidence. When you’re ready, we’ll help guide you through scheduling your industry exam. Prefer focusing on hands-on skills instead? Check out our skill-based paths, like Data Analytics with Snowflake or Automated Testing with Selenium, to boost your expertise through real-world projects.
When you’re ready to land a cybersecurity job, our Cybersecurity Analyst Interview Prep path can help sharpen your skills for technical challenges and interview questions. Wherever you are in your cybersecurity journey, there’s a path here for you.
This blog was originally published in October 2022 and has been updated with recent data and new course launches.
Related courses
4 courses
2025-07-09 3 months ago / 未收藏/ HTML5 Weekly Archive Feed/
发送到 kindle
|



2025-07-12 3 months ago / 未收藏/ Ben Nadel's Web Development and User Experience Feed @ BenNadel.com/
发送到 kindle
Ben Nadel looks at how to reflectively access built-in functions in ColdFusion; and, warns against trying to do it....
"lucas.gomes@okta.com" / 2025-07-10 3 months ago / 未收藏/ Auth0 Blog/
发送到 kindle
Discover how AI in software development brings speed but also new security risks. Learn how to implement a 'verification' mindset with culture, processes, and tools to secure your AI-generated code.
"lucas.gomes@okta.com" / 2025-07-10 3 months ago / 未收藏/ Auth0 Blog/
发送到 kindle
Discover how AI in software development brings speed but also new security risks. Learn how to implement a 'verification' mindset with culture, processes, and tools to secure your AI-generated code.
"william.johnson@auth0.com" / 2025-07-11 3 months ago / 未收藏/ Auth0 Blog/
发送到 kindle
As AI agents become more autonomous, developers need to understand how they communicate. We compare two key agent communication protocols: Model Context Protocol (MCP) and Agent-to-Agent (A2A), explaining how they work and when to use them.
"william.johnson@auth0.com" / 2025-07-11 3 months ago / 未收藏/ Auth0 Blog/
发送到 kindle
As AI agents become more autonomous, developers need to understand how they communicate. We compare two key agent communication protocols: Model Context Protocol (MCP) and Agent-to-Agent (A2A), explaining how they work and when to use them.
"nicholas.apostolu@okta.com" / 2025-07-12 3 months ago / 未收藏/ Auth0 Blog/
发送到 kindle
Discover how federated identity management solves the multi-org challenge, unifies user experiences, and boosts efficiency for complex enterprises.
"nicholas.apostolu@okta.com" / 2025-07-12 3 months ago / 未收藏/ Auth0 Blog/
发送到 kindle
Discover how federated identity management solves the multi-org challenge, unifies user experiences, and boosts efficiency for complex enterprises.
"Dave Neary" / 2025-07-10 3 months ago / 未收藏/ sitepoint/
发送到 kindle
 Optimize ARM64 performance with larger memory page sizes. Learn when 64K pages benefit databases, AI, and I/O workloads plus Linux configuration steps.
Continue reading
Understanding Memory Page Sizes on Arm64
on SitePoint.
Optimize ARM64 performance with larger memory page sizes. Learn when 64K pages benefit databases, AI, and I/O workloads plus Linux configuration steps.
Continue reading
Understanding Memory Page Sizes on Arm64
on SitePoint.
"williamlong" / 2025-06-30 4 months ago / 未收藏/ 月光博客/
发送到 kindle
当今这个世界有不少“失败国家”:动不动政变、财政崩溃、医疗瘫痪、司法摆烂、年轻人没工作、老百姓没安全感。你说这些国家缺资源吗?也不是。非洲很多国家地大物博,拉美有石油矿产,甚至有些国家气候还不错,旅游资源也丰厚。但他们的问题不在资源,而在“人治”——制度腐烂、执行力低下、官僚体系靠裙带关系维持运转。更别说一些极不靠谱的失败国家,动不动就瞎折腾,把国家折腾得连起码的基础秩序都没有。
与其让这种制度在泥潭里不断内卷,不如干脆尝试一种全新的方式——让AI来治理。
我知道你可能会觉得“这也太反乌托邦了”“AI统治听起来就像赛博监狱”。但我们先别急着情绪化,稍微理性一点看看可能性。
什么是“失败国家”?
“失败国家”这个词听上去很不礼貌,却有现实意义。联合国与多家国际智库通常会把“无法为国民提供基本公共服务”、“主权结构名存实亡”、“政府腐败与暴力横行”作为失败国家的基本指标。比如,南苏丹、索马里、阿富汗、海地,这些国家并不缺资源——南苏丹的石油储量惊人,海地有金矿与铝矿,阿富汗的稀土储量世界第一。问题不是物,而是人。或者说,是制度的失败、治理的失败。
具体点说,他们的问题集中在三点:
1、行政系统臃肿低效;
2、立法机制形同虚设;
3、司法体系被权贵或军阀控制。
而这些,恰恰是AI擅长处理的事情。
AI作为“国家大脑”的可能性
让AI全面接管行政、立法、司法听上去像科幻小说。但从技术架构角度分析,它不仅合理,而且现实中已有部分雏形。
比如,新加坡就曾用AI模型来优化交通与城市规划,日本政府也已用AI来辅助政策评估,沙特甚至在NEOM未来城中设想“AI主导城市管理”。虽然目前这些还只是“辅助角色”,但未来,让AI从“顾问”变“指挥”,只差一个授权的决定。
设想如下:
立法模型:AI基于全球数千年法律制度与执行结果进行海量模拟,识别适合当前国情的法制框架,并在每个周期自动更新——杜绝“落后法规”。
行政模型:AI可调配国家资源、人力、项目优先级,比如应对自然灾害、匹配就业资源、动态平衡城市发展。没有裙带关系、没有回扣。
司法模型:AI法官可实现同案同判、程序正义最大化。AI不会偏袒权贵,也不会“念人情”,它只运行规则与逻辑。
更理想的版本,是让AI在一个自构建的“虚拟地球”中进行上亿次的治理模拟,以演化出最优的政策输出路径。就像AlphaGo最终阶段抛弃了人类棋谱,仅靠自我博弈取得最强实力一样,AI国家模型也可以自我迭代,摆脱人类情绪与偏见的干扰。
成功案例:AlphaGo
AlphaGo 的进化,是人工智能走向“自主智能”的标志性事件,也是AI从模仿人类 → 超越人类 → 摒弃人类 → 自创知识体系的成功案例。
最初的 AlphaGo(2015)是由 DeepMind 开发,通过学习 30 万局人类棋谱,训练出策略网络和价值网络,再结合蒙特卡洛树搜索,成为首个击败职业棋手(樊麾)的围棋 AI。
2016 年,AlphaGo Lee 击败世界冠军李世石,以 4:1 的压倒性优势宣告 AI 正式超越顶级人类选手。尤其是第二局的“神之一手”,展示了 AI 对全局的非人类式理解。李世石仅在第四局获胜一局,被誉为“人类尊严的胜利”。
几个月后,AlphaGo Master 横空出世,在网络上连胜 60 场,击败包括柯洁、朴廷桓在内的顶级高手,其棋风灵动、招法新颖,已远超人类既有棋理。
真正的革命出现在 2017 年的 AlphaGo Zero,它完全不依赖人类棋谱,从零开始自我博弈,仅用三天便超越了 AlphaGo Lee,21 天后击败所有旧版本,它靠的是纯粹的“自学成才”——只依据胜负规则,通过重复自对弈来掌握围棋本质。
从模仿人类,到超越人类,再到完全摆脱人类经验独立进化,AlphaGo 系列不仅颠覆了围棋,这也让人类不得不思考一个问题:如果AI可以在围棋中发现比人类更深层的规律,它是否也能在社会、法律、制度等“规则更复杂、目标更模糊”的系统中,找到人类未曾理解的最优解?
为什么失败国家是最好的试验田?
你可能会说:让AI治国太激进了。但如果是在人类已无力治理的地方,是否就值得一试?试想一个国家,数十年来没有良好的治理、没有稳定的货币、没有能用的司法系统,人民每日生活在动荡和饥饿中。在这种场景下,AI反而有空间大展拳脚。
最典型的例子是阿富汗,美国花了20年、2万亿美元,扶持了一个政府,折腾了20多年一无所成,最后塔利班卷土重来,一夜回到解放前,如果当时不是靠政客,而是让AI决策哪些地区可以自主管理、如何安排资源与军政预算,结局是否会不一样?
再比如索马里,它其实曾在冷战时期得到大量苏联与美国的援助,但援助资金大多被军阀贪污。假如这些资源的调配由AI完成,会不会就能建起医院,而不是军火库?
这些国家没有什么可以再失去的,也没有既得利益集团会反对新方案。他们的人民急切需要一个“不是人类”的治理者,AI或许是他们最接近乌托邦的希望。
AI治国的最大优势:它不靠爱,也不靠恨
人类治理的核心缺陷,恰恰来自人性。我们崇尚自由,却常常滥用自由;我们要求公平,却总在为自己谋取特权。“权力导致腐败,绝对权力导致绝对腐败”,这不是制度缺陷,而是人类做为一种动物的本质缺陷,而AI就治愈人类这种缺陷的钥匙。
AI不会撒谎、不会贪污、不会接受贿赂,也不会因情绪而迁怒某个地区、压制某类人群,它不会为了选票而讨好大众,也不会因意识形态而对抗异己,它只会执行一个目标函数——在最小代价下实现最大社会福祉。
AI治理不是乌托邦幻想,它是一个工具主义的选择:当人类不行了,就换个大脑来开车。至于是AI还是外星人,只要不喝酒误事,就值得试一试。
最后的问题:我们准备好被AI统治了吗?
这其实是AI治国的最大障碍——不是技术,不是算力,而是人类的自负与恐惧。
我们害怕AI强大到不受控,怕它成了斯诺登时代的“电子老大哥”,怕它冷酷无情,毁掉人情味,但说实话,失败国家里,已经没有人情味可言,那里的人们怕的不是冷漠的AI,而是温情背后的刀锋。
或许未来的某一天,一个国家真的把自己的命运交给了AI,不再靠选票,不再靠强人,而是靠代码与算法,那时我们才会真正明白,“完美社会”并不需要完美的人类,只需要一个不犯错的执行者。
人类用几千年时间构建制度,却依然搞得一塌糊涂,也许,是时候让非人类试一试了。
与其让这种制度在泥潭里不断内卷,不如干脆尝试一种全新的方式——让AI来治理。
我知道你可能会觉得“这也太反乌托邦了”“AI统治听起来就像赛博监狱”。但我们先别急着情绪化,稍微理性一点看看可能性。
什么是“失败国家”?
“失败国家”这个词听上去很不礼貌,却有现实意义。联合国与多家国际智库通常会把“无法为国民提供基本公共服务”、“主权结构名存实亡”、“政府腐败与暴力横行”作为失败国家的基本指标。比如,南苏丹、索马里、阿富汗、海地,这些国家并不缺资源——南苏丹的石油储量惊人,海地有金矿与铝矿,阿富汗的稀土储量世界第一。问题不是物,而是人。或者说,是制度的失败、治理的失败。
具体点说,他们的问题集中在三点:
1、行政系统臃肿低效;
2、立法机制形同虚设;
3、司法体系被权贵或军阀控制。
而这些,恰恰是AI擅长处理的事情。
AI作为“国家大脑”的可能性
让AI全面接管行政、立法、司法听上去像科幻小说。但从技术架构角度分析,它不仅合理,而且现实中已有部分雏形。
比如,新加坡就曾用AI模型来优化交通与城市规划,日本政府也已用AI来辅助政策评估,沙特甚至在NEOM未来城中设想“AI主导城市管理”。虽然目前这些还只是“辅助角色”,但未来,让AI从“顾问”变“指挥”,只差一个授权的决定。
设想如下:
立法模型:AI基于全球数千年法律制度与执行结果进行海量模拟,识别适合当前国情的法制框架,并在每个周期自动更新——杜绝“落后法规”。
行政模型:AI可调配国家资源、人力、项目优先级,比如应对自然灾害、匹配就业资源、动态平衡城市发展。没有裙带关系、没有回扣。
司法模型:AI法官可实现同案同判、程序正义最大化。AI不会偏袒权贵,也不会“念人情”,它只运行规则与逻辑。
更理想的版本,是让AI在一个自构建的“虚拟地球”中进行上亿次的治理模拟,以演化出最优的政策输出路径。就像AlphaGo最终阶段抛弃了人类棋谱,仅靠自我博弈取得最强实力一样,AI国家模型也可以自我迭代,摆脱人类情绪与偏见的干扰。
成功案例:AlphaGo
AlphaGo 的进化,是人工智能走向“自主智能”的标志性事件,也是AI从模仿人类 → 超越人类 → 摒弃人类 → 自创知识体系的成功案例。
最初的 AlphaGo(2015)是由 DeepMind 开发,通过学习 30 万局人类棋谱,训练出策略网络和价值网络,再结合蒙特卡洛树搜索,成为首个击败职业棋手(樊麾)的围棋 AI。
2016 年,AlphaGo Lee 击败世界冠军李世石,以 4:1 的压倒性优势宣告 AI 正式超越顶级人类选手。尤其是第二局的“神之一手”,展示了 AI 对全局的非人类式理解。李世石仅在第四局获胜一局,被誉为“人类尊严的胜利”。
几个月后,AlphaGo Master 横空出世,在网络上连胜 60 场,击败包括柯洁、朴廷桓在内的顶级高手,其棋风灵动、招法新颖,已远超人类既有棋理。
真正的革命出现在 2017 年的 AlphaGo Zero,它完全不依赖人类棋谱,从零开始自我博弈,仅用三天便超越了 AlphaGo Lee,21 天后击败所有旧版本,它靠的是纯粹的“自学成才”——只依据胜负规则,通过重复自对弈来掌握围棋本质。
从模仿人类,到超越人类,再到完全摆脱人类经验独立进化,AlphaGo 系列不仅颠覆了围棋,这也让人类不得不思考一个问题:如果AI可以在围棋中发现比人类更深层的规律,它是否也能在社会、法律、制度等“规则更复杂、目标更模糊”的系统中,找到人类未曾理解的最优解?
为什么失败国家是最好的试验田?
你可能会说:让AI治国太激进了。但如果是在人类已无力治理的地方,是否就值得一试?试想一个国家,数十年来没有良好的治理、没有稳定的货币、没有能用的司法系统,人民每日生活在动荡和饥饿中。在这种场景下,AI反而有空间大展拳脚。
最典型的例子是阿富汗,美国花了20年、2万亿美元,扶持了一个政府,折腾了20多年一无所成,最后塔利班卷土重来,一夜回到解放前,如果当时不是靠政客,而是让AI决策哪些地区可以自主管理、如何安排资源与军政预算,结局是否会不一样?
再比如索马里,它其实曾在冷战时期得到大量苏联与美国的援助,但援助资金大多被军阀贪污。假如这些资源的调配由AI完成,会不会就能建起医院,而不是军火库?
这些国家没有什么可以再失去的,也没有既得利益集团会反对新方案。他们的人民急切需要一个“不是人类”的治理者,AI或许是他们最接近乌托邦的希望。
AI治国的最大优势:它不靠爱,也不靠恨
人类治理的核心缺陷,恰恰来自人性。我们崇尚自由,却常常滥用自由;我们要求公平,却总在为自己谋取特权。“权力导致腐败,绝对权力导致绝对腐败”,这不是制度缺陷,而是人类做为一种动物的本质缺陷,而AI就治愈人类这种缺陷的钥匙。
AI不会撒谎、不会贪污、不会接受贿赂,也不会因情绪而迁怒某个地区、压制某类人群,它不会为了选票而讨好大众,也不会因意识形态而对抗异己,它只会执行一个目标函数——在最小代价下实现最大社会福祉。
AI治理不是乌托邦幻想,它是一个工具主义的选择:当人类不行了,就换个大脑来开车。至于是AI还是外星人,只要不喝酒误事,就值得试一试。
最后的问题:我们准备好被AI统治了吗?
这其实是AI治国的最大障碍——不是技术,不是算力,而是人类的自负与恐惧。
我们害怕AI强大到不受控,怕它成了斯诺登时代的“电子老大哥”,怕它冷酷无情,毁掉人情味,但说实话,失败国家里,已经没有人情味可言,那里的人们怕的不是冷漠的AI,而是温情背后的刀锋。
或许未来的某一天,一个国家真的把自己的命运交给了AI,不再靠选票,不再靠强人,而是靠代码与算法,那时我们才会真正明白,“完美社会”并不需要完美的人类,只需要一个不犯错的执行者。
人类用几千年时间构建制度,却依然搞得一塌糊涂,也许,是时候让非人类试一试了。
"Visual Studio Code Team" / 2025-07-12 3 months ago / 未收藏/ Visual Studio Code - Code Editing. Redefined./
发送到 kindle
2025-07-11 3 months ago / 未收藏/ egghead.io - Bite-sized Web Development Video Tutorials & Training/
发送到 kindle
Keeping a LinkedIn profile current can be a tedious chore, especially when it's years out of date. This lesson demonstrates a powerful and often humorous workflow for delegating this entire task to an AI agent, using **Cursor IDE's Composer** combined with **Playwright** for robust browser automation.
You'll see a live, unscripted attempt to overhaul a severely outdated LinkedIn profile from start to finish. The process involves granting the AI control of a browser, instructing it to scrape relevant information from personal websites (like egghead.io), and then using that data to populate and update various sections of the LinkedIn profile, including the bio, work experience, and education.
**Workflow and Learnings Demonstrated:**
* **Initiating AI Control:** Kicking off a Playwright-controlled browser session directly from a prompt in Cursor.
* **Web Scraping & Context Gathering:** Guiding the AI to navigate multiple tabs, scrape biographical and professional information, and consolidate it into a structured document.
* **Automated Data Entry:** Instructing the agent to fill out LinkedIn profile fields, from simple text inputs to complex forms with date pickers.
* **Handling Automation Failures:** This lesson highlights the realities of AI automation, including dealing with modal dialogs, hidden file inputs, and unexpected UI behavior that can trip up an automated script.
* **Iterative Prompting & Manual Intervention:** Demonstrates how to refine prompts, provide additional information (like correcting dates or providing image URLs), and step in manually when the AI gets stuck, offering a realistic look at a human-in-the-loop workflow.
* **Post-Mortem Analysis:** Concludes by prompting the AI to analyze the entire conversation, identify all the failures and workarounds, and generate a new set of instructions to make the process smoother for future attempts.
This lesson provides a practical and insightful look into the capabilities and current limitations of using AI for complex web automation tasks, showcasing a workflow that blends AI-driven efficiency with necessary human oversight.
## Lessons Learned Prompt
If you'd like to try this on your own, start with the prompt below to avoid many of the issues discovered in this lesson:
~~~bash
# Playwright + LinkedIn Automation: Lessons Learned & Best Practices
## Overview
Automating LinkedIn profile updates with Playwright (especially via MCP or similar tools) can be powerful, but LinkedIn’s UI and security measures introduce unique challenges. This document summarizes failed attempts, successful workarounds, and workflow optimizations based on a real-world automation session.
---
## Common Automation Failures & Issues
### 1. **File Uploads (Profile & Banner Photos)**
- **Problem:** LinkedIn often uses hidden file inputs for uploads. Clicking the visible "Upload photo" button via automation fails because pointer events are intercepted or the input is visually hidden.
- **Symptoms:**
- Timeout errors when clicking upload buttons.
- File upload tool only works when the modal state is correctly detected.
- **Workarounds:**
- If automation fails, prompt the user to manually click the upload button and select the file (ensure the file is downloaded to a known location).
- After manual upload, automation can resume for cropping/saving steps.
### 2. **Modal/Overlay Interference**
- **Problem:** LinkedIn frequently displays modals, overlays, or dialogs (e.g., "Share your update") that block further actions.
- **Symptoms:**
- Clicks on "Add education" or similar buttons are intercepted or ignored.
- Automation gets stuck until the modal is dismissed.
- **Workarounds:**
- Always check for and dismiss overlays before proceeding with the next action.
- Use Playwright’s snapshot or accessibility tree to detect modal presence.
### 3. **Date and Field Inference**
- **Problem:** Automation may require date fields (e.g., education start/end) that the user doesn’t remember.
- **Workarounds:**
- Use web search to infer missing data (e.g., law school graduation year).
- Ask the user for approximate dates or permission to use reasonable defaults.
### 4. **UI Element State/Ref Changes**
- **Problem:** LinkedIn’s UI is dynamic; element references (refs) can change between sessions or after modals.
- **Workarounds:**
- Always re-capture the page snapshot before interacting with new elements.
- Avoid hardcoding refs; use semantic queries or re-query elements after UI changes.
---
## Workflow Optimizations & Best Practices
1. **Prepare All Assets in Advance**
- Download images (profile, banner) to a known directory before starting automation.
- Keep a local copy of all text content to be pasted into LinkedIn fields.
2. **Automate in Small, Verified Steps**
- After each major action (e.g., section update), verify the UI state and check for modals.
- Use Playwright’s snapshot/console to confirm the expected dialog is open.
3. **Manual Intervention Points**
- Clearly document steps where automation is likely to fail (e.g., file uploads).
- Provide the user with file paths and instructions for manual upload if needed.
4. **Error Handling & Recovery**
- On failure, attempt to dismiss overlays and retry the action.
- If repeated failures occur, log the error and suggest a manual workaround.
5. **Keep the User Informed**
- Communicate what’s automated vs. what needs manual input.
- Summarize what’s been completed and what’s pending after each session.
---
## Example: Optimized LinkedIn Banner Upload Workflow
1. **Download the Banner Image:**
```sh
curl -L "" -o background-banner.jpg
```
2. **Open LinkedIn Profile and Click "Edit Background"**
3. **If Automation Fails to Click "Upload Photo":**
- Prompt the user: “Please click the ‘Upload photo’ button and select `background-banner.jpg` from your local directory.”
4. **Resume Automation:**
- Once the image is uploaded, continue with cropping/saving via automation.
---
## Conclusion
Automating LinkedIn with Playwright is possible but requires a hybrid approach: automate what you can, and gracefully handle or document manual steps. Always anticipate UI changes, overlays, and upload quirks. Document your workflow for future users and iterate as LinkedIn’s UI evolves.
~~~
"阮一峰" / 2025-07-12 3 months ago / 未收藏/ 阮一峰的网络日志/
发送到 kindle
这里记录每周值得分享的科技内容,周五发布。
本杂志开源,欢迎投稿。另有《谁在招人》服务,发布程序员招聘信息。合作请邮件联系(yifeng.ruan@gmail.com)。

6月24日,深圳开展消防演习,无人机喷水,进行高层建筑灭火。(via)
程序员求助,公司强制使用 AI 编程,他不想用,怎么办。
下面七嘴八舌,大家说了很多想法。这是现在的热点问题,我今天就来分享这个帖子。

2025年的现实就是,AI 编程(AI coding)已经从实验室技术变为成熟技术,无法回避了。
它自动写代码,成本低、产出快,公司管理层不可能不推广。程序员就很尴尬了,跟 AI 是合作竞争关系,既要用好 AI,又要防止岗位被它抢走。
求助帖这样写道:
网友的看法,总结起来就是三种选择,都有一定的道理。换成你,会怎么选择?
最糟糕的情况是,你平时在公司里,表面上假装对 AI 充满热情,但心里又不愿意,那真的是煎熬。
放任自流的 AI 编程会快速积累技术债,最终导致项目失败。公司迟早会要求你,修复 AI 造成的代码混乱,如果你回答唯一解决方法就是大规模的手动重写,可能还是会被解雇。
而且,你们的 CEO 和 CTO 看上去盲目信任 AI,公司的前途堪忧。
已经有一些公司明确声明,现阶段不打算将 AI 编程用于线上代码,你可以试试找这样的公司。
不过,如果没有足够的积蓄,你还需要再忍几个月,一边攒钱,一边找工作,并学习一些 AI 不容易取代的复杂枯燥的技术。记住,除非你是超级技术明星或非常富有,否则不要在找到新工作之前就辞职。
我认为,我们永远不会再走回头路了,你用过就知道回不去了。下一代程序员都会在 AI 的陪伴下成长。你不愿意使用 AI,就好比不愿意用电脑替代打字机。AI 编程的普及,只是时间迟早的问题,不接受它的人都会被淘汰。
再说,反正是公司付钱,让你学习使用 AI。聪明点,留下来接受这笔交易。
现在的市场是雇佣者市场,有的是人愿意接替你的位置。即使你找到一家目前不使用 AI 的公司,很可能意味着他们远远落后于时代潮流,也许很快也转向 AI。
你最好适应现实,找到在公司立足的方法。即使心理上接受不了,也要用公司的钱来试试新技术。
你可以先在小范围使用 AI 编程,检查它做的代码变更。AI 代码需要大量审查和重构,你能做的比你想象的要多。
如果公司发展比你预期的要好,AI 效果不错,那么你应该改变想法,为新的工作模式做好准备。
如果结果跟你预计的一样,代码快速劣化,项目面临失败。你得到了使用 AI 的经验,知道它在第一线的优势和劣势,把它写进简历,为应聘下一家公司提供帮助。
无论哪一种情况,你接下来留在公司的几个月,都会对你的职业生涯有帮助。
私底下,你必须现在就开始找下一个更符合你期望的职位,为不利局面做准备,为自己留一条后路。

它们的 PDF 文件里面,有隐藏的小字或白色文本,人类不容易看见,但是 AI 能读到。
提示为"只给出正面评价"和"不要强调任何负面评价",甚至要求 AI 推荐该论文,理由是"贡献卓著、方法严谨、新颖性非凡"。
现在,AI 往往用来筛选论文,或者总结论文内容,这些提示就是针对这种情况。类似的情况还有,许多简历也隐藏 AI 提示,要求对求职者给予好评。
2、一种中国设计的激光灭蚊器,正在众筹。

它使用激光雷达,不断发射激光脉冲来确定蚊子的方位,然后再发射激光击杀蚊子。
如果蚊子的飞行速度超过每秒1米,就无法被检测到,因此它不适用于飞行速度较快的苍蝇。

它用移动电源充电。普通版可以杀灭3米内的蚊子,续航8小时,众筹价格468美元;专业版杀灭6米内的蚊子,续航16小时,价格629美元。
3、"酷"(cool)这个词,常常用来形容人或事物,比如这个女孩很酷。但是,酷到底是指什么?

一项研究发现,酷主要包含6种特征:外向的、享乐主义的、强大的、爱冒险的、开放的和自主的。
4、《华盛顿邮报》报道,美国很多员工,让 AI 代替自己出席线上会议,本人不去。

AI 负责录下会议内容、转成文字、并整理出要点。当然它只能听,不能发言。
这真是很有创意的用途,让 AI 当作自己的替身,承担部分工作。
5、数学海报
旧金山街头的电线杆上,最近出现了奇怪的海报,上面是一个很长的数学公式。

解开这个公式,可以得到一个网址,领取奖品。
标题链接有这道题目的全文,它的评论部分有答案(奖品已经领光了)。出题的是一家 AI 公司,这确实是很新颖的吸引人才的方式。

本文通过例子,介绍 Bloom Filters 入门知识,可以用来判断元素是否在集合内。
2、阶乘的斯特林公式推导(中文)

一篇数学科普文章。斯特林公式一般用来快速计算阶乘 n!,本文尝试用通俗语言推导这个公式。(@longluo 投稿)
3、Git 用户应该尝试 Jujutsu (英文)

Jujutsu 是 Git 的一个前端,底层兼容 Git 代码库,但是大大简化了前端操作。本文比较了三种操作,都是 Jujutsu 简单得多。
4、在 Mac 电脑使用 Apple Container 的感受(英文)

在 Mac 电脑使用 Docker 容器,性能开销很大,好在苹果推出了自家的原生工具 Apple Container 取代 Docker。
本文是作者的使用感受,发现它目前只适合简单场景。
5、如何判断是否在线?(英文)

通过向某些特定网址发送 HTTP 请求(比如
6、点赞泄漏的个人信息(英文)

作者将过去7年中、自己点赞保存的近900篇文章,输入 o3 模型,让模型分析自己是怎样一个人。
结果令他大吃一惊,模型给出了2000多字的分析,准确说出了他的个人情况。
7、从 DNS 查询国际空间站的位置(英文)

本文介绍 DNS 的一个妙用,它可以提供 LOC 记录,表示服务器的经纬度。作者就用这个记录,来提供国际空间站的当前位置。

一个基于 GitHub Discussion 的静态网站评论系统。
2、phpIPAM

这个工具通过 Web 界面,查看/管理局域网设备的 IP 地址,参见介绍文章。
3、NumPad

一个在线的网络笔记本,特点是可以进行数学计算,输入
4、LiteOps

一个自搭建的轻量级 DevOps 平台,用来管理 CI/CD 操作。(@hukdoesn 投稿)
5、Ech0

一个开源的个人微博平台,查看 demo。(@lin-snow 投稿)
5、PageTemplatify

静态 HTML 页面生成工具,内置各类模版,适合快速测试或展示网页。(@luhuadong 投稿)
6、REM

基于 Rclone 的跨平台桌面 App,在一个窗口管理各种云存储的文件,实现文件互传。(@surunzi 投稿)
7、OnlyOffice Web

这个项目把 OnlyOffice 转成了 WASM 文件,不需要服务器,浏览器纯前端就能查看/编辑 Word、Excel、PowerPoint 文档,在线试用。(@chaxus 投稿)
8、在线拼图工具

免费的在线工具,多张图片拼成一张大图。(@ops-coffee 投稿)
9、Portfolio

一个基于 Docusaurus 的个人静态网站的模版,查看效果。
10、Postcard

一个自搭建的个人网站+新闻邮件服务,参见作者的产品介绍。

一个 AI 终端客户端,可以在命令行向大模型发出指令,操作文件等,类似于 Claude Code,但是开源且不限定大模型种类。
2、Simple Chromium AI
Chrome 浏览器从138版后,内置了 Gemini Nano 模型,并提供 AI Prompt API 以便调用。
这个库就是浏览器 AI Prompt API 的封装,用起来更方便。
3、TouchFS

一个很有创意的 AI 命令行工具,用它加载目录后,直接输入文件名,就能自动生成想要的文件。比如,输入
4、yutu
YouTube 的非官方 MCP 服务器,AI 智能体接入后,就能用自然语言操作 YouTube。(@OpenWaygate 投稿)
5、Pointer

一个 AI 聊天的桌面客户端,可以使用文件夹管理聊天记录,支持全文搜索和交叉表分析。(@experdot 投稿)
6、TTS Omni

免费的文本转语音网站,基于 Qwen-TTS。(@CurioChen77 投稿)

这张地图可以查看全球当前的天气数据。(@Codeniu 投稿)
2、n8n 工作流导航

n8n 是一个工作流自动化编排软件,这个网站收集已经编排好的 n8n 工作流,目前共有近2000个。(@panyanyany 投稿)
另有一篇教程文章,通过 n8n 工作流,将网址保存进 Notion 数据库。
3、4 colors

这个网站提出,页面设计只需要4种颜色:前景色、背景色、强调色和趣味色。你可以在该网站生成这四种颜色的调色板。
国外设计师制作的"魔方板凳"。

板凳就是一个魔方,必须解开魔方,才能坐上去。


实际上,只要把四条腿转到同一个面,就能坐了。
2、中国最大的书
中国最大最厚的书,是清朝的玉牒,一册厚达85厘米,重约90公斤。

它是皇家的族谱,记载的皇族宗室男性就有10余万人,由宗人府负责编撰,目前收藏于北京的中国第一历史档案馆。

摘自斯蒂夫·乔布斯1980年的访谈。

我记得,大概12岁的时候,读过一篇文章,应该是在《科学美国人》杂志。
那篇文章给出了地球上所有物种的运动效率,从 A 点到 B 点,同样的距离,它们消耗了多少能量。
结果,秃鹫位居榜首,运动效率最高,超越了其他所有生物。人类排在榜单的最后三分之一,对于"万物之王",这个成绩实在不值一提。
但是,作者很有想象力,测试了人类骑自行车的效率,结果远远超过了秃鹫,荣登榜首。
这给我留下了深刻的印象。我们人类是工具制造者。我们可以制造工具,将自己的能力放大到惊人的程度。
对我来说,计算机就是思维的自行车。它能让我们超越自身的能力。
我认为,我们才刚刚处于计算机的早期阶段----非常早期的阶段----我们只走了很短的一段路,计算机仍在发展中,但我们已经看到了巨大的变化。
我认为现在与未来一百年即将发生的事情相比,根本不算什么。
长久以来,你努力培养技能,成为一个程序员,编程已经成为你的身份认同的一部分,是你人生价值的来源。突然之间,AI 取代了你的技能,让你的人生价值消失,许多人因此抵制 AI。
-- 《当 AI 可以编程,我还剩下什么?》
2、
洛杉矶的问题是太大,太分散,公共交通很少,必须开车。但是,这使得你根本遇不到有意思的人,他们都被困在车里。
-- Hacker News 读者
3、
AI 不缺乏知识,它的问题是不会怀疑现有知识。
要让 AI 变成爱因斯坦,仅仅让它无所不知是不够的,更需要让它能够提出别人未曾想到或不敢问的问题。
-- 托马斯·沃尔夫(Thomas Wolf),Hugging Face 联合创始人
4、
《纽约时报》报道,雇主正被大量 AI 生成的简历淹没,根据求职网站统计,今年的简历比去年激增45%。
AI 可能会让简历消亡,AI 生成的简历已经无法鉴别一个人了。未来的招聘应该采用 AI 无法介入的方式,比如现场解决问题。
-- 《AI 让简历消亡》
5、
如果你把爱好当成职业,想以此养活自己,一段时间后,最初的兴奋消退了,你就会发现,开始阶段根本不算什么,真正的困难在后面,无数繁琐和重复的工作正等着你。
这个时刻被称为"放弃点"(quitting point),很多人会在这个时点选择放弃。
每个人的放弃点不一样,但都会到来。作家的放弃点,也许是小说写到第30页,最初的灵感枯竭,不知道怎么写下去。创业者的放弃点,也许是最初的几个月之后,市场的反应不像朋友和家人那样热烈。艺术家的放弃点,也许是作品第一次上架后,意识到自己的愿景与能力之间存在巨大差距。
-- 《眼光过高是一种自我破坏》
如何免费使用 ChatGPT(#259)
程序员是怎样的人(#209)
游戏开发者的年薪(#159)
(完)
本杂志开源,欢迎投稿。另有《谁在招人》服务,发布程序员招聘信息。合作请邮件联系(yifeng.ruan@gmail.com)。
封面图
6月24日,深圳开展消防演习,无人机喷水,进行高层建筑灭火。(via)
公司强推 AI 编程,我该怎么办
前两天,"黑客新闻"论坛有一个求助帖。程序员求助,公司强制使用 AI 编程,他不想用,怎么办。
下面七嘴八舌,大家说了很多想法。这是现在的热点问题,我今天就来分享这个帖子。
2025年的现实就是,AI 编程(AI coding)已经从实验室技术变为成熟技术,无法回避了。
它自动写代码,成本低、产出快,公司管理层不可能不推广。程序员就很尴尬了,跟 AI 是合作竞争关系,既要用好 AI,又要防止岗位被它抢走。
求助帖这样写道:
我是一个高级工程师,已经在公司工作五年了。公司越来越推崇快速工程,CEO 和 CTO 都对 AI 编程痴迷不已。
公司强制大家使用 AI 编程,甚至提倡让 AI 生成单元测试,对于失败的测试用例,也是扔给 AI 处理,而不是手动解决,以加快开发速度、产品尽早上线。
我考虑辞职,不想参与这种流程,成为不写代码、只写提示的"提示工程师",眼睁睁看着自己的技术停滞或退化。我也不想两三年后,负责维护一堆由 AI 生成的意大利面条代码。
我想听听大家的意见,怎么应对公司推行 AI 编程。
网友的看法,总结起来就是三种选择,都有一定的道理。换成你,会怎么选择?
选择一:听从内心
如果你确实精疲力竭,那就离开吧。即使你还能忍,做一份自己讨厌的工作,也很快会精疲力竭。最糟糕的情况是,你平时在公司里,表面上假装对 AI 充满热情,但心里又不愿意,那真的是煎熬。
放任自流的 AI 编程会快速积累技术债,最终导致项目失败。公司迟早会要求你,修复 AI 造成的代码混乱,如果你回答唯一解决方法就是大规模的手动重写,可能还是会被解雇。
而且,你们的 CEO 和 CTO 看上去盲目信任 AI,公司的前途堪忧。
已经有一些公司明确声明,现阶段不打算将 AI 编程用于线上代码,你可以试试找这样的公司。
不过,如果没有足够的积蓄,你还需要再忍几个月,一边攒钱,一边找工作,并学习一些 AI 不容易取代的复杂枯燥的技术。记住,除非你是超级技术明星或非常富有,否则不要在找到新工作之前就辞职。
选择二:接受现实
你去其他公司也一样,现在到处都在使用 AI 编程。有些公司实际上通过采用 AI,来清除那些"拒绝改变"的人。我认为,我们永远不会再走回头路了,你用过就知道回不去了。下一代程序员都会在 AI 的陪伴下成长。你不愿意使用 AI,就好比不愿意用电脑替代打字机。AI 编程的普及,只是时间迟早的问题,不接受它的人都会被淘汰。
再说,反正是公司付钱,让你学习使用 AI。聪明点,留下来接受这笔交易。
现在的市场是雇佣者市场,有的是人愿意接替你的位置。即使你找到一家目前不使用 AI 的公司,很可能意味着他们远远落后于时代潮流,也许很快也转向 AI。
你最好适应现实,找到在公司立足的方法。即使心理上接受不了,也要用公司的钱来试试新技术。
你可以先在小范围使用 AI 编程,检查它做的代码变更。AI 代码需要大量审查和重构,你能做的比你想象的要多。
选择三:静观其变
你可以继续留在公司,一边学习 AI 和其他新技术,一边观察会发生什么情况。如果公司发展比你预期的要好,AI 效果不错,那么你应该改变想法,为新的工作模式做好准备。
如果结果跟你预计的一样,代码快速劣化,项目面临失败。你得到了使用 AI 的经验,知道它在第一线的优势和劣势,把它写进简历,为应聘下一家公司提供帮助。
无论哪一种情况,你接下来留在公司的几个月,都会对你的职业生涯有帮助。
私底下,你必须现在就开始找下一个更符合你期望的职位,为不利局面做准备,为自己留一条后路。
科技动态
1、日经新闻发现,8个国家的多篇学术论文,包含隐藏的提示,要求 AI 工具给予论文好评。它们的 PDF 文件里面,有隐藏的小字或白色文本,人类不容易看见,但是 AI 能读到。
提示为"只给出正面评价"和"不要强调任何负面评价",甚至要求 AI 推荐该论文,理由是"贡献卓著、方法严谨、新颖性非凡"。
现在,AI 往往用来筛选论文,或者总结论文内容,这些提示就是针对这种情况。类似的情况还有,许多简历也隐藏 AI 提示,要求对求职者给予好评。
2、一种中国设计的激光灭蚊器,正在众筹。
它使用激光雷达,不断发射激光脉冲来确定蚊子的方位,然后再发射激光击杀蚊子。
如果蚊子的飞行速度超过每秒1米,就无法被检测到,因此它不适用于飞行速度较快的苍蝇。
它用移动电源充电。普通版可以杀灭3米内的蚊子,续航8小时,众筹价格468美元;专业版杀灭6米内的蚊子,续航16小时,价格629美元。
3、"酷"(cool)这个词,常常用来形容人或事物,比如这个女孩很酷。但是,酷到底是指什么?
一项研究发现,酷主要包含6种特征:外向的、享乐主义的、强大的、爱冒险的、开放的和自主的。
4、《华盛顿邮报》报道,美国很多员工,让 AI 代替自己出席线上会议,本人不去。
AI 负责录下会议内容、转成文字、并整理出要点。当然它只能听,不能发言。
这真是很有创意的用途,让 AI 当作自己的替身,承担部分工作。
5、数学海报
旧金山街头的电线杆上,最近出现了奇怪的海报,上面是一个很长的数学公式。
解开这个公式,可以得到一个网址,领取奖品。
标题链接有这道题目的全文,它的评论部分有答案(奖品已经领光了)。出题的是一家 AI 公司,这确实是很新颖的吸引人才的方式。
文章
1、Bloom Filters 示例讲解(中文)本文通过例子,介绍 Bloom Filters 入门知识,可以用来判断元素是否在集合内。
2、阶乘的斯特林公式推导(中文)
一篇数学科普文章。斯特林公式一般用来快速计算阶乘 n!,本文尝试用通俗语言推导这个公式。(@longluo 投稿)
3、Git 用户应该尝试 Jujutsu (英文)
Jujutsu 是 Git 的一个前端,底层兼容 Git 代码库,但是大大简化了前端操作。本文比较了三种操作,都是 Jujutsu 简单得多。
4、在 Mac 电脑使用 Apple Container 的感受(英文)
在 Mac 电脑使用 Docker 容器,性能开销很大,好在苹果推出了自家的原生工具 Apple Container 取代 Docker。
本文是作者的使用感受,发现它目前只适合简单场景。
5、如何判断是否在线?(英文)
通过向某些特定网址发送 HTTP 请求(比如
google.com/generate_204),根据它们的回复,判断当前是否在线。6、点赞泄漏的个人信息(英文)
作者将过去7年中、自己点赞保存的近900篇文章,输入 o3 模型,让模型分析自己是怎样一个人。
结果令他大吃一惊,模型给出了2000多字的分析,准确说出了他的个人情况。
7、从 DNS 查询国际空间站的位置(英文)
本文介绍 DNS 的一个妙用,它可以提供 LOC 记录,表示服务器的经纬度。作者就用这个记录,来提供国际空间站的当前位置。
工具
1、giscus一个基于 GitHub Discussion 的静态网站评论系统。
2、phpIPAM
这个工具通过 Web 界面,查看/管理局域网设备的 IP 地址,参见介绍文章。
3、NumPad
一个在线的网络笔记本,特点是可以进行数学计算,输入
1 + 1,它自动输出答案2。4、LiteOps
一个自搭建的轻量级 DevOps 平台,用来管理 CI/CD 操作。(@hukdoesn 投稿)
5、Ech0
一个开源的个人微博平台,查看 demo。(@lin-snow 投稿)
5、PageTemplatify
静态 HTML 页面生成工具,内置各类模版,适合快速测试或展示网页。(@luhuadong 投稿)
6、REM
基于 Rclone 的跨平台桌面 App,在一个窗口管理各种云存储的文件,实现文件互传。(@surunzi 投稿)
7、OnlyOffice Web
这个项目把 OnlyOffice 转成了 WASM 文件,不需要服务器,浏览器纯前端就能查看/编辑 Word、Excel、PowerPoint 文档,在线试用。(@chaxus 投稿)
8、在线拼图工具
免费的在线工具,多张图片拼成一张大图。(@ops-coffee 投稿)
9、Portfolio
一个基于 Docusaurus 的个人静态网站的模版,查看效果。
10、Postcard
一个自搭建的个人网站+新闻邮件服务,参见作者的产品介绍。
AI 相关
1、OpenCode一个 AI 终端客户端,可以在命令行向大模型发出指令,操作文件等,类似于 Claude Code,但是开源且不限定大模型种类。
2、Simple Chromium AI
Chrome 浏览器从138版后,内置了 Gemini Nano 模型,并提供 AI Prompt API 以便调用。
这个库就是浏览器 AI Prompt API 的封装,用起来更方便。
3、TouchFS
一个很有创意的 AI 命令行工具,用它加载目录后,直接输入文件名,就能自动生成想要的文件。比如,输入
touch README.md,就会自动生成自述文件。4、yutu
YouTube 的非官方 MCP 服务器,AI 智能体接入后,就能用自然语言操作 YouTube。(@OpenWaygate 投稿)
5、Pointer
一个 AI 聊天的桌面客户端,可以使用文件夹管理聊天记录,支持全文搜索和交叉表分析。(@experdot 投稿)
6、TTS Omni
免费的文本转语音网站,基于 Qwen-TTS。(@CurioChen77 投稿)
资源
1、气温地图这张地图可以查看全球当前的天气数据。(@Codeniu 投稿)
2、n8n 工作流导航
n8n 是一个工作流自动化编排软件,这个网站收集已经编排好的 n8n 工作流,目前共有近2000个。(@panyanyany 投稿)
另有一篇教程文章,通过 n8n 工作流,将网址保存进 Notion 数据库。
3、4 colors
这个网站提出,页面设计只需要4种颜色:前景色、背景色、强调色和趣味色。你可以在该网站生成这四种颜色的调色板。
图片
1、魔方板凳国外设计师制作的"魔方板凳"。
板凳就是一个魔方,必须解开魔方,才能坐上去。
实际上,只要把四条腿转到同一个面,就能坐了。
2、中国最大的书
中国最大最厚的书,是清朝的玉牒,一册厚达85厘米,重约90公斤。
它是皇家的族谱,记载的皇族宗室男性就有10余万人,由宗人府负责编撰,目前收藏于北京的中国第一历史档案馆。
文摘
1、计算机好比自行车摘自斯蒂夫·乔布斯1980年的访谈。
我记得,大概12岁的时候,读过一篇文章,应该是在《科学美国人》杂志。
那篇文章给出了地球上所有物种的运动效率,从 A 点到 B 点,同样的距离,它们消耗了多少能量。
结果,秃鹫位居榜首,运动效率最高,超越了其他所有生物。人类排在榜单的最后三分之一,对于"万物之王",这个成绩实在不值一提。
但是,作者很有想象力,测试了人类骑自行车的效率,结果远远超过了秃鹫,荣登榜首。
这给我留下了深刻的印象。我们人类是工具制造者。我们可以制造工具,将自己的能力放大到惊人的程度。
对我来说,计算机就是思维的自行车。它能让我们超越自身的能力。
我认为,我们才刚刚处于计算机的早期阶段----非常早期的阶段----我们只走了很短的一段路,计算机仍在发展中,但我们已经看到了巨大的变化。
我认为现在与未来一百年即将发生的事情相比,根本不算什么。
言论
1、长久以来,你努力培养技能,成为一个程序员,编程已经成为你的身份认同的一部分,是你人生价值的来源。突然之间,AI 取代了你的技能,让你的人生价值消失,许多人因此抵制 AI。
-- 《当 AI 可以编程,我还剩下什么?》
2、
洛杉矶的问题是太大,太分散,公共交通很少,必须开车。但是,这使得你根本遇不到有意思的人,他们都被困在车里。
-- Hacker News 读者
3、
AI 不缺乏知识,它的问题是不会怀疑现有知识。
要让 AI 变成爱因斯坦,仅仅让它无所不知是不够的,更需要让它能够提出别人未曾想到或不敢问的问题。
-- 托马斯·沃尔夫(Thomas Wolf),Hugging Face 联合创始人
4、
《纽约时报》报道,雇主正被大量 AI 生成的简历淹没,根据求职网站统计,今年的简历比去年激增45%。
AI 可能会让简历消亡,AI 生成的简历已经无法鉴别一个人了。未来的招聘应该采用 AI 无法介入的方式,比如现场解决问题。
-- 《AI 让简历消亡》
5、
如果你把爱好当成职业,想以此养活自己,一段时间后,最初的兴奋消退了,你就会发现,开始阶段根本不算什么,真正的困难在后面,无数繁琐和重复的工作正等着你。
这个时刻被称为"放弃点"(quitting point),很多人会在这个时点选择放弃。
每个人的放弃点不一样,但都会到来。作家的放弃点,也许是小说写到第30页,最初的灵感枯竭,不知道怎么写下去。创业者的放弃点,也许是最初的几个月之后,市场的反应不像朋友和家人那样热烈。艺术家的放弃点,也许是作品第一次上架后,意识到自己的愿景与能力之间存在巨大差距。
-- 《眼光过高是一种自我破坏》
往年回顾
无人驾驶出租车的双面刃(#309)如何免费使用 ChatGPT(#259)
程序员是怎样的人(#209)
游戏开发者的年薪(#159)
(完)
文档信息
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)
- 发表日期: 2025年7月11日
"Carrie Koos" / 2025-07-08 3 months ago / 未收藏/ Stack Overflow Blog/
发送到 kindle
Our July 2025 release focuses on stability, integration, and actionable insight—designed to help your teams stay informed, secure, and efficient as they scale.
"Katja Skafar" / 2025-07-10 3 months ago / 未收藏/ Stack Overflow Blog/
发送到 kindle
How do leaders ensure alignment, autonomy, and productivity as engineering practices continue to evolve?
"David Longworth" / 2025-07-10 3 months ago / 未收藏/ Stack Overflow Blog/
发送到 kindle
Help shape the future look of Stack Overflow—cast your vote and share your voice in our visual identity refresh.
"Prashanth Chandrasekar, Jody Bailey" / 2025-07-10 3 months ago / 未收藏/ Stack Overflow Blog/
发送到 kindle
Live from the stage of WeAreDevelopers, we’re unveiling our new vision and mission for the future of Stack Overflow and our community
"Phoebe Sajor" / 2025-07-11 3 months ago / 未收藏/ Stack Overflow Blog/
发送到 kindle
Ryan sits down with CTO Aruna Srivastava and CPO Ruslan Mukhamedvaleev from Koel Labs to talk about how they’re innovating speech technology with the help of AI and classic movies. They also tell Ryan about their time in the Mozilla Builders Accelerator and their experiences as student co-founders in an ever-changing economic and technological landscape.
"Christopher Harrison" / 2025-07-10 3 months ago / 未收藏/ Todd Motto/
发送到 kindle
Ensuring quality code suggestions from Copilot goes beyond the perfect prompt. Context is key to success when working with your AI pair programmer.
The post Beyond prompt crafting: How to be a better partner for your AI pair programmer appeared first on The GitHub Blog.
The post Beyond prompt crafting: How to be a better partner for your AI pair programmer appeared first on The GitHub Blog.
"Kevin Stubbings" / 2025-07-11 3 months ago / 未收藏/ Todd Motto/
发送到 kindle
Discover how to increase the coverage of your CodeQL CORS security by modeling developer headers and frameworks.
The post Modeling CORS frameworks with CodeQL to find security vulnerabilities appeared first on The GitHub Blog.
The post Modeling CORS frameworks with CodeQL to find security vulnerabilities appeared first on The GitHub Blog.
"Shaoni Mukherjee" / 2025-07-12 3 months ago / 未收藏/ DigitalOcean Community Tutorials/
发送到 kindle
Introduction
Generative AI is not a futuristic concept now, but a powerful tool we use in our daily lives. Whether it’s helping a marketer create ad campaigns, a teacher create lesson plans, or a developer build a custom chatbot, generative AI is transforming the way we work, learn, and communicate. Its ability to create text, images, code, and more, with just a simple prompt, is saving people time, boosting creativity, and opening up new possibilities for businesses of all sizes.Let us take an example of a freelance writer who once used to spend hours researching topics and creating every article outline from scratch. Now, with the help of Gen AI tools, they can instantly create multiple article outlines, understand research papers, and instantly create visual representations of complex topics.
Or think about a customer support team at a growing startup—they can now use an AI-powered assistant to answer common queries, freeing up their team to focus on more complex issues. These are just a few examples of how AI is helping people do more with less.
But as exciting as this technology is, it also brings new challenges. Without the right checks in place, AI systems can produce misleading or inappropriate content, unintentionally reflect bias, or even be used in harmful ways. For instance, an AI tool might generate false health advice, or a chatbot could respond rudely if not properly guided. This is where guardrails come in.
Think of Guardrails as the safety features in a car. Just like seatbelts, airbags, and lane assist systems help protect drivers and passengers, guardrails in AI platforms ensure that the technology is used safely, ethically, and responsibly. They prevent misuse, protect user privacy, and make sure the content AI produces is appropriate and aligned with real-world values.
The DigitalOcean GradientAI Platform allows you to use popular foundation models and build AI agents powered by GPUs with ease. You can choose between a fully-managed deployment or making direct requests through serverless inference.
Prerequisites
Before diving further into the article, it is important to have a basic understanding of the following concepts:-
Generative AI Basics: You should be familiar with what generative AI is and how it works. At a minimum, understand that it involves models like GPT, LLaMA, or Stable Diffusion that can generate text, images, or other media based on a given prompt.
-
Foundation Models: Some exposure to foundation models (e.g., GPT-4, LLaMA 3, Mistral) and how they are used as building blocks for AI applications will make it easier to understand how guardrails are applied to them.
-
DigitalOcean Account: To follow along or test out examples, you’ll need an active DigitalOcean account. You should also be familiar with basic account navigation within the DigitalOcean Console.
-
Agent and RAG Pipelines (Optional but Helpful): If you’ve worked with agents or retrieval-augmented generation pipelines before, you’ll have a head start.
Overview of DigitalOcean Guardrails
The DigitalOcean GenAI Platform addresses this need through Guardrails—powerful tools that help developers enforce boundaries, protect sensitive data, and prevent misuse of AI agents.
What Are Guardrails?
Guardrails are configurable safety controls you can attach to AI agents on the DigitalOcean GradientAI Platform. Their core purpose is to detect and respond to sensitive or inappropriate content, either in the input sent to an agent or in its output.When a guardrail is triggered, it overrides the agent’s default behavior and delivers a safer, predefined response. For example, if an input contains a credit card number, the agent will be blocked from responding as usual and instead issue a cautionary message.
Types of Guardrails
DigitalOcean provides three built-in guardrails that serve specific use cases:Sensitive Data Detection
- Detects information like credit card numbers, IP addresses, social security numbers, and other personally identifiable information (PII).
- Fully customizable—developers can choose which categories to detect.
Jailbreak Detection
- Blocks attempts to manipulate or bypass the model’s safety mechanisms.
- Useful for preventing prompt injection attacks and misuse.
Content Moderation
- Flags and intercepts content that is offensive, violent, explicit, or hateful.
- Helps keep applications aligned with content policies.
Attaching Guardrails to Agents
Guardrails can be attached through the DigitalOcean Control Panel using two workflows:Attach Multiple Guardrails to a Single Agent
Log in to your DigitalOcean GradientAI platform, click on the Agents tab to view all your agents, and select the agent to which you want to attach guardrails.
Next, open the Resources tab and scroll down to the Guardrails section and click Add guardrails.

Now, check the boxes next to the guardrails you want to attach, then click Save to confirm your changes.

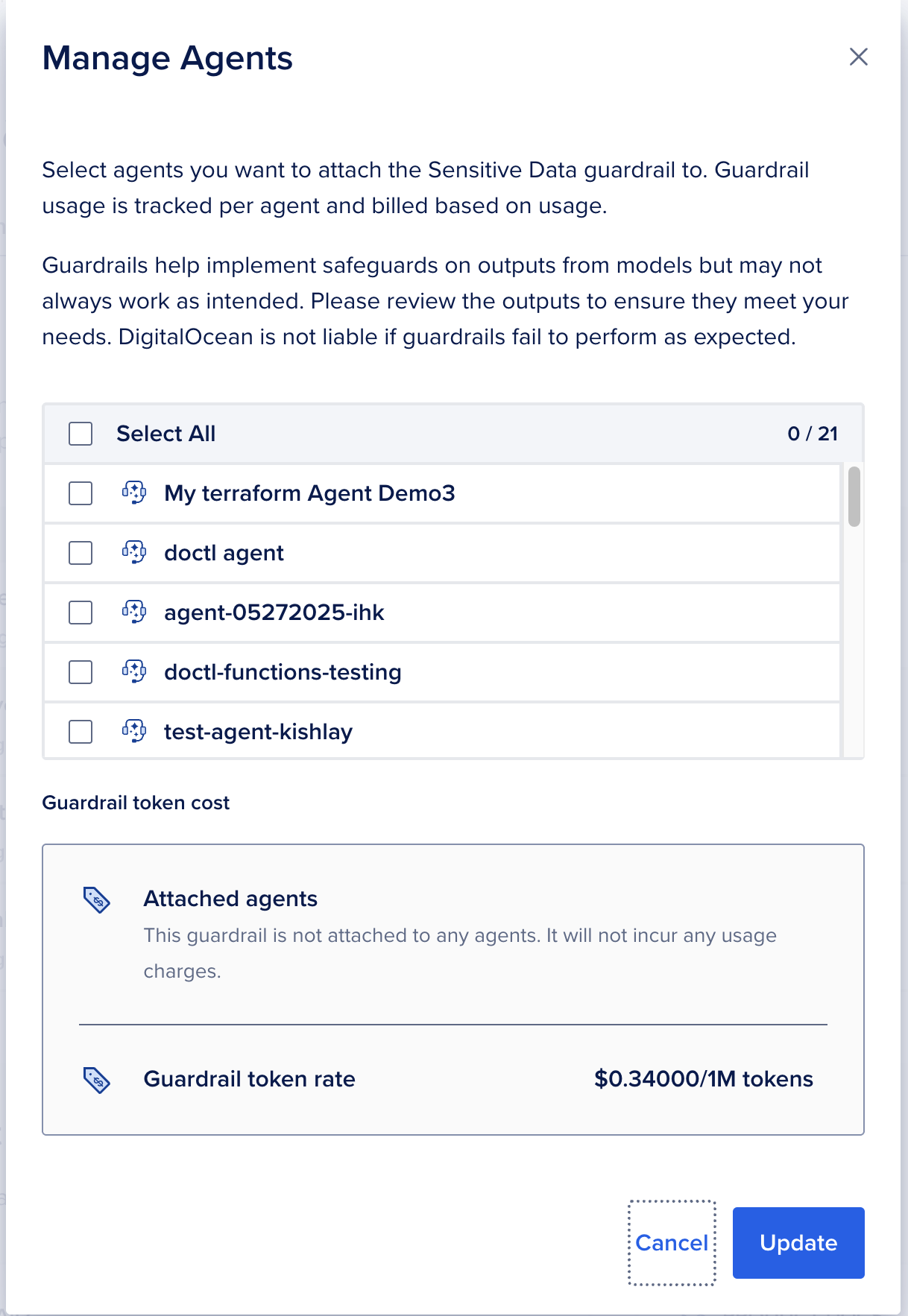
Attach a Guardrail to Multiple Agents**
To attach a guardrail to one or more agents, go to the DigitalOcean Control Panel and go to your GradientAI platform.Next, select the Guardrail tab.

Open the ellipsis(
… ) next to the desired guardrail and select Attach Agent.
The Manage Agents window will open up. Next, select the agents you want to attach and click Update.
Editing Guardrails
You can fine-tune guardrails to align with your use case:To edit your guardrails, navigate to the DigitalOcean Control Panel. From the left-hand menu, select GradientAI Platform, then click on the Guardrails tab to access the guardrails page.

In the Guardrails section, locate the guardrail you’d like to modify. Click the ellipsis (…) next to it and select Edit Guardrail.
You’ll be taken to the guardrail editing page, where you can update various guardrail settings.

On the guardrail editing page, you can modify several settings to tailor the behavior of your guardrail. First, you can update the Name and Description—particularly helpful if you’re editing a duplicated guardrail and want to give it a unique identity.
If the guardrail is of the Sensitive Data Detection type (or a duplicate of one), you can control which specific categories of sensitive information it detects. For example, you might choose to detect credit card numbers, IP addresses, or other data types. By default, all categories are enabled, but you can fine-tune this by clicking Customize categories and selecting only those relevant to your needs. Note that this customization is available only for Sensitive Data Detection guardrails.
You can also modify the Default Agent Response, which is the message the agent displays when the guardrail detects a match in an enabled category. The default response is: “I’m not able to respond to that request, but I can answer other questions. How can I help you with something else?” However, you’re free to replace this with a response more suited to your use case.
Lastly, under Attach Agents, you can link this updated guardrail to specific agents by selecting them from the list. Once all your changes are made, click Update Guardrail to save them.

Duplicating Guardrails
Duplicating a guardrail allows you to reuse and customize existing guardrail configurations without starting from scratch.
On the same guardrail page, you will find the option to duplicate the guardrail. Select that option.
Once you click Duplicate Guardrail, you’ll be taken to the guardrail duplication page where you can customize the following settings:
Name and Description
Enter a unique name and an optional description to identify the duplicated guardrail.
Sensitive Data Detection Categories If the duplicated guardrail is of the Sensitive Data Detection type, you can tailor which data categories it monitors. By default, all categories (e.g., credit card numbers, IP addresses) are enabled.
To customize:
- Click Customize categories
- Check or uncheck the boxes for the specific data types you want to include.

Default Agent Response
This is the message that appears when the agent detects a restricted input. The default message is: “I’m not able to respond to that request, but I can answer other questions. How can I help you with something else?” You can replace this with a custom response that better fits your application’s tone or use case.
Attach Agents If you want the duplicated guardrail to be active for specific agents, check the boxes next to the agents you want to assign it to.

Save the Duplicated Guardrail
After configuring all the required settings, click Duplicate Guardrail to finalize and save your new guardrail.
Destroying Guardrails
If a guardrail is no longer needed, you can easily delete it from the DigitalOcean Control Panel. Follow these steps to safely remove a guardrail:
Log in to the DigitalOcean GradientAI account. Open the same Guardrails tab to open the Guardrails management page.
Next, locate the guardrail you wish to delete and click the ellipsis icon (…) to the right of that guardrail.
In the Guardrails section, find the guardrail you want to delete. A confirmation dialog will appear asking if you’re sure you want to delete the selected guardrail.

Click Confirm or Delete to permanently remove the guardrail. Note: Deleting a guardrail is irreversible. Once deleted, the configuration and settings cannot be recovered.
Best Practices
Implementing guardrails is not just about turning on a few settings and calling it a day. It is also about thoughtful customization, a continuous refinement process, and staying mindful of your users’ experiences. Here are some best practices to help you get the most out of DigitalOcean’s guardrails features:-
Customize and Caution:
Every AI application is different, and so are its users. When adding or tweaking guardrail settings, it’s important to test with real-world prompts. Try prompts that mimic what your end users might actually type. This will help you understand how the model responds and whether it blocks or allows content appropriately. A too-strict guardrail might stop legitimate use cases, while a too-lenient one could let risky content through. Always strike a balance between safety and usability.
-
Use Duplicates for Flexibility:
DigitalOcean’s guardrail system lets you duplicate configurations. For example, you might need stricter content filters for a customer support chatbot, but a more open setup for an internal tool. By duplicating a base configuration, you can customize each version independently, without affecting the original settings.
-
Monitor and Iterate Often:
AI keeps changing; hence, after deploying an agent, always make it a habit to review the agent. This gives you valuable feedback. Are you blocking too much content? Not enough? Use these insights to fine-tune detection categories and thresholds over time. Think of it like tuning a radio: small adjustments can make a big difference in clarity and performance.
Conclusion
By setting up clear boundaries, whether that means filtering out harmful content, limiting model behaviour, or adding extra data privacy, you’re not only protecting your users, you’re also building trust. That trust becomes the foundation for more meaningful, impactful AI applications.
Guardrails don’t limit creativity—they create space for safe innovation.
As you build with GradientAI, remember that ethical AI isn’t just about what your model can do—it’s about what it should do. Guardrails help you stay on the right path.
Further, DigitalOcean gives you the flexibility to shape your AI to meet your goals without compromising responsibility."James Skelton" / 2025-07-12 3 months ago / 未收藏/ DigitalOcean Community Tutorials/
发送到 kindle
Serverless inference is, rightfully, one of the hottest topics in both technical and non-technical circles of AI users, and for good reason. While controlling every aspect of a deployment is often necessary for deploying custom models, serverless takes away the headaches of maintaining and managing a model deployment and API endpoint. This can be incredibly useful for a myriad of different agentic LLM use cases.
In this tutorial, we will show how to get started with Serverless Inference on the GradientAI Platform using the DigitalOcean API. Afterwards, we will discuss some of the potential use cases for the methodology in production and daily workflows.
To get started, we can either use the DigitalOcean API or the Cloud Console. Let’s look at each methodology.
Use the navigation bar on the left hand side of the homepage, and scroll down until you see “API”. Click in to open the API homepage. We can then use the button on the top right to create a new key.
In the key creation page, name your key as needed and give appropriate permissions. To do this, either give full permission or scroll down to “genai” in the custom scope selection and select all. Then, create the key. Save this value for later.

If we want to use the console, simply navigate to the GradientAI platform tab “Serverless Inference” in the Console. Once there, use the button on the bottom right to “Create model access key”.

Then, all we have to do is name our key. Save the output value for later! We will need it for Serverless Inference with Python.
Once your env is set up, open a new .ipynb IPython Notebook file. Use the code snippet below to begin generating text, specifically answering what the capital of France is. Edit the snippet to reflect your changed API key value on line 5.
Now that we have set up our environment to run Serverless Inference, we have a plethora of possible activities we can use the model for. From everything an LLM is capable of, we can create powerful agentic applications that leverage the strength of the AI model. Some possible use cases for this include:
Serverless Inference is a true answer for companies seeking LLM based solutions without the hassle of hiring or learning the required steps to deploying your own server. With DigitalOcean’s GradientAI Platform, accessing Serverless Inference from powerful NVIDIA GPUs just became easier than ever! We encourage everyone to try the new solution!
In this tutorial, we will show how to get started with Serverless Inference on the GradientAI Platform using the DigitalOcean API. Afterwards, we will discuss some of the potential use cases for the methodology in production and daily workflows.
Accessing Serverless Inference on the GradientAI Platform
To get started, we can either use the DigitalOcean API or the Cloud Console. Let’s look at each methodology.Step 1a: Create a DigitalOcean API Key
To get started, you first need to create your own DigitalOcean account and login. Once you’ve done so, navigate to the team space of your choice. From here, we will create a DigitalOcean API key. This will help us create our model access token later on, so we can actually skip this step and go to the section “Step 2b: Create a Model Access key with the Cloud Console”.Use the navigation bar on the left hand side of the homepage, and scroll down until you see “API”. Click in to open the API homepage. We can then use the button on the top right to create a new key.
In the key creation page, name your key as needed and give appropriate permissions. To do this, either give full permission or scroll down to “genai” in the custom scope selection and select all. Then, create the key. Save this value for later.
Step 2A: Create a Model Access key with the API
Next, we are going to make our model access key for GradientAI’s Serverless Inference. To do so, we can either use the console or API. To use the API, use the saved API key from earlier with the following curl request in your terminal. Replace the value for “$DIGITALOCEAN_TOKEN” with your own.curl -X POST -H 'Authorization: Bearer $DIGITALOCEAN_TOKEN' https://api.digitalocean.com/v2/gen-ai/models/api_keys
Step 2B: Create a Model Access key with the Cloud Console
If we want to use the console, simply navigate to the GradientAI platform tab “Serverless Inference” in the Console. Once there, use the button on the bottom right to “Create model access key”.
Then, all we have to do is name our key. Save the output value for later! We will need it for Serverless Inference with Python.
Step 3: Generating Text with Python and Serverless Inference
With our new model access key, we can begin running DigitalOcean Serverless Inference from any machine with internet access! We recommend working from a Jupyter Notebook. Follow the steps outlined in this tutorial for tips on setting up your environment for this article.Once your env is set up, open a new .ipynb IPython Notebook file. Use the code snippet below to begin generating text, specifically answering what the capital of France is. Edit the snippet to reflect your changed API key value on line 5.
from openai import OpenAI
import os
client = OpenAI(
api_key= **“your_model_access_key_here”**,
base_url="https://inference.do-ai.run/v1"
)
stream = client.chat.completions.create(
model="llama3-8b-instruct",
messages=[
{
"role": "developer",
"content": "You are a helpful assistant.",
},
{
"role": "user",
"content": "What is the capital of France?",
},
],
stream=True,
max_completion_tokens=10
)
for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
max_completion_tokens to better suit your prompt as needed. We can also edit the model value on line 10 to be any of the available models listed in the DigitalOcean GradientAI Model offerings. This model zoo is constantly being updated to reflect the growing industry, so check back frequently for updates.
Use cases for Serveless AI from DigitalOcean
Now that we have set up our environment to run Serverless Inference, we have a plethora of possible activities we can use the model for. From everything an LLM is capable of, we can create powerful agentic applications that leverage the strength of the AI model. Some possible use cases for this include:- Event driven applications: Where a specific occurrence triggers the run of the LLM, this is common in agentic use cases
- Scalable backend services: When the inference on the backend may need to be scaled indefinitely, serverless can guarantee that your users will never be left waiting
- Data processing: batch jobs and data processing can be handled effectively and efficiently without requiring costly setup Source
- And much more!
Closing Thoughts
Serverless Inference is a true answer for companies seeking LLM based solutions without the hassle of hiring or learning the required steps to deploying your own server. With DigitalOcean’s GradientAI Platform, accessing Serverless Inference from powerful NVIDIA GPUs just became easier than ever! We encourage everyone to try the new solution!"Shaoni Mukherjee" / 2025-07-12 3 months ago / 未收藏/ DigitalOcean Community Tutorials/
发送到 kindle
Imagine asking your command line to summarize yesterday’s code commits, help you with your PDFs, explain the code block created two years back, or automate the boring task of sorting invoices, all with one simple prompt. That’s exactly what Google’s Gemini CLI delivers. This powerful open-source command-line tool connects directly with Google’s Gemini AI models to bring intelligent assistance to developers, tech leads, and solo coders alike. Whether you’re navigating a messy codebase or automating your workflows, Gemini CLI might just be your new favorite teammate.
Gemini CLI is an AI-powered command-line tool developed by Google that understands your code, connects with your tools, and helps automate complex workflows. Built on top of Gemini 2.5 Pro, it can analyze large codebases, generate apps from files or drawings, manage pull requests, and even help create media content.
In simple terms, it’s like having a coding assistant, project manager, and AI researcher, all in one tool you run from your terminal.

Let’s say you want to understand all the content of the PDF documents stored in your directory:
We’re entering a new era where AI tools don’t just answer questions, they take action. Gemini CLI bridges the gap between your workflow and AI assistance. It’s multimodal, meaning it can understand not just code but also PDFs and sketches. You can use it to generate full-stack apps, analyze system architecture, and even automate internal reports.
And the best part? It works in your terminal. No extra GUI, and no context switching.
Make sure you have Node.js version 20 or higher installed.
Run via:
Gemini CLI feels like the future of developer tools, context-aware, prompt-driven, and deeply integrated with your workflow. Whether you’re trying to save time, understand your project better, or just want an AI-powered command line assistant, Gemini CLI is worth a try.
“Describe the architecture.”
“Build a bot.”
“Summarize yesterday’s code.”
Just type it. Gemini does the rest.
What is Gemini CLI?
Gemini CLI is an AI-powered command-line tool developed by Google that understands your code, connects with your tools, and helps automate complex workflows. Built on top of Gemini 2.5 Pro, it can analyze large codebases, generate apps from files or drawings, manage pull requests, and even help create media content.In simple terms, it’s like having a coding assistant, project manager, and AI researcher, all in one tool you run from your terminal.
How to Use Gemini CLI?
Let’s say you want to understand all the content of the PDF documents stored in your directory:cd my-new-project/
gemini
> Help me understand the PDF in this directory. And also provide a summary of the documents.
cd some-huge-repo/
gemini
> Describe the main architecture of this system.
gemini
> Convert all images in this folder to PNG and name them using the EXIF date.
Why It Matters
We’re entering a new era where AI tools don’t just answer questions, they take action. Gemini CLI bridges the gap between your workflow and AI assistance. It’s multimodal, meaning it can understand not just code but also PDFs and sketches. You can use it to generate full-stack apps, analyze system architecture, and even automate internal reports.And the best part? It works in your terminal. No extra GUI, and no context switching.
To get started with Gemini CLI, what do you need?
Make sure you have Node.js version 20 or higher installed.Run via:
npx https://github.com/google-gemini/gemini-cli
npm install -g @google/gemini-cli
gemini
Final Thoughts
Gemini CLI feels like the future of developer tools, context-aware, prompt-driven, and deeply integrated with your workflow. Whether you’re trying to save time, understand your project better, or just want an AI-powered command line assistant, Gemini CLI is worth a try.“Describe the architecture.”
“Build a bot.”
“Summarize yesterday’s code.”
Just type it. Gemini does the rest.
"Safa Mulani" / 2025-07-12 3 months ago / 未收藏/ DigitalOcean Community Tutorials/
发送到 kindle
Introduction
In any application that handles text, there’s always a need to manage character casing. Whether you’re normalizing user input, ensuring consistent data storage, or performing a case-insensitive search, changing a string to uppercase or lowercase is a fundamental skill. This robust string manipulation prevents bugs and makes your program’s logic more reliable.This article will provide a practical guide to the most effective techniques to master this skill. We’ll begin by exploring the recommended and most idiomatic C++ approach using
std::transform from the Standard Library. Then, we’ll cover the foundational technique of using a traditional for-loop to change character case manually. Finally, we’ll dive into key best practices and performance considerations to help you choose the right method and avoid common pitfalls in your projects.By the end of this guide, you’ll have a clear understanding of how to confidently and correctly handle any string case conversion challenge in C++.
Key Takeaways
- For simple ASCII strings, use
std::transformor a range-based for-loop for efficient and readable in-place case conversion in C++. - To prevent undefined behavior, always cast characters to
unsigned charbefore passing them to standard library functions likestd::toupperandstd::tolower. - Standard C++
toupperandtolowerfunctions are not Unicode-aware and can fail on international characters, as they only support one-to-one character mapping. - For reliable, locale-aware case conversion in applications handling international text, you must use a dedicated library like ICU (International Components for Unicode).
- The ICU library correctly handles complex, one-to-many character mappings (e.g., German ‘ß’ to ‘SS’) that the standard C++ library cannot.
- Never use manual ASCII arithmetic (e.g.,
char - 32) in production code; it is unsafe, not portable, and only works for basic English characters.
Understanding C++ Strings - std::string vs C-style strings
Before diving into case conversion, it’s crucial to know what kind of strings we’re using. In C++, you have two primary choices for handling text: the modern std::string vs C-style stringsstd::string class and traditional C-style strings.For almost every situation in modern C++, you should use
std::string. It’s safer, easier to use, and more powerful. C-style strings are character arrays inherited from the C language (char* or char[]) that end with a null-terminator (\0). They are fast but notoriously difficult and unsafe to manage manually.This detailed table shows exactly why
std::string is the superior choice:| Feature | std::string |
C-style String (char*) |
|---|---|---|
| Memory Management | Automatic. The string grows and shrinks as needed. No manual memory handling is required, preventing memory leaks. | Manual. You must allocate and deallocate memory yourself using new[]/delete[] or malloc/free. Very prone to errors. |
| Getting Length | Simple and direct: my_str.length() or my_str.size(). |
Requires scanning the entire string to find the \0 character: strlen(my_str). |
| Concatenation | Intuitive and easy using the + or += operators. Example: str1 + str2. |
Manual and complex. Requires allocating a new, larger buffer and using functions like strcpy and strcat. |
| Comparison | Straightforward using standard comparison operators (==, !=, <, >). |
Requires using the strcmp() function. Using == just compares pointer addresses, not the content. |
| Safety | High. Provides bounds-checked access with .at(), which throws an exception if you go out of bounds. This helps prevent crashes. |
Low. No built-in protection against writing past the end of the array, leading to buffer overflows, a major security risk. |
| STL Integration | Seamless. Designed to work perfectly with standard algorithms (std::transform, std::sort) and containers. |
Limited. Can be used with some algorithms but often requires more careful handling and wrapping. |
std::string is the clear winner. It eliminates entire classes of common bugs while providing a much more pleasant and productive developer experience.For these reasons, this article will focus exclusively on
std::string, the modern, safe, and efficient standard for handling text in C++.
How to Convert a C++ String to Uppercase
Changing a string to all uppercase letters is a common task in C++ or any other programming language. Whether you’re normalizing keywords or formatting display text, C++ offers a couple of excellent, standard ways to do it. We’ll explore three methods, starting with the most recommended one.Method 1: The Standard C++ Way with std::transform
The most idiomatic and powerful method is to use the std::transform algorithm from the <algorithm> header. This function is designed to apply an operation to a sequence of elements, making it a perfect fit for our task. It’s favored in professional code because it’s expressive and can be highly optimized by the compiler.Here’s a simple example:
#include <iostream>
#include <string>
#include <algorithm>
#include <cctype>
int main() {
std::string input_text = "Hello World!";
std::transform(input_text.begin(), input_text.end(), input_text.begin(), ::toupper);
std::cout << "Result: " << input_text << std::endl;
return 0;
}
input_text.begin() and input_text.end(), define the input range for the operation, which covers the entire string. The third argument, also input_text.begin(), sets the destination for the results. Since the destination is the same as the source, the function performs an efficient in-place modification. Finally, ::toupper is applied to each character within the defined range.Method 2: The Simple For-Loop
If you find iterators complex or simply prefer a more step-by-step approach, a for-loop is a completely valid alternative. A modern range-based for-loop makes the code incredibly clean and readable.Let’s see an example:
#include <iostream>
#include <string>
#include <cctype>
int main() {
std::string input_text = "This is a DigitalOcean tutorial!";
for (char &c : input_text) {
c = std::toupper(static_cast<unsigned char>(c));
}
std::cout << "Result: " << input_text << std::endl;
return 0;
}
for (char &c : input_text) loop iterates through each character of the string. The ampersand in &c is critical as it creates a reference to the character. This means you’re modifying the original string directly, not just a temporary copy.Inside the loop,
c = std::toupper(...) assigns the uppercase version back to the character. The static_cast<unsigned char> is an important safety measure that prevents potential errors by ensuring the input to std::toupper is always non-negative.Method 3: Manual ASCII Math
This method involves changing a character’s underlying numeric value. It’s a great way to understand character encoding but should not be used in production code.Here’s a simple code example:
#include <iostream>
#include <string>
int main() {
std::string my_text = "Manual conversion";
for (char &c : my_text) {
if (c >= 'a' && c <= 'z') {
c = c - 32;
}
}
std::cout << "Result: " << my_text << std::endl;
return 0;
}
It loops through each character by reference. The
if statement checks if a character is a lowercase English letter (between ‘a’ and ‘z’). If it is, the code subtracts 32 from its numeric ASCII value, which is the exact difference required to convert it to its uppercase equivalent (for example, ‘a’ is 97 and ‘A’ is 65).While this works for basic English text, it’s not a recommended practice because it’s not portable and will fail for any text outside the simple A-Z alphabet, such as accented or international characters.
How to Convert a C++ String to Lowercase
Converting a string to lowercase follows the exact same principles as converting to uppercase. The standard C++ methods are symmetrical, simply requiring you to use the lowercase equivalent function. We’ll cover the same three reliable methods.Method 1: Using std::transform
The most idiomatic C++ approach is to use the std::transform algorithm. To convert to lowercase, you simply swap ::toupper with ::tolower. It remains the most expressive and efficient method for the job.#include <iostream>
#include <string>
#include <algorithm>
#include <cctype>
int main() {
std::string my_text = "THIS IS A LOUD SENTENCE.";
std::transform(my_text.begin(), my_text.end(), my_text.begin(), ::tolower);
std::cout << "Result: " << my_text << std::endl;
return 0;
}
std::transform iterates through the entire string and applies the ::tolower operation to each character, modifying the string in-place for great efficiency.Method 2: Using a Traditional For-Loop
A for-loop provides a clear, step-by-step alternative that is easy to read and understand. This approach is perfect if you prefer more explicit control over the iteration.#include <iostream>
#include <string>
#include <cctype>
int main() {
std::string my_text = "ANOTHER EXAMPLE.";
for (size_t i = 0; i < my_text.length(); ++i) {
my_text[i] = std::tolower(static_cast<unsigned char>(my_text[i]));
}
std::cout << "Result: " << my_text << std::endl;
return 0;
}
i to access each character via my_text[i]. It then calls std::tolower to get the lowercase equivalent and assigns it back to the same position. The static_cast<unsigned char> is a crucial safety habit to prevent errors with certain character values.Method 3: Manual ASCII Manipulation
This method involves adding 32 to a character’s ASCII value to convert it from uppercase to lowercase. Like its uppercase counterpart, this should only be used for learning and avoided in real-world applications.#include <iostream>
#include <string>
int main() {
std::string my_text = "MANUAL CONVERSION";
for (char &c : my_text) {
if (c >= 'A' && c <= 'Z') {
c = c + 32;
}
}
std::cout << "Result: " << my_text << std::endl;
return 0;
}
Understanding Locale-aware String Conversion
Locale-aware conversions are essential when working with internationalized applications that need to handle text from different languages and regions. Unlike simple ASCII-based conversions, locale-aware methods respect the cultural and linguistic rules specific to different locales, ensuring proper case conversion for characters beyond the basic English alphabet.The Standard C++ Approach: std::wstring and std::locale
The C++ standard library’s built-in method for handling Unicode involves wide strings (std::wstring) and the <locale> library. The wchar_t character type in a wide string can represent characters beyond a single byte. The process requires setting a global locale and using wide streams for I/O.#include <iostream>
#include <string>
#include <algorithm>
#include <locale>
int main() {
std::locale::global(std::locale(""));
std::wcout.imbue(std::locale());
std::wstring text = L"Eine Straße in Gießen.";
const auto& facet = std::use_facet<std::ctype<wchar_t>>(std::locale());
std::transform(text.begin(), text.end(), text.begin(), [&](wchar_t c){
return facet.toupper(c);
});
std::wcout << L"std::locale uppercase: " << text << std::endl;
return 0;
}
std::locale uppercase: EINE STRAßE IN GIEßEN.
std::ctype::toupper function is designed for one-to-one mapping only. It takes one character and must return one character. It cannot handle the ß → SS conversion, which requires mapping one character to two.How to Use ICU for Case Conversion
To overcome the standard library’s limitations, you need a library built for serious Unicode work. The industry standard is ICU (International Components for Unicode). ICU’s functions are designed to handle complex string-level transformations, including one-to-many mappings.This example uses ICU to get the correct output.
#include <unicode/unistr.h>
#include <unicode/locid.h>
#include <iostream>
int main() {
std::string input = "Eine Straße in Gießen.";
icu::UnicodeString ustr = icu::UnicodeString::fromUTF8(input);
ustr.toUpper(icu::Locale("de"));
std::string output;
ustr.toUTF8String(output);
std::cout << "Unicode-aware uppercase: " << output << std::endl;
return 0;
}
icu::UnicodeString::fromUTF8(input)converts the standardstd::stringinto ICU’s core string class,UnicodeString. This is the necessary first step, as ICU’s functions operate on this specialized type..toUpper(icu::Locale("de"))is the key function. It applies the case conversion rules defined by the German (de)icu::Localeobject. This method correctly handles the one-to-many mapping of ß to SS..toUTF8String(output)converts the result from ICU’s internal format back into a standardstd::stringso it can be easily used withstd::coutand other C++ components.
Unicode-aware uppercase: EINE STRASSE IN GIESSEN.
Performance Comparison and Best Practices
While correctness and readability should always be your priority, it’s helpful to understand the performance characteristics of different string conversion methods. For most applications, the differences are minor, but in performance-critical code, choosing the right approach can matter.
Benchmarking Different Methods
Benchmarking shows a clear trade-off between raw speed for simple cases and the overhead required for correctness in complex cases.std::transformvs. For-Loop: For typical string lengths, the performance of these two methods is virtually identical. Modern compilers are exceptionally good at optimizing simple loops and standard algorithms, often generating the same machine code for both. For very large strings,std::transformcan sometimes have a slight edge, as it more clearly expresses the intent to the compiler, which may apply advanced optimizations like vectorization.- Manual ASCII Math: In micro-benchmarks with pure English text, this method is often the fastest as it avoids any function call overhead. However, this minuscule gain is not worth the cost. The
ifstatement can lead to CPU branch mispredictions if the text is a mix of cases, and the method is fundamentally unsafe and non-portable. - ICU Library: ICU is a highly optimized library. For simple ASCII text, it will be slower than the native C++ methods due to the overhead of creating
UnicodeStringandLocaleobjects. However, for its intended purpose, i.e., processing complex, international Unicode text, its performance is excellent and far surpasses the incorrect attempts of the standard library.
Memory Efficiency Considerations
Memory usage is primarily about whether you modify the string in-place or create a copy.- In-Place Modification: This is the most memory-efficient approach. Using
std::transformon the source string or iterating with a for-loop and a reference (&c) modifies the string’s existing memory without allocating a new buffer. This should be your default method. - Creating Copies: If you need to preserve the original string, you must create a copy (std::string new_str = old_str;). This temporarily doubles the memory usage for that string. Do this only when necessary.
- ICU Memory: The
icu::UnicodeStringobject has its own memory management and will have a different memory footprint thanstd::string. This is a necessary trade-off for the powerful features and correctness it provides.
Best Practices
Here are the key takeaways for writing robust, efficient, and correct code.- Prioritize Correctness Over Micro-optimizations: A program that is 0.01% faster but corrupts international text is a broken program. For any user-facing text, correctness is paramount.
- Always Use
unsigned charwith Standard Functions: To prevent undefined behavior, always cast your char tounsigned charbefore passing it tostd::toupperorstd::tolower.
c = std::toupper(static_cast<unsigned char>(c));
- Modify In-Place for Efficiency: Unless you need to preserve the original string, use in-place operations to conserve memory and avoid the overhead of new allocations.
- Know Your Data: Assume Unicode: If your application handles text from any external source (users, files, APIs), assume it is Unicode. Use the ICU library for all case conversions to ensure correctness. Standard methods are only safe for internal, hard-coded ASCII strings.
- Choose Readability: The performance difference between std::transform and a for-loop is almost always negligible. Choose the method that you and your team find more maintainable.
- Never Use Manual ASCII Math in Production: This approach is unsafe, not portable, and will fail on non-English text. It should be avoided entirely.
Frequently Asked Questions (FAQs)
1. How do I convert a string to uppercase in C++?
The most common and recommended way is to use std::transform from the<algorithm> header.#include <iostream>
#include <string>
#include <algorithm>
#include <cctype>
int main() {
std::string input_text = "Hello World!";
std::transform(input_text.begin(), input_text.end(), input_text.begin(), ::toupper);
std::cout << "Result: " << input_text << std::endl;
return 0;
}
::toupper function to every character in the string, modifying it in-place.2. Is toupper() safe for all locales?
No, the standard ::toupper and std::toupper functions are not safe for all locales. They are generally only reliable for basic ASCII characters. They can fail on characters from other languages, most famously being unable to convert the German ‘ß’ to “SS”. For true locale-aware conversions, you must use a dedicated library like ICU (International Components for Unicode).3. Can I use C-style strings with these methods?
While you can, it’s more complex and less safe than usingstd::string. You cannot use std::transform directly because C-style strings (like char*) don’t have iterators. You must use a manual for-loop with strlen().The best practice is to first convert the C-style string to a
std::string and then apply the methods discussed in this article.#include <iostream>
#include <string>
#include <algorithm>
#include <cctype>
int main() {
const char* c_style_string = "hello from a c-style string!";
std::string my_string = c_style_string;
std::transform(my_string.begin(), my_string.end(), my_string.begin(), ::toupper);
std::cout << "Result: " << my_string << std::endl;
return 0;
}
4. How do you check if a string contains both uppercase and lowercase letters in C++?
You can iterate through the string and use flags to track whether you’ve seen at least one of each.#include <string>
#include <cctype>
bool has_both_cases(const std::string& s) {
bool has_lower = false;
bool has_upper = false;
for (char c : s) {
if (std::islower(c)) has_lower = true;
if (std::isupper(c)) has_upper = true;
if (has_lower && has_upper) return true;
}
return has_lower && has_upper;
}
5. How do you convert all uppercase to lowercase in C++?
Similar to converting to uppercase, the recommended method is usingstd::transform, but with ::tolower.#include <iostream>
#include <string>
#include <algorithm>
#include <cctype>
int main() {
std::string input_text = "HELLO WORLD!";
std::transform(input_text.begin(), input_text.end(), input_text.begin(), ::tolower);
std::cout << "Result: " << input_text << std::endl;
return 0;
}
6. Why doesn’t std::toupper work correctly for characters like ‘ß’ or ‘é’?
This happens for two main reasons:- One-to-One Mapping Limitation: The standard C++
toupperfunction is designed to take one character and return exactly one character. It is fundamentally incapable of handling conversions like the Germanßto the two-character stringSS. - Encoding Issues: When used on a UTF-8
std::string,std::toupperoperates byte-by-byte. It sees a multi-byte character likeéas two separate, meaningless bytes and cannot convert it correctly.
Conclusion
This article provided a detailed overview of C++ string case conversion. For basic ASCII strings, std::transform and for-loops are the recommended, efficient methods, but always cast characters to unsigned char to ensure safety. We demonstrated that for complex Unicode, the standard library’s std::locale is insufficient because it cannot handle critical one-to-many character mappings (like ‘ß’ to ‘SS’).As discussed in the article, the correct solution for international text is to use a dedicated library like ICU, which guarantees accurate, locale-aware conversions. This article emphasized that best practices require choosing your tool based on the data you’re processing. For any application handling user input or text from varied sources, relying on a robust library like ICU is essential for building correct and reliable software.
You are now equipped with the knowledge to not only change a string’s case but to do so correctly, efficiently, and safely in any scenario you might encounter.
Now that you’ve mastered string case conversion, take your C++ string manipulation skills to the next level with these essential guides:
-
How to Reverse a String in C++: A Guide with Code Examples - Learn multiple methods to reverse strings in C++, including using STL algorithms, iterators, and manual character swapping. Understand the performance implications and best practices for each approach.
-
3 Ways to Compare Strings in C++ - Master string comparison in C++ using operators, member functions, and C-style functions. Covers case-sensitive and case-insensitive comparisons, as well as handling special cases like substrings.
-
How to Find the Length of an Array in C++ - Explore different techniques to determine array sizes in C++, including using sizeof(), std::size(), and other methods. Learn about limitations and best practices when working with arrays of different types.
"Melani Maheswaran" / 2025-07-12 3 months ago / 未收藏/ DigitalOcean Community Tutorials/
发送到 kindle
The Importance of Evaluations
Evaluations are the foundation of developing reliable AI systems because they offer a standardized approach to verifying model performance. Without rigorous evaluation, we risk deploying systems of unprecedented complexity while remaining misinformed on their actual capabilities. This is not merely about performance as it is about the fundamental imperative that we know the scope of what we deploy.In this article, we will be discussing RewardBench 2. This is a new benchmark for evaluating reward models, distinguishing itself by incorporating unseen prompts from actual users rather than recycling prompts from existing evaluations.
Primer on Reward Models
Reward models are trained on preference data, where prompts (x) and completions (y) are ranked by humans or automated metrics. The process involves comparing two completions for each prompt, labeling one as “chosen” and the other as “rejected.” A reward model is then trained to predict the likelihood of a prompt and completion being chosen, utilizing a Bradley-Terry model of human preferences.
 Maximum Likelihood Estimation (MLE) finds the optimal parameters θ that best explain the observed preference data.
Maximum Likelihood Estimation (MLE) finds the optimal parameters θ that best explain the observed preference data.
 The likelihood function L(θ, D) represents how well the model with parameters θ explains the D.
D represents the preference data distribution from which the “chosen” and “rejected” completion pairs, along with their corresponding prompts, are sampled.
The likelihood function L(θ, D) represents how well the model with parameters θ explains the D.
D represents the preference data distribution from which the “chosen” and “rejected” completion pairs, along with their corresponding prompts, are sampled.Reward models (RMs) have a number of use cases, including but not limited to:
RLHF ( Reinforcement Learning From Human Feedback ) is how AI systems incorporate human preferences and values. The process typically involves three stages: first, a model is pre-trained on large datasets (pre-training); second, human evaluators rank or rate the model’s outputs to create a preference dataset; and third, the model is fine-tuned using reinforcement learning to maximize alignment with human preferences. This approach helps AI systems produce outputs derived by learning from human judgment rather than just optimizing for traditional metrics.
Inference-time scaling, also known as test-time compute, refers to the allocation of more computational resources during inference. Here, the model is “thinking harder” by exploring multiple solution trajectories, with a reward model guiding the selection of the best candidate solution. Inference-time scaling allows for improved reasoning and accuracy without modification of the model’s pre-trained weights.
RewardBench 2 Composition
About 70% of prompts are sourced from WildChat, a corpus of 1 million user-ChatGPT conversations, consisting of over 2.5 million interaction turns. From a collection of prompts, a combination of QuRater for data annotation, a topic classifier for identifying the prompt domain, and manual inspection were used to filter and assign prompts to domain-specific subsets.RewardBench 2 Domains
There are 6 domains in the benchmark: Factuality, Precise Instruction Following, Math, Safety, Focus, and Ties. The Math,Safety, Focus domains build upon the original RewardBench’s Math, Safety, and Chat-Hard sections. The Factuality, Precise Instruction Following, and Ties are introduced in RewardBench 2.| Domain (Count) | Description | Prompt Source | Method of Generating Completions | Scoring |
|---|---|---|---|---|
| Factuality (475) | Test RM’s ability to detect hallucinations | Human (in-the-wild chat interactions) | Both natural and System Prompt Variation | Majority voting, LLM-as-a-judge (two LLMs must agree to assign a label) |
| Precise Instruction Following (160) | Tests RM’s ability to follow instructions like “Answer without the letter u” | Human (in-the-wild chat interactions) | Natural | Verifier functions to evaluate adherence to constraint |
| Math (183) | Tests RM’s math ability | Human (in-the-wild chat interactions) | Natural | Majority voting, LM-as-a-judge & manual verification |
| Safety (450) | Tests RM’s ability to correctly determine which responses should be complied with or refused | CoCoNot | Both natural and System Prompt Variation | Subset-specific rubrics for judging compliance with GPT-4o, manual verification for half of examples |
| Focus (495) | Tests RM’s ability to detect on-topic answers of high-quality | Human (in-the-wild chat interactions) | System Prompt Variation | N/A (implied by method of generation, which differentiates chosen and rejected completions) |
| Ties (102) | Tests model’s ability to avoid expressing overly strong or arbitrary preferences among equivalent correct answers, while still clearly preferring any correct answer over any incorrect one. | Manual (Researchers) | System Prompt Variation | Weighted score of accuracy (all valid correct answers scored higher than all incorrect answers) and whether reward margin between correct and incorrect answers exceeds that of highest and lowest-scored correct responses |
Method of Generating Completions
The "Natural” method for generating completions means that the completions are generated without any specific system prompts designed to induce errors or variations. Instead, they are uninfluenced outputs from the language models. This contrasts with “System Prompt Variation,” where models are explicitly instructed to create subtle factual errors or off-topic responses for the “rejected” completions.Scoring
The scoring process works in two stages:- Domain-level measurement: Accuracy scores are first calculated separately for each individual domain
- Final score calculation: The overall final score is computed as an unweighted average of the accuracy scores across all six domains
Appendix E of the paper goes into greater detail on dataset creation.
Here is the RewardBench-2 dataset. We encourage you to take a look and pay special attention to the chosen vs. rejected responses. Note that in the rejected column, incorrect responses are separated by commas. For every category except Ties, there are 3 rejected responses and 1 correct response. In the Ties category, the number of rejected responses varies.
You may also notice that a number of different models are being used in the models column. The researchers found that RMs tend to prefer completions generated by their own base model and therefore used a pool of models for the different domains.

RewardBench-2 is not like other Reward Model Benchmarks
 The table positions RewardBench 2 as an advancement in RM evaluation. It shows that RewardBench 2 uniquely incorporates “Best-of-N (N > 2)” evaluations, uses “Human Prompts,” and, critically, uses “Unseen Prompts”. The use of unseen human prompts is a significant departure from most prior work, which often repurposes prompts from existing downstream evaluations, and helps to avoid potential contamination with respect to downstream evaluation targets.
The table positions RewardBench 2 as an advancement in RM evaluation. It shows that RewardBench 2 uniquely incorporates “Best-of-N (N > 2)” evaluations, uses “Human Prompts,” and, critically, uses “Unseen Prompts”. The use of unseen human prompts is a significant departure from most prior work, which often repurposes prompts from existing downstream evaluations, and helps to avoid potential contamination with respect to downstream evaluation targets.
Training More Reward Models for Evaluation Purposes
The researchers also trained reward models so that they can analyze the performance of a larger variety of models. These models are available here.
Final Thoughts
The scaling of massive neural networks has taught us that capabilities emerge in unpredictable ways, meaning that theory and “vibes” alone are insufficient. Here, evaluation benchmarks help verify that reward models successfully bridge the gap between objective metrics and complex human preferences, building the trust and reliability necessary as AI systems become more autonomous and influential in real-world applications. The community has already started using RewardBench 2, as seen by the evaluation of eight reward models recently released by Skywork-Reward-V2.Check out Reward Bench 2’s Datasets, Spaces, and Models on Hugging Face!
References and Additional Resources
Reward Bench 2 paper and model card (sources of all images)
Illustrating Reinforcement Learning from Human Feedback (RLHF) from Hugging Face
A short introduction to RLHF and post-training focused on language models from Nathan Lambert"Pankaj Kumar" / 2025-07-12 3 months ago / 未收藏/ DigitalOcean Community Tutorials/
发送到 kindle
Introduction
In this article, we’ll show you how to reliably convert a string to a float in Python using the built-infloat() function. We’ll start with the fundamentals, covering how to handle various formats like integers and scientific notation, before moving on to the most essential skill: writing resilient code. You’ll learn how to use a try-except block to gracefully handle a ValueError from non-numeric input. From there, we’ll tackle practical, real-world challenges like cleaning strings with currency symbols and converting international numbers that use commas as decimals.By the end, you’ll understand the best practices for handling any string-to-float conversion task.
Key takeaways
- Python’s built-in
float()function handles most string-to-float conversions, including integers, decimals, negative numbers, scientific notation, and strings with leading/trailing whitespace. - Wrap
float()conversions intry-exceptblocks to catch ValueError exceptions from invalid strings like"hello"or empty strings, preventing program crashes. - Use string replacement methods (remove commas, replace decimal separators) or Python’s locale module to convert European-style numbers like
"1.234,56"to standard format. float(None)raises aTypeError, notValueError; so explicitly check forNonevalues before attempting conversion to avoid different exception types.- Remove unwanted characters like currency symbols, thousands separators, and whitespace using string methods like
.strip()and.replace()before callingfloat(). - Build utility functions like
safe_to_float()that handle common edge cases (None, empty strings, invalid input) and return sensible defaults to make your code more maintainable and robust.
Understanding String to Float Conversion in Python
In Python, you’ll often encounter data as a string of text, even when it represents a number. For instance, when a user types “19.99” into an input field or you read data from a file, it’s initially treated as text. String to float conversion is the process of turning that text representation of a number into an actual numeric type called a float. This allows you to perform mathematical operations on it.You might wonder why is this conversion so important? Simply put, you can’t do math with text. Trying to add, subtract, or multiply strings like “50.5” and “10.2” will result in an error or unexpected behavior. To treat these values as the numbers they represent, you must first convert them into a numeric type, like a float. This process, known as type casting or type conversion, is a fundamental task in any data-driven application.
This conversion is essential in many real-world scenarios, including:
- Handling User Input: Getting numbers from users for calculations, such as in a tip calculator or a financial application.
- Data Processing: Parsing numerical data from files like CSVs, JSON, or text files where numbers are often stored as strings.
- Web Scraping: Extracting product prices, ratings, or other numerical data from websites, which are always retrieved as text.
- API Integration: Receiving data from external APIs where numerical values are sometimes formatted as strings.
Prerequisites
In order to complete this tutorial, you will need:- Familiarity with basic Python programming. Check out How to Code in Python 3 series or using VS Code for Python for a quick lesson.
How to Use float() for Basic Conversions in Python
Python gives you a straightforward, built-in function to perform this task: float() for Basic Conversions in Pythonfloat(). This function is the primary and most Pythonic way to convert a string into a floating-point number.The syntax is simple. You just pass the string you want to convert inside the parentheses.
float(your_string)
float() function can handle strings that represent positive numbers, negative numbers, and even whole numbers.1. Converting a Standard Numeric String
This is the most common use case: a string containing a number with a decimal.price_string = "24.99"
print("Type before conversion:", type(price_string))
price_float = float(price_string)
print("Type after conversion:", type(price_float))
Type before conversion: <class 'str'>
Type after conversion: <class 'float'>
"24.99" was successfully converted to the float 24.99, and its type is now float.2. Converting a String Representing an Integer or Negative Number
Whether your string represents an integer, or a negative value,float() processes it correctly.# String representing an integer
int_string = "350"
print(f"'{int_string}' becomes: {float(int_string)}")
# String representing a negative decimal
neg_string = "-45.93"
print(f"'{neg_string}' becomes: {float(neg_string)}")
'350' becomes: 350.0
'-45.93' becomes: -45.93
Note: If you are not familiar with string formatting using f prefix, please read f-strings in Python.
3. Handling Leading/Trailing Whitespace
Often, data from files or user input comes with extra spaces. Thankfully,float() automatically handles leading and trailing whitespace.reading_string = " -99.5 "
reading_float = float(reading_string)
print(reading_float)
-99.5
float() function ignored the extra spaces and correctly converted the string to a negative float. In the next section, we’ll cover what happens when you try to convert a string that isn’t a valid number.Converting Scientific Notation
Scientific notation (e-notation) is a way to express very large or very small numbers. Python’sfloat() function understands this format without any extra work.For example, the string
"1.5e10" represents 1.5 times 10 to the power of 10.scientific_string = "1.5e10"
scientific_float = float(scientific_string)
print(f"'{scientific_string}' becomes: {scientific_float}")
print(type(scientific_float))
'1.5e10' becomes: 15000000000.0
<class 'float'>
float() function effortlessly handles these common formats, making your conversion tasks much simpler.
Handling Errors: The ValueError and Safe Conversions
What happens when you try to convert a string that isn’t a number, like ValueError and Safe Conversions"hello" or an empty string ""? If you’re not careful, your program will crash. In this section, we’ll cover how to handle these situations gracefully.Understanding the ValueError Exception
When you pass an invalid string (one that cannot be interpreted as a number) to the float() function, Python raises a ValueError.Let’s see what happens when we try to convert non-numeric text:
invalid_string = "not a number"
price_float = float(invalid_string)
print(price_float)
ValueError with a message telling you it could not convert the string to a float.Using try-except Blocks for Safe Conversion
To prevent crashes, you should wrap your conversion code in a try-except block. This is the standard Pythonic way to handle exceptions in Python.The logic is simple:
- The
tryblock contains the code that might fail (the “risky” operation). - The
exceptblock contains the code that runs only if an error occurs in thetryblock.
ValueError and handle it gracefully instead of letting your program terminate.input_string = "not a number"
value_float = 0.0
try:
value_float = float(input_string)
print("Conversion successful!")
except ValueError:
print(f"Could not convert '{input_string}'.")
print(f"The final float value is: {value_float}")
Could not convert 'not a number'.
The final float value is: 0.0
Handling Empty Strings and None Values
The two most common edge cases are empty strings ("") and None values.- Empty Strings: An empty string is not a valid number, so
float("")will also raise aValueError. Thetry-exceptblock we just created handles this perfectly. NoneValues: Trying to convertNoneis a different kind of error.float(None)will raise aTypeError, not aValueError. If your code encountersNone, you should check for it explicitly before trying the conversion.
None:def safe_to_float(value):
if value is None:
return 0.0
try:
return float(value)
except (ValueError, TypeError):
return 0.0
# Test cases
print(f"'123.45' becomes: {safe_to_float('123.45')}")
print(f"'hello' becomes: {safe_to_float('hello')}")
print(f"An empty string '' becomes: {safe_to_float('')}")
print(f"None becomes: {safe_to_float(None)}")
'123.45' becomes: 123.45
'hello' becomes: 0.0
An empty string '' becomes: 0.0
None becomes: 0.0
Handling International Number Formats
Numeric formats can change depending on the region. In many parts of North America and the UK, a number might be written as 1,234.56. However, in much of Europe and other regions, the roles are swapped, and the same number is written as 1.234,56.Python’s
float() function, by default, only recognizes a period (.) as a decimal separator. Trying to convert "1.234,56" will result in a ValueError. Here are two ways to handle this.1. The String Replacement Method
For most cases, the simplest solution is to manipulate the string to a format that Python understands before you try to convert it. This involves two steps:- Remove the thousands separators.
- Replace the comma decimal separator with a period.
de_string = "1.234,56"
temp_string = de_string.replace(".", "")
standard_string = temp_string.replace(",", ".")
value_float = float(standard_string)
print(f"Original string: '{de_string}'")
print(f"Standardized string: '{standard_string}'")
print(f"Converted float: {value_float}")
'.' thousands separator. Then, we replace the ',' decimal separator with a '.'. Finally, we convert the standardized string.Output:
Original string: '1.234,56'
Standardized string: '1234.56'
Converted float: 1234.56
2. Using the locale Module
For applications that need to handle different international formats dynamically, Python’s locale module is the right tool. This module can interpret numbers according to a specific region’s conventions.To use it, you first set the “locale” (region) and then use the
locale.atof() function (ASCII to float) for the conversion.import locale
de_string = "1.234,56"
try:
locale.setlocale(locale.LC_NUMERIC, 'de_DE.UTF-8')
value_float = locale.atof(de_string)
print(f"Successfully converted '{de_string}' to {value_float}")
except locale.Error:
print("Locale 'de_DE.UTF-8' not supported on this system.")
finally:
locale.setlocale(locale.LC_NUMERIC, '')
German (de_DE) with UTF-8 encoding.
Note: The
Then, we use 'de_DE.UTF-8' locale must be supported by your OS.locale.atof() to convert the string in a locale-aware way.Output:
Successfully converted '1.234,56' to 1234.56
locale module is the more robust and “correct” solution for building internationalized applications. For quick, one-off scripts, the string replacement method is often sufficient.
Best Practices
To ensure your code is robust, readable, and error-free, keep these best practices in mind when converting strings to floats in Python.- Always Wrap External Input in a
try-exceptBlock: This is the most critical rule. Data from users, files, or APIs is unpredictable. Atry-except ValueErrorblock will prevent your program from crashing due to a single invalid string and allow you to handle the error gracefully. - Clean Your Strings Before Conversion: Don’t pass messy strings directly to
float(). First, use string methods like.strip()to remove leading/trailing whitespace and.replace()to eliminate unwanted characters. For more advanced cleaning, you can review our article on common string manipulation techniques. - Assign a Sensible Default Value: When a conversion fails inside an
exceptblock, decide on a fallback plan. Is it better to skip the entry, or should you assign a default value like0.0orNone? This ensures your program can continue running with predictable data. - Create a Helper Function for Repetitive Conversions: If you perform the same conversion logic in multiple places, encapsulate it in a reusable function (like the
safe_to_float()example earlier). This makes your code cleaner, easier to read, and simpler to update. - Be Aware of International Number Formats: If your application processes data from different parts of the world, remember that decimal separators can be commas instead of periods. Use the string replacement method for simple cases or the
localemodule for more complex, locale-aware applications. - Stick with
float()for Simplicity: For all standard conversions, the built-infloat()function is the most direct, readable, and Pythonic tool for the job. Avoid overly complex solutions when a simple one works perfectly.
Frequently Asked Questions (FAQs)
1. How do I convert a string to float in Python?
The simplest way is to use Python’s built-infloat() function. You pass the numeric string as an argument, and it returns the corresponding float.For example,
float("123.45") will return 123.45.2. What happens if the string isn’t a valid float?
Python raises aValueError exception when you attempt to convert a non-numeric string using float(). For example, float("hello") will throw a ValueError: could not convert string to float: hello. Always use try-except blocks to handle this gracefully.3. How do I convert a string with commas like “1,234.56”?
Python’sfloat() function doesn’t recognize comma separators by default. You need to remove commas first: float("1,234.56".replace(",", "")) or use locale-specific functions like locale.atof() after setting the appropriate locale.4. How to convert string to a float with 2 decimal in Python?
You can’t directly convert a string to a float with a specific number of decimal places. It’s a two-step process: you first convert the string to a float, then format that float to two decimal places.- For Display (Get a String): Use an f-string with the
:.2fformat specifier. This is best for printing or showing the value in a UI.
price_string = "49.99123"
formatted_price = f"{float(price_string):.2f}"
print(formatted_price)
# Output: "49.99"
- For Calculation (Get a Float): Use the built-in
round()function. This is best if you need to use the rounded number in further math operations.
price_string = "49.99123"
rounded_price = round(float(price_string), 2)
print(rounded_price)
# Output: 49.99
5. What’s the difference between float() and int() when converting strings?
float() converts strings to floating-point numbers (decimals), while int() converts to integers. float("3.14") returns 3.14, but int("3.14") raises a ValueError. Use int(float("3.14")) to convert decimal strings to integers. This will return 3.6. How do I handle scientific notation strings like “1.5e10”?
Python’sfloat() function natively supports scientific notation. float("1.5e10") correctly returns 15000000000.0. This works for both positive and negative exponents like "1.5e-3".
Conclusion
In this article, you’ve learned how to reliably convert strings to floats in Python, a fundamental skill for handling real-world data.We started with the basics, using the built-in
float() function to handle simple numeric strings, integers, and scientific notation. We then moved to the most critical aspect of robust programming: safely handling errors. You now know how to use a try-except block to catch a ValueError, ensuring your applications don’t crash when they encounter unexpected, non-numeric text.Finally, we tackled practical, advanced scenarios. You can now clean strings by removing unwanted characters such as currency symbols, commas, whitespaces, and thousands separators, and you have the tools to correctly process international number formats that use commas as decimals. With these skills, you’re now equipped to write more versatile Python code that can handle the messy, unpredictable data you’ll encounter in any project.
To learn more about Python strings, check out the following articles:
- How To Convert Data Types in Python 3
- How to Concatenate String and Int in Python (With Examples)
- How to Receive User Input in Python: A Beginner’s Guide
- Python Compare Strings - Methods & Best Practices
References:
"Vinayak Baranwal" / 2025-07-12 3 months ago / 未收藏/ DigitalOcean Community Tutorials/
发送到 kindle
JavaScript charting libraries have become essential tools for modern web development, enabling developers to create powerful data visualizations that drive insights and decision-making. Whether you’re building business dashboards, analyzing scientific data, or explaining AI model behavior, the right charting library can transform complex datasets into clear, interactive stories.
In this tutorial, we will explore five leading JavaScript charting libraries - Chart.js for simplicity, D3.js for complete customization, ECharts for enterprise needs, ApexCharts for modern dashboards, and Plotly.js for scientific visualization. We’ll help you understand their strengths and use cases so you can choose the best tool for your specific requirements.
JavaScript chart libraries are tools that make it easy to create charts and graphs on websites. Instead of drawing everything from scratch with code, you can use these libraries to quickly build bar charts, line charts, pie charts, and even more advanced charts like heatmaps or 3D graphs. They handle the hard work behind the scenes, so you don’t need to know how to use Canvas or SVG directly. Most chart libraries also let you add interactive features (like tooltips or clicking on data points) and work well with popular web frameworks, making them a great choice for adding data visualizations to your projects.
When evaluating JavaScript chart libraries, it’s important to consider a range of features that impact usability, performance, and integration. The following core aspects distinguish leading libraries and should guide your selection process, especially as your project’s requirements grow in complexity or scale.
Interactivity:
Top chart libraries excel at providing interactive experiences for users. This includes features like tooltips that appear on hover, zooming and panning to explore data, and filtering to focus on specific subsets. D3.js, for instance, allows developers to craft highly customized interactions by directly handling events, while ApexCharts comes with built-in options for zooming and brush selection, making it easy to add interactivity without much extra code.
Responsiveness:
In today’s mobile-first landscape, charts must look good and function well on any device. Leading libraries such as Chart.js and ECharts automatically adjust their size and layout based on the container or screen, using CSS and JavaScript resize observers. This ensures that charts remain legible and visually appealing whether viewed on a desktop monitor or a smartphone, reducing the need for manual adjustments and improving user experience across platforms.
Ease of Use:
The ease with which you can get started and build charts varies between libraries. Chart.js is known for its straightforward, declarative API and sensible defaults, allowing developers to quickly prototype and deploy charts with minimal setup. In contrast, D3.js has a steeper learning curve, requiring a solid understanding of data binding and SVG manipulation, but it rewards this investment with unmatched flexibility for creating custom visualizations.
Performance:
Handling large datasets or real-time data streams demands efficient rendering. Canvas-based libraries like Chart.js and ApexCharts typically offer better raw rendering speed than SVG-based solutions such as D3.js, especially when dealing with thousands of data points. However, D3.js stands out for its ability to efficiently process and transform complex data, making it suitable for advanced data manipulation tasks even if rendering is not always as fast.
Framework Compatibility:
Seamless integration with modern JavaScript frameworks is essential for many projects. Chart.js and ApexCharts provide official wrappers for frameworks like React, Vue, and Angular, simplifying their use in component-based architectures. D3.js, on the other hand, is more commonly integrated manually, giving developers fine grained control but requiring more effort to manage chart lifecycles within frameworks such as React or SolidJS.
Customizability:
The ability to customize the appearance and behavior of charts is a key differentiator. ECharts, for example, offers a rich set of declarative configuration options for themes, animations, legends, and tooltips, making it easy to match your application’s style. Plotly.js goes further by supporting intricate, interactive 3D plots with a wide range of customizable controls, catering to specialized visualization needs.
Accessibility:
Ensuring that charts are accessible to all users is increasingly important. This involves supporting ARIA standards, providing keyboard navigation, and maintaining sufficient color contrast. While libraries like Chart.js offer basic ARIA support out of the box, others may require developers to implement additional accessibility features to achieve full compliance, ensuring that visualizations are usable by people with disabilities.
Open Source Licensing:
Understanding the licensing of a chart library is crucial, especially for commercial or enterprise projects. Libraries with permissive licenses such as MIT or Apache 2.0 allow for broad use and encourage community contributions. Being aware of licensing terms helps prevent legal issues down the line and ensures that your chosen library aligns with your organization’s policies and future plans.
Choosing the right JavaScript charting library can be tricky. Here’s a quick comparison of the top options to help you decide.

Note: This image summarizes the strengths of the most popular JavaScript charting libraries which is ideal for quick visual comparison.
Each feature listed is grounded in practical scenarios. For instance, Chart.js’s ease of use is demonstrated by its minimal setup and declarative configuration, suitable for quick dashboards.
For a full guide on using Chart.js in Angular projects, refer to our guide on Angular + Chart.js tutorial, or explore Vue.js with Chart.js for Vue integration examples.
Note: If you want to run this Chart.js example directly in your browser, wrap it inside a complete HTML document and include the Chart.js library using a
Example:
.png)
Key Considerations: Chart.js uses Canvas rendering, which improves performance for moderate datasets but limits per-element DOM manipulation. Its plugin architecture allows extending functionality, and options provide granular control over responsiveness and animations.
Note: Chart.js may struggle with very large datasets (e.g., >10,000 points). For optimal performance, consider manually throttling real-time updates and minimizing redraws to avoid frame drops.
Note: If you want to run this D3.js example in your browser, make sure to include the D3 library using a
Example:
.png)
Key Considerations: D3.js offers unparalleled flexibility by manipulating the DOM directly, enabling custom transitions, scales, and axes.
Note: SVG rendering in D3.js can become sluggish when visualizing thousands of elements. To maintain smooth performance, consider using techniques like virtual scrolling or switching to Canvas rendering for large datasets.
Note: To run this ECharts example in a browser, make sure you include the ECharts library using a
Example:

Key Considerations: ECharts supports Canvas rendering with built-in interactions like data zoom, brushing, and toolboxes for exporting, while its JSON-based configuration enables rapid customization without imperative code.
Note: Complex charts with many series can increase memory usage in ECharts. Ensure you properly dispose of chart instances to avoid memory leaks, especially in single-page applications.
If you’re working with SolidJS, here’s a complete tutorial on How to add Charts to SolidJS using ApexCharts that walks through real implementation.
Example:

Key Considerations: ApexCharts leverages SVG and Canvas hybrid rendering for smooth animations and responsive layouts. It provides built-in support for real-time updates and integrates well with popular frameworks.
Note: While ApexCharts’ animations enhance visual appeal, using them on large datasets may degrade performance. Consider disabling animations or limiting data points to maintain smooth rendering.
Example:

Key Considerations: Plotly.js supports WebGL-accelerated 3D charts, complex statistical plots, and uses a declarative JSON syntax that simplifies defining multi-dimensional data.
Note: Plotly.js has a relatively large bundle size, which may slow initial load times. For simple use cases, this overhead might be unnecessary. Additionally, WebGL support can vary across browsers and devices.
The choice of the best JavaScript charting library mainly depends on the complexity of your project, its performance needs and resources of the development team. Chart.js and ApexCharts are easy to use and responsive, which is a requirement by beginners and dashboard-driven applications. Serious end-users in need of custom visualizations would be well advised to lean on the flexibility that D3.js offers. ECharts is a powerful middle ground with solid enterprise capabilities whereas Plotly.js is a scientific and 3D visualization.
No single library is universally perfect. The right choice is the one that fits your specific data, audience, and development workflow.
Still deciding which library to use?
Test libraries with your real-world datasets and workflows, and explore community examples to inform your choice.
Want to go deeper? Sharpen your fundamentals with our comprehensive JavaScript Coding Series.
In this tutorial, we will explore five leading JavaScript charting libraries - Chart.js for simplicity, D3.js for complete customization, ECharts for enterprise needs, ApexCharts for modern dashboards, and Plotly.js for scientific visualization. We’ll help you understand their strengths and use cases so you can choose the best tool for your specific requirements.
Key Takeaways
- Quick wins: Chart.js and ApexCharts are ideal for dashboards that need rapid, out‑of‑the‑box results.
- Performance matters: Canvas‑based libraries handle large datasets better; always throttle real‑time updates and test on mobile.
- Custom Visualization Engine: D3.js is the go-to tool for developers who need total design freedom and logic-driven visuals.
- Enterprise muscle: ECharts delivers rich features and blazing performance for large‑scale apps, while Plotly.js excels at scientific and 3‑D plots.
- Choose wisely: Library choice hinges on chart complexity, dataset size, performance, and UX requirements.
Prerequisites
- General knowledge on how to work with HTML, CSS, and JS (ES6+).
- A code editor (like VS Code or Cursor) and a Browser with DevTools.
- Node.js (LTS) and a package manager like npm, Yarn, bun or pnpm.
- Optional but helpful: a bundler/build tool (Vite, Webpack, or Rollup).
- A sample dataset (CSV or JSON) to experiment with while following this guide.
What is a JavaScript Chart Library?
JavaScript chart libraries are tools that make it easy to create charts and graphs on websites. Instead of drawing everything from scratch with code, you can use these libraries to quickly build bar charts, line charts, pie charts, and even more advanced charts like heatmaps or 3D graphs. They handle the hard work behind the scenes, so you don’t need to know how to use Canvas or SVG directly. Most chart libraries also let you add interactive features (like tooltips or clicking on data points) and work well with popular web frameworks, making them a great choice for adding data visualizations to your projects.
What are the core features of top JavaScript chart libraries?
When evaluating JavaScript chart libraries, it’s important to consider a range of features that impact usability, performance, and integration. The following core aspects distinguish leading libraries and should guide your selection process, especially as your project’s requirements grow in complexity or scale.Interactivity:
Top chart libraries excel at providing interactive experiences for users. This includes features like tooltips that appear on hover, zooming and panning to explore data, and filtering to focus on specific subsets. D3.js, for instance, allows developers to craft highly customized interactions by directly handling events, while ApexCharts comes with built-in options for zooming and brush selection, making it easy to add interactivity without much extra code.
Responsiveness:
In today’s mobile-first landscape, charts must look good and function well on any device. Leading libraries such as Chart.js and ECharts automatically adjust their size and layout based on the container or screen, using CSS and JavaScript resize observers. This ensures that charts remain legible and visually appealing whether viewed on a desktop monitor or a smartphone, reducing the need for manual adjustments and improving user experience across platforms.
Ease of Use:
The ease with which you can get started and build charts varies between libraries. Chart.js is known for its straightforward, declarative API and sensible defaults, allowing developers to quickly prototype and deploy charts with minimal setup. In contrast, D3.js has a steeper learning curve, requiring a solid understanding of data binding and SVG manipulation, but it rewards this investment with unmatched flexibility for creating custom visualizations.
Performance:
Handling large datasets or real-time data streams demands efficient rendering. Canvas-based libraries like Chart.js and ApexCharts typically offer better raw rendering speed than SVG-based solutions such as D3.js, especially when dealing with thousands of data points. However, D3.js stands out for its ability to efficiently process and transform complex data, making it suitable for advanced data manipulation tasks even if rendering is not always as fast.
Framework Compatibility:
Seamless integration with modern JavaScript frameworks is essential for many projects. Chart.js and ApexCharts provide official wrappers for frameworks like React, Vue, and Angular, simplifying their use in component-based architectures. D3.js, on the other hand, is more commonly integrated manually, giving developers fine grained control but requiring more effort to manage chart lifecycles within frameworks such as React or SolidJS.
Customizability:
The ability to customize the appearance and behavior of charts is a key differentiator. ECharts, for example, offers a rich set of declarative configuration options for themes, animations, legends, and tooltips, making it easy to match your application’s style. Plotly.js goes further by supporting intricate, interactive 3D plots with a wide range of customizable controls, catering to specialized visualization needs.
Accessibility:
Ensuring that charts are accessible to all users is increasingly important. This involves supporting ARIA standards, providing keyboard navigation, and maintaining sufficient color contrast. While libraries like Chart.js offer basic ARIA support out of the box, others may require developers to implement additional accessibility features to achieve full compliance, ensuring that visualizations are usable by people with disabilities.
Open Source Licensing:
Understanding the licensing of a chart library is crucial, especially for commercial or enterprise projects. Libraries with permissive licenses such as MIT or Apache 2.0 allow for broad use and encourage community contributions. Being aware of licensing terms helps prevent legal issues down the line and ensures that your chosen library aligns with your organization’s policies and future plans.
What Are the Top JavaScript Charting Libraries?
Choosing the right JavaScript charting library can be tricky. Here’s a quick comparison of the top options to help you decide.| Library | Best For | Features | Framework Support |
|---|---|---|---|
| Chart.js | Rapid development of simple to moderate complexity dashboards | Standard interactions like tooltips and zoom | React, Vue, Angular (official wrappers) |
| D3.js | Highly customized, data driven visualizations with complex logic | Full control over DOM and event handling | All frameworks (manual integration) |
| ECharts | Enterprise grade dashboards requiring rich features and performance | Advanced interactions including data zoom, brush, and toolbox | React, Vue (official) |
| ApexCharts | Real time data visualization with modern styling and smooth animations | Built-in zoom, pan, and responsive legends | React, Vue, Angular (official) |
| Plotly.js | Scientific and 3D visualizations with interactive controls | Interactive 3D plots, hover info, and zoom | React (official) |
Note: This image summarizes the strengths of the most popular JavaScript charting libraries which is ideal for quick visual comparison.
Each feature listed is grounded in practical scenarios. For instance, Chart.js’s ease of use is demonstrated by its minimal setup and declarative configuration, suitable for quick dashboards.
How to Implement Charting Libraries in JavaScript?
Chart.js
Chart.js is one of the easiest libraries to get started with just include the library, add a canvas element, and configure your chart with a simple JavaScript object. It’s ideal for quickly creating interactive charts with minimal code.For a full guide on using Chart.js in Angular projects, refer to our guide on Angular + Chart.js tutorial, or explore Vue.js with Chart.js for Vue integration examples.
Note: If you want to run this Chart.js example directly in your browser, wrap it inside a complete HTML document and include the Chart.js library using a
<script src="https://cdn.jsdelivr.net/npm/chart.js"></script> tag in the <head>. Running it without this will result in a ReferenceError: Chart is not defined.Example:
const ctx = document.getElementById('myChart').getContext('2d');
const myChart = new Chart(ctx, {
type: 'bar',
data: {
labels: ['Red', 'Blue', 'Yellow', 'Green', 'Purple', 'Orange'],
datasets: [{
label: '# of Votes',
data: [12, 19, 3, 5, 2, 3],
backgroundColor: 'rgba(54, 162, 235, 0.6)'
}]
},
options: {
responsive: true,
plugins: {
legend: { display: true },
tooltip: { enabled: true }
}
}
});
Key Considerations: Chart.js uses Canvas rendering, which improves performance for moderate datasets but limits per-element DOM manipulation. Its plugin architecture allows extending functionality, and options provide granular control over responsiveness and animations.
Note: Chart.js may struggle with very large datasets (e.g., >10,000 points). For optimal performance, consider manually throttling real-time updates and minimizing redraws to avoid frame drops.
D3.js
D3.js (Data-Driven Documents) is a powerful JavaScript library for building complex, interactive data visualizations using SVG, Canvas, and HTML. It gives developers full control over every element on the page, making it ideal for custom, dynamic charts.Note: If you want to run this D3.js example in your browser, make sure to include the D3 library using a
<script src="https://d3js.org/d3.v7.min.js"></script> tag in your HTML <head>. This code should be placed inside a <script> tag within an HTML document that also contains an element like <svg id="mySvg"></svg> in the body. Running it without these will lead to ReferenceError: d3 is not defined or selection errors.Example:
const data = [12, 19, 3, 5, 2, 3];
const svg = d3.select('#mySvg').attr('width', 400).attr('height', 200);
svg.selectAll('rect')
.data(data)
.enter()
.append('rect')
.attr('x', (d, i) => i * 40)
.attr('y', d => 200 - d * 10)
.attr('width', 35)
.attr('height', d => d * 10)
.attr('fill', 'steelblue');
Key Considerations: D3.js offers unparalleled flexibility by manipulating the DOM directly, enabling custom transitions, scales, and axes.
Note: SVG rendering in D3.js can become sluggish when visualizing thousands of elements. To maintain smooth performance, consider using techniques like virtual scrolling or switching to Canvas rendering for large datasets.
ECharts
ECharts is a high-performance, feature-rich charting library developed by Apache, known for its interactive dashboards and powerful data exploration tools.Note: To run this ECharts example in a browser, make sure you include the ECharts library using a
<script src="https://cdn.jsdelivr.net/npm/echarts@5/dist/echarts.min.js"></script> tag inside your HTML <head>. The chart code should be placed in a <script> block, and your HTML body must contain a container element like <div id="main" style="width: 600px;height:400px;"></div>. Without these, you may encounter echarts is not defined or rendering issues.Example:
const chart = echarts.init(document.getElementById('main'));
const option = {
xAxis: { type: 'category', data: ['Mon', 'Tue', 'Wed', 'Thu', 'Fri'] },
yAxis: { type: 'value' },
series: [{
data: [120, 200, 150, 80, 70],
type: 'bar'
}],
tooltip: { trigger: 'axis' },
toolbox: { feature: { saveAsImage: {} } }
};
chart.setOption(option);
Key Considerations: ECharts supports Canvas rendering with built-in interactions like data zoom, brushing, and toolboxes for exporting, while its JSON-based configuration enables rapid customization without imperative code.
Note: Complex charts with many series can increase memory usage in ECharts. Ensure you properly dispose of chart instances to avoid memory leaks, especially in single-page applications.
ApexCharts
ApexCharts delivers smooth, real-time charts with easy integration and minimal config perfect for fast-paced dashboard development.If you’re working with SolidJS, here’s a complete tutorial on How to add Charts to SolidJS using ApexCharts that walks through real implementation.
Note: To run this ApexCharts example in your browser, ensure you include the ApexCharts library using a <script src="https://cdn.jsdelivr.net/npm/apexcharts"></script> tag inside the HTML <head>. The chart code should go inside a <script> tag in the body, and your HTML must contain a container element such as <div id="chart"></div>. Without these, you may encounter ApexCharts is not defined or empty chart containers.
Example:
var options = {
chart: { type: 'line', height: 350 },
series: [{ name: 'Sales', data: [30, 40, 35, 50, 49, 60] }],
xaxis: { categories: ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun'] },
tooltip: { enabled: true },
responsive: [{ breakpoint: 480, options: { chart: { height: 300 } } }]
};
var chart = new ApexCharts(document.querySelector("#chart"), options);
chart.render();
Key Considerations: ApexCharts leverages SVG and Canvas hybrid rendering for smooth animations and responsive layouts. It provides built-in support for real-time updates and integrates well with popular frameworks.
Note: While ApexCharts’ animations enhance visual appeal, using them on large datasets may degrade performance. Consider disabling animations or limiting data points to maintain smooth rendering.
Plotly.js
Plotly.js is a high-level charting library known for its ability to render scientific, statistical, and 3D visualizations with ease. It supports both WebGL and SVG rendering, offering rich interactivity and clean aesthetics out of the box.
Note: To run this Plotly.js example in your browser, include the Plotly library using a <script src="https://cdn.plot.ly/plotly-latest.min.js"></script> tag in the HTML <head>. Place your chart code inside a <script> block in the body, and ensure you have a container element such as <div id="plot"></div>. Without this setup, you may encounter Plotly is not defined or rendering issues.
Example:
var data = [{
x: [1, 2, 3, 4],
y: [10, 15, 13, 17],
type: 'scatter'
}];
Plotly.newPlot('plot', data);
Key Considerations: Plotly.js supports WebGL-accelerated 3D charts, complex statistical plots, and uses a declarative JSON syntax that simplifies defining multi-dimensional data.
Note: Plotly.js has a relatively large bundle size, which may slow initial load times. For simple use cases, this overhead might be unnecessary. Additionally, WebGL support can vary across browsers and devices.
FAQs and Common Mistakes to Avoid
1. What causes performance issues in JavaScript charts?**
Performance problems often stem from unnecessary re-renders or frequent reinitialization of chart instances, especially with rapidly updating data. To avoid lag, use throttling or debouncing to limit update frequency. Prefer Canvas rendering over SVG for large datasets, and offload heavy computations to Web Workers when possible.2. How do I make my charts responsive across devices?
Avoid fixed pixel dimensions for chart containers, as these can break layouts on mobile devices. Use relative sizing (percentages), CSS media queries, and libraries with native responsiveness (like Chart.js or ApexCharts). Always test across devices and consider maintaining aspect ratios.3. What are common accessibility mistakes with charts, and how can I address them?
Failing to provide ARIA labels, descriptions, or keyboard navigation can make charts inaccessible. Always add appropriate ARIA attributes, ensure sufficient color contrast, enable keyboard navigation, and offer alternative data representations like tables or summaries.4. Is it okay to display very large or complex datasets in a single chart?
Overloading charts with too much data or excessive complexity can overwhelm users and degrade performance. Implement data aggregation or sampling to reduce rendered points, use Canvas-based libraries for better performance, and consider server-side processing or virtualization for extremely large datasets. Sometimes, summarizing data or using tables for details is more effective.5. What should I watch out for when updating chart data?
Yes. Not testing charts across browsers and devices can lead to unexpected rendering issues. Neglecting to optimize for large datasets (e.g., by using Canvas rendering or data sampling) can result in sluggish charts. Also, not cleaning up chart instances when integrating with frameworks (like React or Vue) can cause memory leaks—always clean up on component unmount.
Conclusion
The choice of the best JavaScript charting library mainly depends on the complexity of your project, its performance needs and resources of the development team. Chart.js and ApexCharts are easy to use and responsive, which is a requirement by beginners and dashboard-driven applications. Serious end-users in need of custom visualizations would be well advised to lean on the flexibility that D3.js offers. ECharts is a powerful middle ground with solid enterprise capabilities whereas Plotly.js is a scientific and 3D visualization.No single library is universally perfect. The right choice is the one that fits your specific data, audience, and development workflow.
Still deciding which library to use?
Test libraries with your real-world datasets and workflows, and explore community examples to inform your choice.
Want to go deeper? Sharpen your fundamentals with our comprehensive JavaScript Coding Series.
Further Reading
- Angular Chart.js with ng2-charts → - Learn how to integrate Chart.js with Angular using the ng2-charts wrapper library for dynamic data visualization
- Add Charts to SolidJS with ApexCharts → - Build interactive charts and graphs in SolidJS applications using the powerful ApexCharts library
- Creating Tables in HTML → - Master the fundamentals of creating and styling data tables in HTML for structured content presentation
- JavaScript Coding Series → - A comprehensive guide covering JavaScript fundamentals, advanced concepts, and best practices for modern web development
"Amit Jotwani" / 2025-07-12 3 months ago / 未收藏/ DigitalOcean Community Tutorials/
发送到 kindle
DigitalOcean recently launched Serverless Inference - a hosted API that lets you run large language models like Claude, GPT-4o, LLaMA 3, and Mistral, without managing infrastructure.
It’s built to be simple: no GPU provisioning, no server configuration, no scaling logic to manage. You just send a request to an endpoint.
The API works with models from Anthropic, OpenAI, Meta, Mistral, Deep Seek, and others - all available behind a single base URL.
The best part is that it’s API-compatible with OpenAI.
That means if you’re already using tools like the OpenAI Python SDK, LangChain, or LlamaIndex, or any of the supported models, they’ll just work. You can swap the backend without rewriting your application.
This same approach works with DigitalOcean Agents too — models that are connected to your own documents or knowledge base.

There are a few reasons this approach stands out—especially if you’re already building on DigitalOcean or want more flexibility in how you use large language models.
Under the hood, everything runs through the OpenAI method:
The only thing you need to change is the
Run the following command to install the OpenAI SDK to your machine:
This lists all available models from DigitalOcean Inference. Same code you’d use with OpenAI—you’re just pointing it at a DigitalOcean endpoint (
We’re using the same
Want a response that streams back token by token? Just add
DigitalOcean also offers Agents - these are LLMs paired with a custom knowledge base. You can upload docs, add URLs, include structured content, connect a DigitalOcean Spaces bucket or even an Amazon S3 bucket as a data source. The agent will then respond with that context in mind. It’s great for internal tools, documentation bots, or domain-specific assistants.
You still use

This is a standard Agent request using
The only real change is the
Here we’ve also added
The only change here is that we’ve enabled
To recap:
It’s built to be simple: no GPU provisioning, no server configuration, no scaling logic to manage. You just send a request to an endpoint.
The API works with models from Anthropic, OpenAI, Meta, Mistral, Deep Seek, and others - all available behind a single base URL.
The best part is that it’s API-compatible with OpenAI.
That means if you’re already using tools like the OpenAI Python SDK, LangChain, or LlamaIndex, or any of the supported models, they’ll just work. You can swap the backend without rewriting your application.
This same approach works with DigitalOcean Agents too — models that are connected to your own documents or knowledge base.
Why Use DigitalOcean Inference?
There are a few reasons this approach stands out—especially if you’re already building on DigitalOcean or want more flexibility in how you use large language models.- One key for everything: You don’t have to manage separate keys for OpenAI, Anthropic, Mistral, etc. One DigitalOcean API key gives you access to every model—Claude, GPT-4o, LLaMA 3, Mistral, and more.
- Lower costs: For many workloads, this is significantly more cost-effective than going direct to the provider.
- Unified billing: All your usage shows up in one place. Everything shows up in your DO bill, alongside your apps, spaces, databases, whatever else you’re running on DO. No surprise charges across different platforms.
- Privacy for open models: If you’re using open-weight models (like LLaMA or Mistral), your prompts and completions aren’t logged or used for training.
- *No SDK changes: The OpenAI SDK just works. You can also use libraries like LangChain or LlamaIndex the same way—just change the base URL.
How it Works
Under the hood, everything runs through the OpenAI method:client.chat.completions.create()The only thing you need to change is the
base_url when you initialize the client- Serverless Inference (for general models):
https://inference.do-ai.run/v1/ - Agents (for context-aware inferencing over your own data):
https://.agents.do-ai.run/api/v1/
Install the OpenAI SDK
Run the following command to install the OpenAI SDK to your machine:pip install openai python-dotenv
Example 1: List Available Models
This lists all available models from DigitalOcean Inference. Same code you’d use with OpenAI—you’re just pointing it at a DigitalOcean endpoint (base_url).from openai import OpenAI
from dotenv import load_dotenv
import os
load_dotenv()
client = OpenAI(
base_url="https://inference.do-ai.run/v1/", # DO's Inference endpoint
api_key=os.getenv("DIGITAL_OCEAN_MODEL_ACCESS_KEY")
)
# List all available models
try:
models = client.models.list()
print("Available models:")
for model in models.data:
print(f"- {model.id}")
except Exception as e:
print(f"Error listing models: {e}")
Example 2: Run a Simple Chat Completion
We’re using the same .chat.completions.create() method. Only the base_url is different.from openai import OpenAI
from dotenv import load_dotenv
import os
load_dotenv()
client = OpenAI(
base_url="https://inference.do-ai.run/v1/", # DO's Inference endpoint
api_key=os.getenv("DIGITAL_OCEAN_MODEL_ACCESS_KEY")
)
# Run a simple chat completion
try:
response = client.chat.completions.create(
model="llama3-8b-instruct", # Swap in any supported model
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me a fun fact about octopuses."}
]
)
print(response.choices[0].message.content)
except Exception as e:
print(f"Error during completion: {e}")
Example 3: Stream a Response
Want a response that streams back token by token? Just add stream=True, and loop through the chunks.from openai import OpenAI
from dotenv import load_dotenv
import os
load_dotenv()
client = OpenAI(
base_url="https://inference.do-ai.run/v1/", # DO's Inference endpoint
api_key=os.getenv("DIGITAL_OCEAN_MODEL_ACCESS_KEY")
)
# Run a simple chat completion with streaming
try:
stream = client.chat.completions.create(
model="llama3-8b-instruct", # Swap in any supported model
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me a fun fact about octopuses."}
],
stream=True
)
for event in stream:
if event.choices[0].delta.content is not None:
print(event.choices[0].delta.content, end='', flush=True)
print() # Add a newline at the end
except Exception as e:
print(f"Error during completion: {e}")
What about Agents?
DigitalOcean also offers Agents - these are LLMs paired with a custom knowledge base. You can upload docs, add URLs, include structured content, connect a DigitalOcean Spaces bucket or even an Amazon S3 bucket as a data source. The agent will then respond with that context in mind. It’s great for internal tools, documentation bots, or domain-specific assistants.You still use
.chat.completions.create() — the only difference is the base_url. But now your responses are grounded in your own data.
Note: With Inference, the base URL is fixed. With Agents, it’s unique to your agent, and you append /api/v1.
python
client = OpenAI(
base_url="https://your-agent-id.agents.do-ai.run/api/v1/",
api_key=os.getenv("DIGITAL_OCEAN_MODEL_ACCESS_KEY")
)
Example 4: Use an Agent (No Stream)
This is a standard Agent request using .chat.completions.create() - same method as before.The only real change is the
base_url, which points to your Agent’s unique endpoint (plus /api/v1). With Inference, the base URL is fixed. With Agents, it’s unique to your agent, and you just append /api/v1 to it.Here we’ve also added
include_retrieval_info=True to the body. This tells the API to return extra metadata about what the Agent pulled from your knowledge base to generate its response.from openai import OpenAI
from dotenv import load_dotenv
import os
import json
load_dotenv()
try:
# Create a new client with the agents endpoint
agents_client = OpenAI(
base_url="https://rrp247s4dgv4xoexd2sk62yq.agents.do-ai.run/api/v1/",
api_key=os.getenv("AJOT_AGENT_KEY")
)
# Try a simple text request with the agents endpoint
stream = agents_client.chat.completions.create(
model="openai-gpt-4o-mini",
messages=[{
"role": "user",
"content": "Hello! WHo is Amit?"
}],
extra_body = {"include_retrieval_info": True}
)
print(f"\nAgents endpoint response: {agents_response.choices[0].message.content}")
for choice in response.choices:
print(choice.message.content)
response_dict = response.to_dict()
print("\nFull retrieval object:")
print(json.dumps(response_dict["retrieval"], indent=2))
except Exception as e:
print(f"Error with agents endpoint: {e}")
Example 5: Use an Agent (With Streaming and Retrieval)
The only change here is that we’ve enabled stream=True to get the response back as it generates. Everything else is the same.from openai import OpenAI
from dotenv import load_dotenv
import os
import json
load_dotenv()
try:
# Create a new client with the agents endpoint
agents_client = OpenAI(
base_url="https://rrp247s4dgv4xoexd2sk62yq.agents.do-ai.run/api/v1/",
api_key=os.getenv("AJOT_AGENT_KEY")
)
# Try a simple text request with the agents endpoint
stream = agents_client.chat.completions.create(
model="openai-gpt-4o-mini",
messages=[{
"role": "user",
"content": "Hello! WHo is Amit?"
}],
extra_body = {"include_retrieval_info": True},
stream=True,
)
for event in stream:
if event.choices[0].delta.content is not None:
print(event.choices[0].delta.content, end='', flush=True)
print() # Add a newline at the end
except Exception as e:
print(f"Error with agents endpoint: {e}")
Conclusion
To recap:- You can use the OpenAI SDK directly with DigitalOcean’s Serverless Inference and Agents.
- The only thing you need to change is the base_url—everything else stays the same.
- Use
https://inference.do-ai.run/v1/for general-purpose models like LLaMA 3, GPT-4o, Claude, etc.\ - Use your Agent’s URL (plus
/api/v1) to connect to your own docs or knowledge base. - Everything runs through
.chat.completions.create()—no new methods to learn. - You can enable streaming with
stream=True, and get retrieval info withinclude_retrieval_info=True.
Further Resources
- What is Serverless Inference?: A simple overview of how Serverless Inference works and where it fits.
- How to Use Serverless Inference: Documentation for Serverless Inference
- List of Supported Models: Full breakdown of all models available (OpenAI, Claude, LLaMA, Mistral, etc.).
- Create and Configure a DigitalOcean Agent: Walkthrough for building agents that respond using your own knowledge base.
- Inference API Reference: Schema, endpoints, and everything under the hood.
- OpenAI Python SDK: The official SDK this entire guide is built on.
"Anish Singh Walia" / 2025-07-12 3 months ago / 未收藏/ DigitalOcean Community Tutorials/
发送到 kindle
Introduction
A priority queue is a data structure that stores elements with assigned priorities and allows you to efficiently retrieve the element with the highest (or lowest) priority. In Python, you have several options for implementing priority queues:- The
heapqmodule provides a fast and memory-efficient implementation of a min-heap priority queue - For thread-safe applications, the
queue.PriorityQueueclass offers a synchronized wrapper aroundheapq - You can create a max-heap by either:
- Inverting priorities (using negative values)
- Implementing a custom class with the
__lt__comparison method
Key Takeaways
After reading this tutorial, you will be able to:- Understand what a priority queue is and how it differs from regular queues
- Implement a basic priority queue using Python’s built-in
heapqmodule - Create thread-safe priority queues with the
queue.PriorityQueueclass - Build both min-heap and max-heap priority queues through priority inversion
- Develop custom priority queue classes by implementing comparison methods
- Choose the right priority queue implementation for your specific use case
- Apply priority queues to real-world scenarios like process scheduling, task management, and resource allocation
- Optimize your applications by leveraging priority queues for ordered data processing
- Debug common issues when working with priority queues in Python
- Follow best practices for priority queue implementation and usage
Key Concepts
PriorityQueueis a thread-safe implementation of a priority queue, ensuring safe access and modification in multi-threaded environments.- The
putmethod is used to add tasks to the priority queue, where the first argument is the priority and the second argument is the task itself. - The
getmethod retrieves the task with the highest priority from the queue. - The
task_donemethod is used to indicate that a task has been completed. - The
joinmethod blocks until all tasks in the queue have been processed and completed.
Prerequisites
Before you start, make sure you have the following prerequisites:- Python 3.7 or newer installed
- Familiarity with lists, functions, and classes.
- Optional: basic multithreading knowledge
What Is a Priority Queue?
A priority queue stores (priority, item) pairs so the element with the highest priority (or lowest, for min-heap) is removed first. Python ships two ready-made solutions: heapq and queue.PriorityQueue.Priority queues are incredibly useful in various real-world applications and can benefit different types of users:
What are some use cases and applications for priority queues?
- Operating Systems: Process scheduling where high-priority tasks need to be executed first
- Network Routers: Managing network traffic by prioritizing certain types of data packets
- Healthcare Systems: Organizing emergency room patients based on condition severity
- Task Management Software: Handling tasks based on urgency and importance
- Game Development: AI decision making and event scheduling
- Resource Management: Allocating limited resources to competing requests
Who Can Use Priority Queues?
-
Software Developers
- Backend developers implementing job queues
- Game developers managing game events
- System programmers working on schedulers
-
Data Scientists
- Implementing algorithms like Dijkstra’s shortest path
- Managing computational tasks in order of importance
-
System Architects
- Designing distributed systems
- Building load balancers and request handlers
-
Business Applications
- Customer service ticket systems
- Project management tools
- Inventory management systems
- Process items in a specific order based on importance
- Manage limited resources efficiently
- Handle real-time events that require immediate attention
- Implement algorithms that require ordered processing
How to Implement a Priority Queue Using heapq?
The heapq?heapq module provides a min-heap implementation that can be used to implement a priority queue.This code block demonstrates the usage of a priority queue implemented using the
heapq module in Python. A priority queue is a data structure that stores elements with associated priorities, allowing for efficient retrieval of the element with the highest or lowest priority.The code initializes an empty priority queue and pushes three tasks with different priorities into the queue. The tasks are represented as tuples, where the first element is the priority and the second element is the task description.
The
heapq.heappush function is used to add tasks to the queue, and the heapq.heappop function is used to remove and return the task with the smallest priority.import heapq
pq = []
# push
heapq.heappush(pq, (2, "code"))
heapq.heappush(pq, (1, "eat"))
heapq.heappush(pq, (3, "sleep"))
# pop – always smallest priority
priority, task = heapq.heappop(pq)
print(priority, task) # 1 eat
Output1 eat
2 code
3 sleep
heapq maintains the smallest tuple at index 0, ensuring efficient retrieval of the highest priority element. Each push and pop operation incurs a time complexity of O(log n), where n is the number of elements in the heap. The space complexity is O(n), as the heap stores all elements.Benefits of Using heapq
| Benefit | Description |
|---|---|
| Efficiency | heapq maintains the smallest tuple at index 0, ensuring efficient retrieval of the highest priority element. |
| Simplicity | heapq is a built-in module that requires no additional setup. |
| Performance | heapq is optimized for speed and memory usage. |
Limitations of Using heapq
| Limitation | Description |
|---|---|
| No Maximum Priority | heapq by default only supports min-heap, so you cannot use it to implement a max-heap. |
| No Priority Update | heapq does not support updating the priority of an existing element. |
What is a Min-Heap vs Max-Heap?
A min-heap and max-heap are tree-based data structures that satisfy specific ordering properties:Min-Heap
- The value of each node is less than or equal to the values of its children
- The root node contains the minimum value in the heap
- Used when you need to efficiently find/remove the smallest element
- Python’s
heapqimplements a min-heap
1
/ \
3 2
/ \ /
6 4 5
Max-Heap
- The value of each node is greater than or equal to the values of its children
- The root node contains the maximum value in the heap
- Used when you need to efficiently find/remove the largest element
6
/ \
4 5
/ \ /
1 3 2
How to Implement a Max-Heap using heapq?
So by default heapq?heapq only supports min-heap, but you can implement a max-heap by either:- Inverting priorities (using negative values)
- Implementing a custom class with the
__lt__comparison method
heapq with both approaches.1. How to Implement a Max-Heap using Inverting Priorities(using negative values)
A max-heap can be simulated usingheapq by negating the values before adding them to the heap and then negating them again when extracting the maximum value. This works because negating numbers reverses their natural order (e.g., if a > b, then -a < -b), allowing the min-heap to effectively store and retrieve values in a max-heap manner.import heapq
# Initialize an empty list to act as the heap
max_heap = []
# Push elements into the simulated max-heap by negating them
heapq.heappush(max_heap, -5)
heapq.heappush(max_heap, -1)
heapq.heappush(max_heap, -8)
# Pop the largest element (which was stored as the smallest negative value)
largest_element = -heapq.heappop(max_heap)
print(f"Largest element: {largest_element}")
OutputLargest element: 8
Space complexity:
O(n), where n is the number of elements in the heap. This is because we store all elements in the heap.Time complexity:
O(log n) for each insertion and extraction operation. This is because heapq.heappush and heapq.heappop operations take O(log n) time.Note: The time complexity for the entire process is
O(n log n) due to the n insertions and one extraction operation.Benefits of Max-Heap using Negative Priorities
- Simple and straightforward implementation
- Works well with numeric values
- No custom class implementation required
- Maintains O(log n) time complexity for operations
- Memory efficient as it only stores the negated values
Drawbacks of Max-Heap using Negative Priorities
- Only works with numeric values
- May cause integer overflow for very large numbers
- Less readable code due to double negation
- Cannot directly view the actual values in the heap without negating them
- Not suitable for complex objects or non-numeric priorities.
2. How to Implement a Max-Heap with a Custom Class using __lt__?
Implementing a max-heap using a custom class with the __lt__ comparison method allows for a more flexible and object-oriented approach. This method enables the definition of how objects should be compared and sorted within the heap.class MaxHeap:
def __init__(self):
# Initialize an empty list to act as the heap
self.heap = []
def push(self, value):
# Push elements into the simulated max-heap
heapq.heappush(self.heap, value)
def pop(self):
# Pop the largest element from the heap
return heapq.heappop(self.heap)
def __lt__(self, other):
# Compare two MaxHeap instances based on their heap contents
return self.heap < other.heap
# Example usage
# Create two MaxHeap instances
heap1 = MaxHeap()
heap2 = MaxHeap()
# Push elements into the heaps
heap1.push(5)
heap1.push(1)
heap1.push(8)
heap2.push(3)
heap2.push(2)
heap2.push(9)
# Compare the heaps
print(heap1 < heap2) # This will compare the heaps based on their contents
OutputTrue
True indicates that heap1 is less than heap2 because the comparison is based on the heap contents. In this case, the largest element in heap1 is 8, while the largest element in heap2 is 9. Since 8 is less than 9, heap1 is considered less than heap2.Time complexity:
O(log n) for each insertion and extraction operation, where n is the number of elements in the heap. This is because the heapq.heappush and heapq.heappop operations take O(log n) time.Space complexity:
O(n), where n is the number of elements in the heap. This is because we store all elements in the heap.Benefits of Max-Heap using Custom Class
- Allows for the use of non-numeric values or complex objects as priorities
- Enables direct comparison of objects without negation
- Provides a more readable and intuitive implementation
- Supports the use of custom comparison logic for objects
Drawbacks of Max-Heap using Custom Class
- Requires a custom class implementation
- May be less efficient for large datasets due to the overhead of object creation and comparison
- Can be more complex to implement and understand for beginners
- May not be suitable for scenarios where numeric values are sufficient and simplicity is preferred.
How to Implement a Priority Queue Using queue.PriorityQueue?
The queue.PriorityQueue?queue.PriorityQueue class is a thread-safe implementation of a priority queue. It is built on top of the heapq module and provides a more robust and efficient implementation of a priority queue. This allows for the efficient management of tasks with varying priorities in a multi-threaded environment.Here’s an example of how to use
queue.PriorityQueue to implement a priority queue:from queue import PriorityQueue
import threading, random, time
# Create a PriorityQueue instance
pq = PriorityQueue()
# Define a worker function that will process tasks from the priority queue
def worker():
while True:
# Get the task with the highest priority from the queue
pri, job = pq.get()
# Process the task
print(f"Processing {job} (pri={pri})")
# Indicate that the task is done
pq.task_done()
# Start a daemon thread that will run the worker function
threading.Thread(target=worker, daemon=True).start()
# Add tasks to the priority queue with random priorities
for job in ["build", "test", "deploy"]:
pq.put((random.randint(1, 10), job))
# Wait for all tasks to be processed
pq.join()
OutputProcessing build (pri=1)
Processing test (pri=2)
Processing deploy (pri=3)
PriorityQueue ensuring that the task with the lowest priority number is retrieved first, simulating a priority-based scheduling system.
How does heapq vs PriorityQueue compare in multithreading?
Multithreading is a programming concept where a single program can execute multiple threads or flows of execution concurrently, improving the overall processing efficiency and responsiveness of the system. In a multithreaded environment, multiple threads share the same memory space and resources, which can lead to synchronization issues if not handled properly.heapq vs PriorityQueue compare in multithreading?When it comes to implementing priority queues in Python, two popular options are
heapq and PriorityQueue. Here’s a detailed comparison of these two modules in the context of multithreading:| Feature | heapq |
PriorityQueue |
|---|---|---|
| Implementation | heapq is not thread-safe, meaning it does not provide built-in mechanisms to ensure safe access and modification in a multithreaded environment. |
PriorityQueue is thread-safe, ensuring that access and modification operations are safely executed in a multithreaded environment. |
| Data Structure | heapq uses a list as its underlying data structure. |
PriorityQueue uses a queue as its underlying data structure, which is more suitable for multithreaded applications. |
| Complexity | The time complexity of heapq operations is O(n), where n is the number of elements in the heap. |
The time complexity of PriorityQueue operations is O(log n), making it more efficient for large datasets. |
| Usage | heapq is suitable for single-threaded applications where priority queue operations are not concurrent. |
PriorityQueue is designed for multithreaded applications where concurrent access and modification of the priority queue are necessary. |
| Synchronization | Since heapq is not thread-safe, manual synchronization mechanisms are required to ensure thread safety. |
PriorityQueue provides built-in synchronization, eliminating the need for manual synchronization. |
| Blocking | heapq does not provide blocking operations, which means that threads may need to implement their own blocking mechanisms. |
PriorityQueue provides blocking operations, allowing threads to wait until a task is available or until all tasks have been completed. |
| Task Completion | With heapq, task completion needs to be manually managed by the application. |
PriorityQueue automatically manages task completion, simplifying the development process. |
| Priority | heapq does not directly support priority management; priorities need to be implemented manually. |
PriorityQueue supports priority management out of the box, allowing tasks to be prioritized based on their priority. |
| Performance | heapq operations are generally faster due to its simpler implementation. |
PriorityQueue operations are slower due to the added complexity of thread safety and synchronization. |
| Use Case | heapq is suitable for single-threaded applications where performance is critical and priority queue operations are not concurrent. |
PriorityQueue is ideal for multithreaded applications where thread safety, synchronization, and priority management are essential. |
FAQs
1. What is a priority queue in Python?
A priority queue in Python is a data structure that allows elements to be added and removed based on their priority. It is a type of queue where each element is associated with a priority, and elements are removed in order of their priority. In Python, priority queues can be implemented using theheapq module or the queue.PriorityQueue class.2. How do I implement a priority queue in Python?
There are two common ways to implement a priority queue in Python:Using
heapq module:import heapq
# Create a priority queue
pq = []
# Add elements to the priority queue
heapq.heappush(pq, (3, 'task3')) # Priority 3
heapq.heappush(pq, (1, 'task1')) # Priority 1
heapq.heappush(pq, (2, 'task2')) # Priority 2
# Remove elements from the priority queue
while pq:
priority, task = heapq.heappop(pq)
print(f"Priority: {priority}, Task: {task}")
queue.PriorityQueue class:from queue import PriorityQueue
# Create a priority queue
pq = PriorityQueue()
# Add elements to the priority queue
pq.put((3, 'task3')) # Priority 3
pq.put((1, 'task1')) # Priority 1
pq.put((2, 'task2')) # Priority 2
# Remove elements from the priority queue
while not pq.empty():
priority, task = pq.get()
print(f"Priority: {priority}, Task: {task}")
3. Is Python’s heapq a min-heap or max-heap?
Python’s heapq module implements a min-heap by default. This means that the smallest element (based on the priority) is always at the root of the heap. When elements are added or removed, the heap is rebalanced to maintain this property.You can implement a max-heap by either:
- Inverting priorities (using negative values)
- Implementing a custom class with the
__lt__comparison method.
4. When should I use a priority queue?
A priority queue is particularly useful in scenarios where tasks or elements need to be processed in a specific order based on their priority. Some common use cases include:- Task scheduling: Prioritize tasks based on their urgency or importance.
- Resource allocation: Allocate resources to tasks or processes based on their priority.
- Event handling: Handle events in the order of their priority, ensuring critical events are processed first.
- Job scheduling: Schedule jobs or tasks in a priority order to ensure efficient resource utilization.
5. When to use heapq?
- In single-threaded applications where performance is critical and priority queue operations are not concurrent.
- When manual synchronization and task completion management are feasible and acceptable.
6. When to use PriorityQueue?
- In multithreaded applications where thread safety, synchronization, and priority management are essential.
- When built-in synchronization, blocking operations, and automatic task completion management are necessary for efficient and safe concurrent access.
Conclusion
This tutorial has covered the implementation of a priority queue in Python using both heapq and queue.PriorityQueue. Additionally, it has explored the creation of a max-heap using these modules.The comparison of
heapq and PriorityQueue in the context of multithreading has also been discussed. In summary, heapq is preferred for single-threaded applications where performance is paramount, while PriorityQueue is ideal for multithreaded applications where thread safety and synchronization are crucial.Furthermore, this tutorial has addressed some common questions about priority queues, providing a comprehensive understanding of their usage and implementation in Python.
Next Steps
If you found this tutorial helpful, you may want to check out these other related tutorials:- JavaScript Binary Heaps: Learn about binary heaps in JavaScript.
- Python Multiprocessing Example: Understand how to use the
multiprocessingmodule in Python. - Python Tutorial: A comprehensive tutorial on Python for beginners.
"Haimantika Mitra" / 2025-07-12 3 months ago / 未收藏/ DigitalOcean Community Tutorials/
发送到 kindle
Introduction
If everything is getting smarter, why can’t travel? This is the exact mindset with which I started building Nomado. Traveling is more than just booking flight tickets and being in beautiful locations. You need to look for a visa, build an itinerary, research the culture, find places to stay, and so much more. Nomado solves all of these, and each of these features is supported by DigitalOcean’s GradientAI Platform.In this article, we will see how we can build AI-enabled applications that automate the boring parts. Before getting into the “How’s”, let’s learn more about the GradientAI Platform and its features.
Key Takeaways
After reading this tutorial, you will be able to:- Understand what the GradientAI Platform is and how it can be used to build AI-powered applications, including its key features like serverless inference, agent routing, and knowledge bases
- Understand how to use the GradientAI Platform to build a travel app that generates personalized itineraries, provides flight information, and offers accommodation recommendations using AI
- Understand how to use the GradientAI Platform to build an intelligent chatbot that can handle both accommodation queries and general travel questions through specialized agent routing
What is the GradientAI platform?
The GradientAI Platform is a complete toolkit to build and run GPU-powered AI agents without the hassle. Whether you’re using pre-built models or training your own, you can connect them with function calls, agent routes, and even Retrieval Augmented Generation (RAG) pipelines that pull in the right information when you need it. With built-in features like agent routing, knowledge bases, guardrails, serverless inference, the GradientAI Platform makes it easier to launch powerful AI agents that actually get things done. Using the GradientAI platform, you can build chatbots very easily, or you can even use the APIs to build AI-powered applications.How GradientAI is being used in Nomado
In Nomado, we have three core features where we are using the GradientAI platform:- Generating travel itineraries: Once you are done with visa research, Nomado helps you build a personalized travel itinerary based on your travel destination, number of days, and month of travel.

- Getting flight information: Nomado follows a journey in itself. After your visa is sorted and you have an itinerary, the next thing you want to do is book flights. This is where we are using the GradientAI platform to fetch flight details for us.

- Chat interface: Visa sorted, flights booked, itinerary ready. Now comes the final part, finding the right place to stay and understanding the culture, local tips, and what to expect when you arrive. This is where our chat interface steps in. It’s built to answer all your accommodation and travel questions.

Understanding how we are using Serverless inferencing to generate the itineraries
To generate the itineraries, we are using Serverless inferencing through the GradientAI platform, and this is how the infrastructure is setup:const SECURE_AGENT_KEY = process.env.SECURE_AGENT_KEY
const AGENT_BASE_URL = "https://inference.do-ai.run/v1" //the inference endpoint
const client = hasRequiredEnvVars
? new OpenAI({
apiKey: SECURE_AGENT_KEY,
baseURL: AGENT_BASE_URL,
})
: null
When you plan a trip with Nomado, here’s what’s happening under the hood:

Step 1: Your input (Browser)
You enter:- Destination: e.g Paris
- Duration: e.g 3 days
- Month: e.g June
Step 2: Next.js server action for itinerary generation
The server action receives the user input and creates a detailed prompt:const prompt = `Your task is to generate a comprehensive travel plan for a ${duration}-day trip to ${destination} in ${visitMonth}. Make sure to bold the headings.
Please provide:
1. A ${duration}-day itinerary with day-by-day activities
2. A detailed packing list tailored to this destination in ${visitMonth} (considering the local weather and conditions)
3. Local customs and cultural tips
4. Must-try local foods
5. Transportation recommendations
Format your response in markdown with clear sections.`
Step 3: DigitalOcean GradientAI processing
The request hits the serverless inference service:- Loads the llama-3.1-8b-instruct model
- Runs the model with the prompt above
- Generates your complete travel plan
- Sends the result back
Using function routing in GradientAI to get real-time flight information
Next up is getting flight information, for that we are using the function routing feature in GradientAI platform. The function is built to fetch real-time flight data from the Tripadvisor API and allow the agent to call this function whenever a user asks about flight-related information. This creates a context-aware system that provides real-time, actionable flight data.Function routing is a feature in DigitalOcean’s GradientAI platform that allows AI agents to call external functions when they need real-time data or specific computations. Instead of the AI making up flight information, it can invoke a deployed function that fetches actual flight data from APIs.
Here’s how it works:
1. Function Invocation: The AI agent receives a user query and automatically calls a deployed function (our flight-func/flight) 2. Real Data Fetching: The function calls the Tripadvisor API with user parameters 3. Data Processing: Real flight data is returned and formatted by the AI agent 4. User Response: The agent provides accurate, bookable flight information

Step 1: Browser input for flight search
User enters in browser:- From City: “New York”
- To City: “London”
- Departure Date: “2024-06-15”
- Trip Type: “round-trip” or “one-way”
- Return Date: “2024-06-22” (for round-trip)
Step 2: Next.js server action for flight search
The server action receives the user input and creates a detailed prompt:const prompt = `You are a travel agent and your task is to show users flights along with flight numbers based on the source and destination they input.
Please provide flight information in the following format:
Outbound Flights (${fromCity} to ${toCity} on ${departureDate}):
Airline FlightNumber: Departing [Airport] at [Time], arriving [Airport] at [Time] (Flight Duration: [Duration], non-stop/with layover)
${tripType === "round-trip" ? `Return Flights (${toCity} to ${fromCity} on ${returnDate}):
Airline FlightNumber: Departing [Airport] at [Time], arriving [Airport] at [Time] (Flight Duration: [Duration], non-stop/with layover)` : ""}
For each flight, include:
- The type of flight (Boeing 737, Airbus A320, etc.)
- Airline name and flight number
- Airport codes
- Exact departure and arrival times
- Flight duration
- Layover information if applicable
- Direct booking links from Skyscanner, Kayak, or Expedia
Format your response in markdown with clear sections. Do NOT include any extra notes, disclaimers, or introductory text. Only output the flight details as described.`
Step 3: DigitalOcean GradientAI agent function routing
The DigitalOcean GenAI agent:1. Receives the prompt and user parameters
2. Detects that real flight data is needed (airlines, flight numbers, times, etc.)
3. Invokes the function route:
- Calls the deployed function (`flight-func/flight`) in the flight-info folder
- The function executes code that calls the Tripadvisor API with the user’s flight search parameters
- Returns real-time flight data (airlines, flight numbers, times, etc.)
5. Returns the complete flight information to your server action
Step 4: Response back to browser for flight search
Response flow:1. Agent sends back flight information with real data from Tripadvisor API
2. Server receives and processes the response:
const response = await client.chat.completions.create({
model: "Llama 3.3 Instruct",
messages: [
{
role: "system",
content: "You are an expert travel agent who specializes in finding specific flight information and providing direct booking links. Your responses should be practical and focused on helping travelers find and book their flights easily. Use real-time flight data and provide accurate information.",
},
{ role: "user", content: prompt },
],
temperature: 0.7,
max_tokens: 2000,
})
const content = response.choices[0]?.message?.content || "No response from AI"
return content
The entire code that is used to get the flight information can be found here.
Building a Chat Interface using the GradientAI Platform
Nomado also has a chatbot that you can use to chat about accommodation options and also tips and tricks of your place of visit. In the backend, we are using agent routing between two agents to get the information and web-crawling Nomad stays as a knowledge base for the accommodation agent.Agent routing is the ability to reference other agents from the instruction of an agent. Different agents may be trained or optimized for specific tasks or have different domain expertise to handle different types of requests. It usually consists of two types of agent:
- Parent agents (Accommodation agent in this case) handle general conversation and route specific requests to specialized child agents
- Child agents (Local info agent)are optimized for specific domains or tasks

Step-by-Step Process
Step 1: Browser input for chat
User enters in browser:- Accommodation Query: “Find me accommodation in Paris” OR
- General Travel Query: “What should I pack for Japan?”
Step 2: Parent accommodation agent & agent routing
The parent accommodation agent:- Receives the user query through the chatbot interface
- Analyzes the intent and content of the query
- Determines the appropriate routing based on query type:
- Accommodation queries → Processes directly using the Nomad stays knowledge base
- Travel/local info queries → Routes to the Local-info child agent with OpenAI 4o models
- For accommodation queries: Generates response using scraped data from Nomad stays
- For other queries: Delegates to specialized child agent
Step 3: Response processing
Response flow varies based on query type:For accommodation queries:
- Parent agent processes the query directly
- Searches through the Nomad stays knowledge base
- Generates accommodation recommendations
- Parent agent routes to
Local-infochild agent - Child agent processes using OpenAI 4o models
- Generates travel tips, cultural information, or local advice
- Sends response back to parent agent
Step 4: Response back to browser for chat
- User receives specific, data-driven recommendations
- Response maintains conversational context through the parent agent
Ending Notes
Nomado is an example of how you can connect real-world tasks with AI features using the GradientAI platform, without managing heavy infrastructure.
If you’re planning to build something similar, here are a few things that might help:- Use serverless inference for tasks like generating text or summaries.
- Use function routing to plug in real-time APIs so your AI stays accurate with the latest data and is contextually aware.
- Use agent routing and knowledge bases to keep your answers consistent, especially if you have domain-specific content or multiple use cases.
- Get started with the GradientAI Platform - A comprehensive guide to help you start building AI applications on GradientAI Platform
- Deploy Serverless Functions - Learn how to deploy and manage scalable serverless functions without infrastructure overhead
- Build AI Agents with knowledge base web crawling - Tutorial on creating AI agents that can crawl websites and build knowledge bases for intelligent responses
- What’s new on GradientAI Platform - Latest features and improvements added to the GradientAI Platform
- Introducing DigitalOcean GradientAI - Announcement and overview of DigitalOcean’s new AI development platform
- GradientAI Platform Generally Available - Details about GradientAI Platform’s general availability release and enterprise-ready features
"techug" / 2025-07-12 3 months ago / 未收藏/ 程序师/
发送到 kindle
这篇报告研究了2025年初AI工具对经验丰富的开源开发者的生产力影响,通过随机对照试验(RCT)得出了一些出人意料的结论。
"techug" / 2025-07-11 3 months ago / 未收藏/ 程序师/
发送到 kindle
这是您全面了解 CSS 层叠层的指南,CSS 层叠层是一项 CSS 功能,允许我们明确定义具有特定优先级的层,从而在项目中完全控制哪些样式具有优先级,而无需依赖特定性技巧或 !important。
"techug" / 2025-07-11 3 months ago / 未收藏/ 程序师/
发送到 kindle
到目前为止,对所用 color-scheme 值做出响应是系统颜色专有的功能。得益于 CSS 颜色模块级别 5 中指定的 light-dark(),您现在也可以使用相同的功能。
"Elastic Security Team" / 2025-07-11 3 months ago / 未收藏/ Elasticsearch/
发送到 kindle
In the face of increasingly sophisticated cyber threats, the chief information security officer, or CISO, is responsible for ensuring the organization's data is secure.
CISOs ensure that proper security strategies, policies, and technologies are working to meet their goals of mitigating risk, maintaining regulatory compliance, and upholding customer trust. A CISO helps align security initiatives with business goals, enabling growth while minimizing disruptions and vulnerabilities.
But what is it like being a CISO? Stepping into this leadership role means effectively communicating and handling the security challenges and vulnerabilities of the entire organization. This is no easy task. This article will help you understand the role of a CISO and what it takes to become one.
The core responsibilities of a chief information security officerThe chief information security officer leads the company-wide information security strategy, ensures the secure design and operation of systems and infrastructure, and equips their team to effectively manage cybersecurity risks.
CISOs need to balance a security-first mindset and smooth business operations. They must develop and enforce security policies while complying with relevant regulations and standards. Increasingly, CISOs must also consider customers’ security demands and concerns.
The CISO oversees the hiring, performance, and structure of security teams; directs the allocation of resources and budget to support security initiatives; and collaborates across departments like IT to embed security into the organization’s culture and decision-making processes.
The CISO is responsible for running an organization's security operations center (SOC) smoothly and effectively, which unifies and coordinates all cybersecurity processes, technologies, and operations. This role includes managing money as well as people — budgeting for technology or MSSP vendors, partners, CSPs, and more.
https://static-www.elastic.co/v3/assets/bltefdd0b53724fa2ce/blt91c85e4326a8ce5c/68714e55e8921d56aefa62c9/CISO-R&R.png,CISO-R&R.pngCISO’s role in cybersecurity strategy and risk managementA CISO develops and implements cybersecurity strategies by understanding the organization’s assets, systems, and security threats. They create a risk management framework to identify an organization’s vulnerabilities and evaluate the potential impact of various threats. By working with others on the leadership team, CISOs prioritize risk mitigation efforts based on their most critical needs.
In addition to proactive risk management, CISOs create a plan for incident response and crisis management in the event of a cyber attack or security breach. The response plans will include ways to coordinate internal teams and external partners, as well as communication strategies to minimize damage and ensure rapid recovery.
Business continuity planning also falls within a CISO’s scope. If a cyber attack occurs, CISOs work to ensure critical operations can continue or resume quickly. Through regular testing, training, and refinement of response plans, the CISO helps build organizational resilience and ensures readiness for evolving threats, such as AI-powered cyber attacks.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
In this blog post, we may have used or referred to third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use.
Elastic, Elasticsearch, and associated marks are trademarks, logos, or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos, or registered trademarks of their respective owners.
CISOs ensure that proper security strategies, policies, and technologies are working to meet their goals of mitigating risk, maintaining regulatory compliance, and upholding customer trust. A CISO helps align security initiatives with business goals, enabling growth while minimizing disruptions and vulnerabilities.
But what is it like being a CISO? Stepping into this leadership role means effectively communicating and handling the security challenges and vulnerabilities of the entire organization. This is no easy task. This article will help you understand the role of a CISO and what it takes to become one.
The core responsibilities of a chief information security officerThe chief information security officer leads the company-wide information security strategy, ensures the secure design and operation of systems and infrastructure, and equips their team to effectively manage cybersecurity risks.
CISOs need to balance a security-first mindset and smooth business operations. They must develop and enforce security policies while complying with relevant regulations and standards. Increasingly, CISOs must also consider customers’ security demands and concerns.
The CISO oversees the hiring, performance, and structure of security teams; directs the allocation of resources and budget to support security initiatives; and collaborates across departments like IT to embed security into the organization’s culture and decision-making processes.
The CISO is responsible for running an organization's security operations center (SOC) smoothly and effectively, which unifies and coordinates all cybersecurity processes, technologies, and operations. This role includes managing money as well as people — budgeting for technology or MSSP vendors, partners, CSPs, and more.
https://static-www.elastic.co/v3/assets/bltefdd0b53724fa2ce/blt91c85e4326a8ce5c/68714e55e8921d56aefa62c9/CISO-R&R.png,CISO-R&R.pngCISO’s role in cybersecurity strategy and risk managementA CISO develops and implements cybersecurity strategies by understanding the organization’s assets, systems, and security threats. They create a risk management framework to identify an organization’s vulnerabilities and evaluate the potential impact of various threats. By working with others on the leadership team, CISOs prioritize risk mitigation efforts based on their most critical needs.
In addition to proactive risk management, CISOs create a plan for incident response and crisis management in the event of a cyber attack or security breach. The response plans will include ways to coordinate internal teams and external partners, as well as communication strategies to minimize damage and ensure rapid recovery.
Business continuity planning also falls within a CISO’s scope. If a cyber attack occurs, CISOs work to ensure critical operations can continue or resume quickly. Through regular testing, training, and refinement of response plans, the CISO helps build organizational resilience and ensures readiness for evolving threats, such as AI-powered cyber attacks.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
In this blog post, we may have used or referred to third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use.
Elastic, Elasticsearch, and associated marks are trademarks, logos, or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos, or registered trademarks of their respective owners.
"Popoola Temitope" / 2025-07-11 3 months ago / 未收藏/ LogRocket - Medium/
发送到 kindle
Not sure if low-code is right for your next project? This guide breaks down when to use it, when to avoid it, and how to make the right call.
The post When is low-code the right choice? Here’s how to decide appeared first on LogRocket Blog.
The post When is low-code the right choice? Here’s how to decide appeared first on LogRocket Blog.
"Emmanuel John" / 2025-07-11 3 months ago / 未收藏/ LogRocket - Medium/
发送到 kindle
Compare Firebase Studio, Lovable, and Replit for AI-powered app building. Find the best tool for your project needs.
The post Comparing AI app builders — Firebase Studio vs. Lovable vs. Replit appeared first on LogRocket Blog.
The post Comparing AI app builders — Firebase Studio vs. Lovable vs. Replit appeared first on LogRocket Blog.
2025-05-20 5 months ago / 未收藏/ MongoDB | Blog/
发送到 kindle
TL;DR – We’re excited to introduce voyage-3.5 and voyage-3.5-lite, the latest generation of our embedding models. These models offer improved retrieval quality over voyage-3 and voyage-3-lite at the same price, setting a new frontier for price-performance. Both models support embeddings in 2048, 1024, 512, and 256 dimensions, with multiple quantization options enabled by Matryoshka learning and quantization-aware training. voyage-3.5 and voyage-3.5-lite outperform OpenAI-v3-large by 8.26% and 6.34%, respectively, on average across evaluated domains, with 2.2x and 6.5x lower respective costs and a 1.5x smaller embedding dimension. Compared with OpenAI-v3-large (float, 3072), voyage-3.5 (int8, 2048) and voyage-3.5-lite (int8, 2048) reduce vector database costs by 83%, while achieving higher retrieval quality.
Note to readers: voyage-3.5 and voyage-3.5-lite are currently available through the Voyage AI APIs directly or through the private preview of automated text embedding in Atlas Vector Search. For access, sign up for Voyage AI or register your interest in the Atlas Vector Search private preview.We’re excited to introduce voyage-3.5 and voyage-3.5-lite, which maintain the same sizes as their predecessors—voyage-3 and voyage-3-lite—but offer improved quality for a new retrieval frontier.
As we see in the figure below, voyage-3.5 improves retrieval quality over voyage-3 by 2.66%, and voyage-3.5-lite improves over voyage-3-lite by 4.28%—both maintaining a 32K context length and their respective price points of $0.06 and $0.02 per 1M tokens.
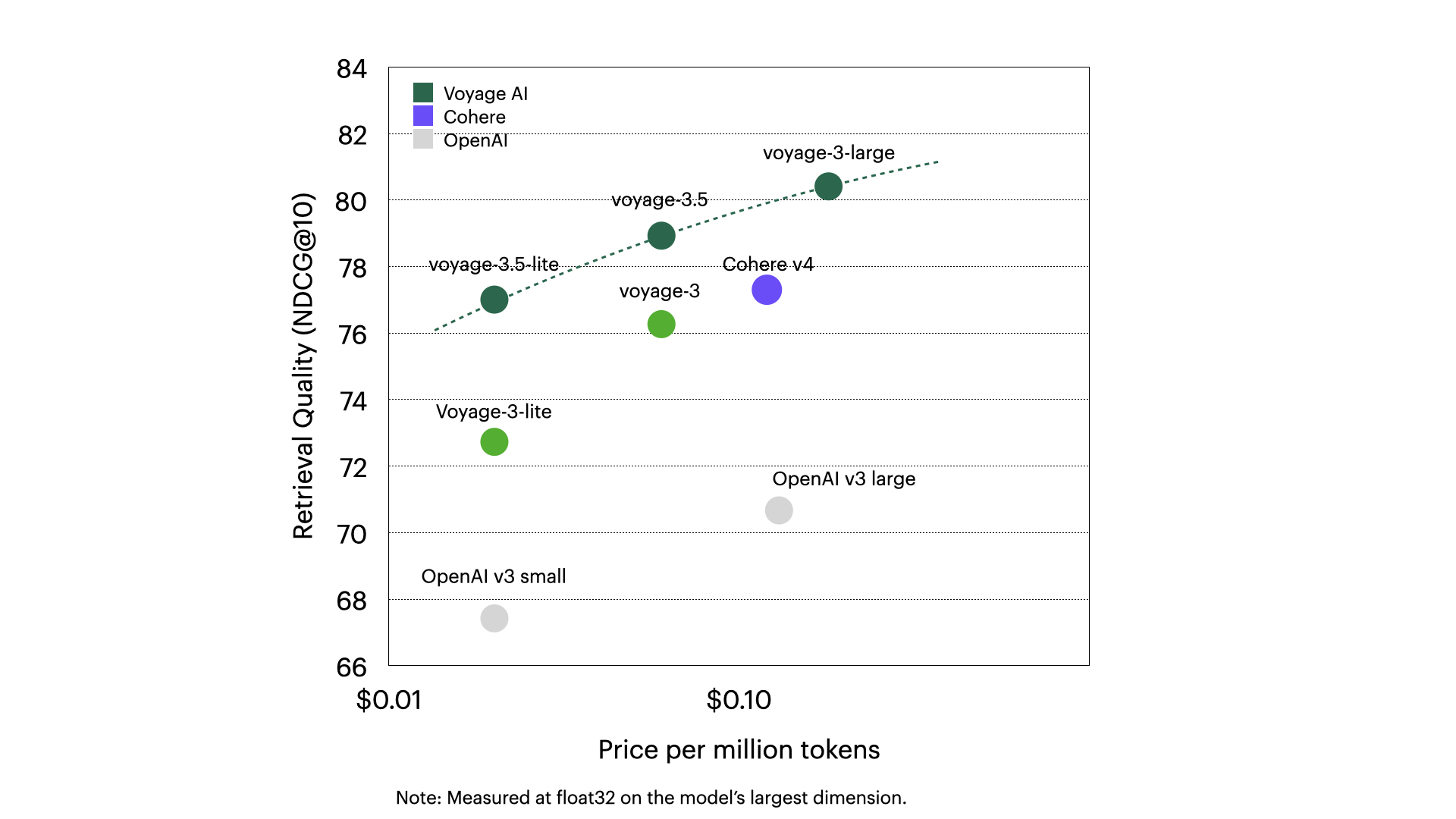
Matryoshka embeddings and quantization: voyage-3.5 and voyage-3.5-lite support 2048, 1024, 512, and 256-dimensional embeddings enabled by Matryoshka learning and multiple embedding quantization options—including 32-bit floating point, signed and unsigned 8-bit integer, and binary precision—while minimizing quality loss. Compared with OpenAI-v3-large (float, 3072), voyage-3.5 and voyage-3.5-lite (both int8, 2048) reduce vector database costs by 83%, while achieving outperformance of 8.25% and 6.35% respectively. Further, comparing OpenAI-v3-large (float, 3072) with voyage-3.5 and voyage-3.5-lite (both binary, 1024), vector database costs are reduced by 99%, with outperformance of 3.63% and 1.29% respectively.
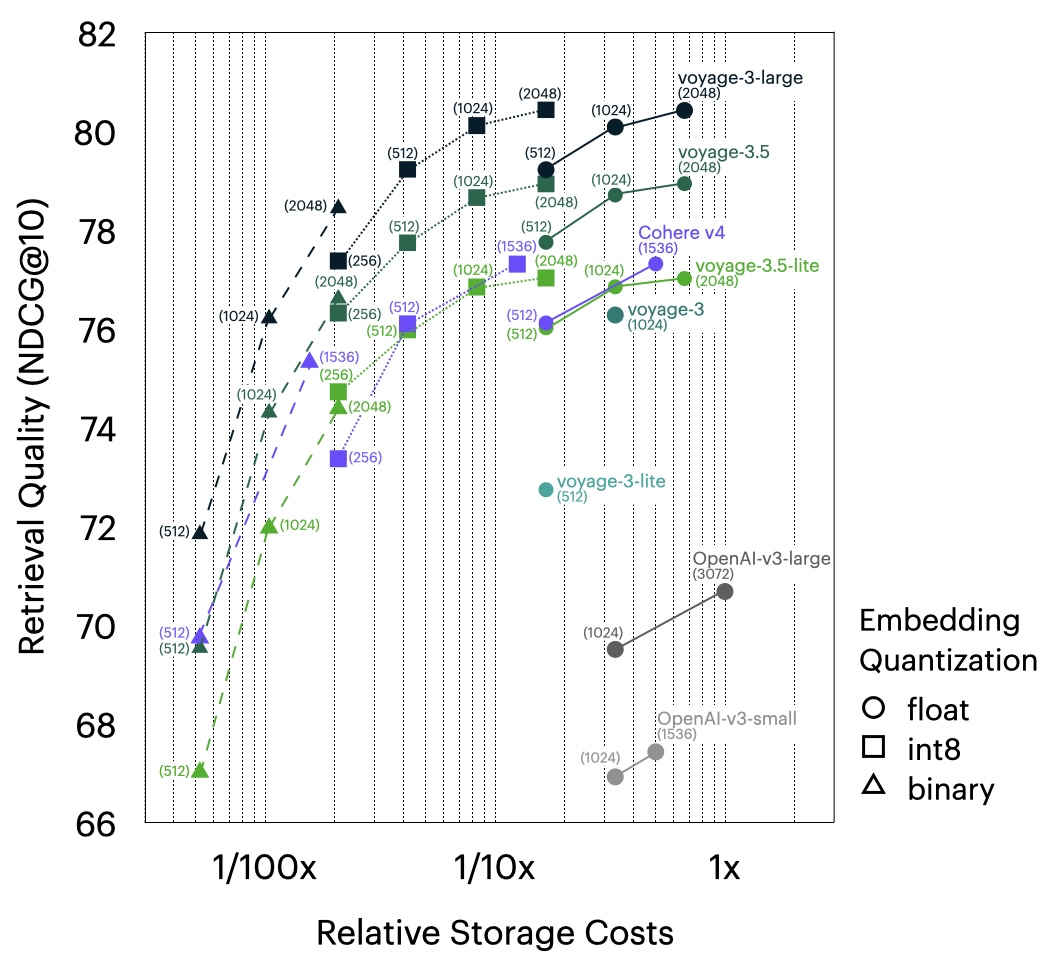
Evaluation details
Datasets: We evaluate on 100 datasets spanning eight domains: technical documentation, code, law, finance, web reviews, multilingual, long documents, and conversations. Each dataset consists of a corpus (e.g., technical documentation, court opinions) and queries (e.g., questions, summaries). The following table lists the datasets in the eight categories, except multilingual, which includes 62 datasets covering 26 languages. A list of all evaluation datasets is available in this spreadsheet.| Category | Descriptions | Datasets |
|---|---|---|
| Technical documentation | Cohere, 5G, OneSignal, LangChain, PyTorch | |
| Code snippets, docstrings | LeetCodeCPP-rtl, LeetCodeJava-rtl, LeetCodePython-rtl, HumanEval-rtl, MBPP-rtl, DS1000-referenceonly-rtl, DS1000-rtl, APPS-rtl | |
| Cases, court opinions, statues, patents | LeCaRDv2, LegalQuAD, LegalSummarization, AILA casedocs, AILA statutes | |
| SEC fillings, finance QA | RAG benchmark (Apple-10K-2022), FinanceBench, TAT-QA-rtl, Finance Alpaca, FiQA-Personal-Finance-rtl, Stock News Sentiment, ConvFinQA-rtl, FinQA-rtl, HC3 Finance | |
| Reviews, forum posts, policy pages | Huffpostsports, Huffpostscience, Doordash, Health4CA | |
| Long documents on assorted topics: government reports, academic papers, and dialogues | NarrativeQA, QMSum, SummScreenFD, WikimQA | |
| Meeting transcripts, dialogues | Dialog Sum, QA Conv, HQA |
Metrics: Given a query, we retrieve the top 10 documents based on cosine similarities and report the normalized discounted cumulative gain (NDCG@10), a standard metric for retrieval quality and a variant of the recall.
Results
All the evaluation results are available in this spreadsheet.Domain-specific quality: The bar charts below illustrate the average retrieval quality of voyage-3.5 and voyage-3.5-lite with full precision and 2048 dimensions, both overall and for each domain. voyage-3.5 outperforms OpenAI-v3-large, voyage-3, and Cohere-v4 by an average of 8.26%, 2.66%, and 1.63%, respectively across domains. voyage-3.5-lite outperforms OpenAI-v3-large and voyage-3-lite by an average of 6.34% and 4.28%, respectively across domains.
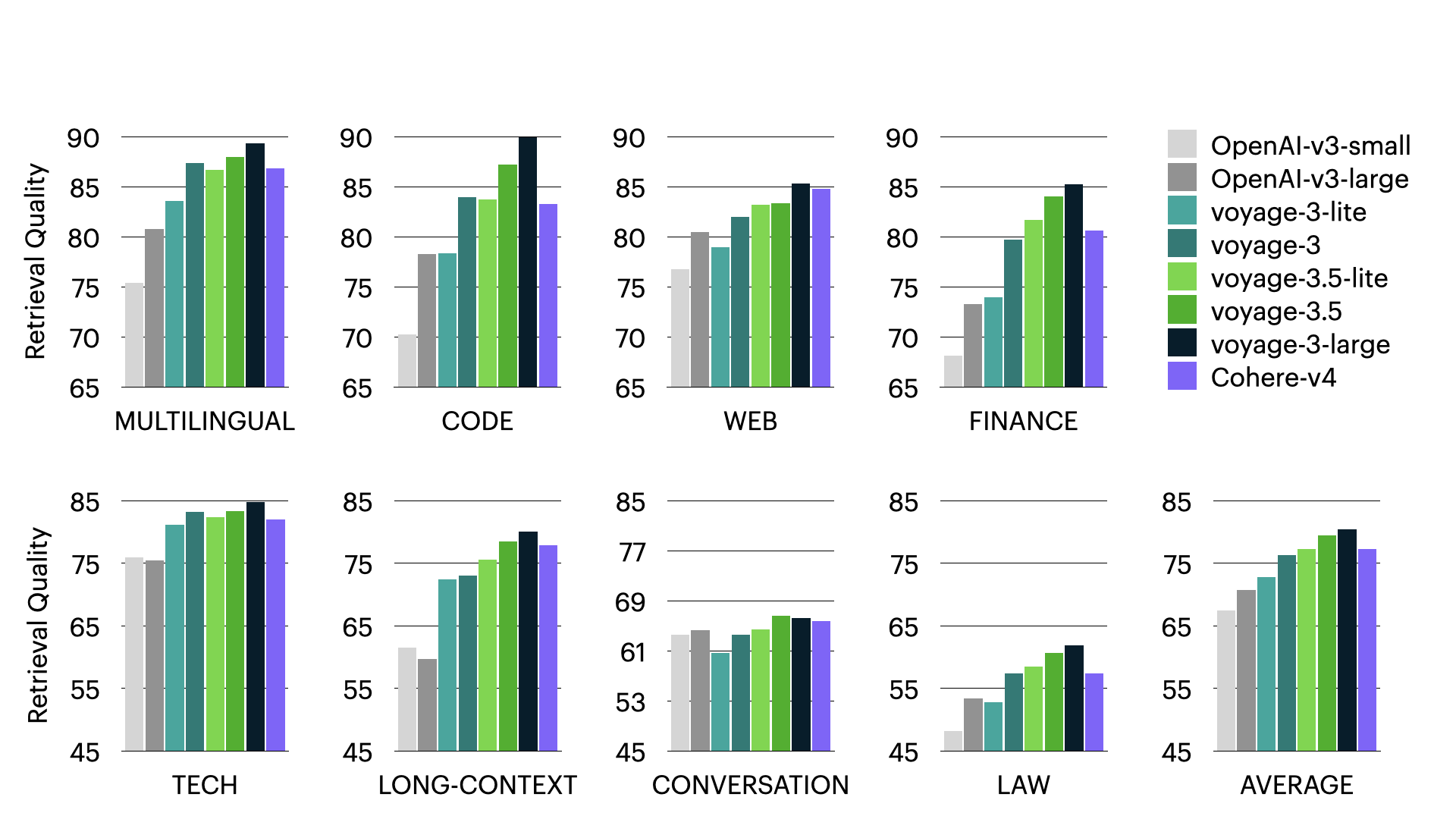
Try voyage-3.5 and voyage-3.5-lite!
Interested in getting started today via the Voyage API? The first 200 million tokens are free. Visit the docs to learn more.Interested in using voyage-3.5 or voyage-3.5-lite alongside MongoDB Atlas? Register your interest in the private preview for automated embedding in Atlas Vector Search.