{"_":"\n\t\t\t\tby \t\t\t\t\t","a":[{"_":"Michel Ferreira","$":{"itemprop":"url","class":"author","rel":"author","href":"https://alistapart.com/author/michelferreira/"}}]} / 2025-07-23 11 days ago / 未收藏/ A List Apart: The Full Feed/
发送到 kindle
Picture this: You’re in a meeting room at your tech company, and two people are having what looks like the same conversation about the same design problem. One is talking about whether the team has the right skills to tackle it. The other is diving deep into whether the solution actually solves the user’s problem. Same room, same problem, completely different lenses. This is the beautiful, sometimes messy reality of having both a Design Manager and a Lead Designer on the same team. And if you’re wondering how to make this work without creating confusion, overlap, or the dreaded “too many cooks” scenario, you’re asking the right question. The traditional answer has been to draw clean lines on an org chart. The Design Manager handles people, the Lead Designer handles craft. Problem solved, right? Except clean org charts are fantasy. In reality, both roles care deeply about team health, design quality, and shipping great work. The magic happens when you embrace the overlap instead of fighting it—when you start thinking of your design org as a design organism.
The Anatomy of a Healthy Design Team
Here's what I’ve learned from years of being on both sides of this equation: think of your design team as a living organism. The Design Manager tends to the mind (the psychological safety, the career growth, the team dynamics). The Lead Designer tends to the body (the craft skills, the design standards, the hands-on work that ships to users). But just like mind and body aren’t completely separate systems, so, too, do these roles overlap in important ways. You can’t have a healthy person without both working in harmony. The trick is knowing where those overlaps are and how to navigate them gracefully. When we look at how healthy teams actually function, three critical systems emerge. Each requires both roles to work together, but with one taking primary responsibility for keeping that system strong.
The Nervous System: People & Psychology
Primary caretaker: Design Manager Supporting role: Lead Designer The nervous system is all about signals, feedback, and psychological safety. When this system is healthy, information flows freely, people feel safe to take risks, and the team can adapt quickly to new challenges. The Design Manager is the primary caretaker here. They’re monitoring the team’s psychological pulse, ensuring feedback loops are healthy, and creating the conditions for people to grow. They’re hosting career conversations, managing workload, and making sure no one burns out. But the Lead Designer plays a crucial supporting role. They’re providing sensory input about craft development needs, spotting when someone’s design skills are stagnating, and helping identify growth opportunities that the Design Manager might miss. Design Manager tends to:
Career conversations and growth planning
Team psychological safety and dynamics
Workload management and resource allocation
Performance reviews and feedback systems
Creating learning opportunities
Lead Designer supports by:
Providing craft-specific feedback on team member development
Identifying design skill gaps and growth opportunities
Offering design mentorship and guidance
Signaling when team members are ready for more complex challenges
The Muscular System: Craft & Execution
Primary caretaker: Lead Designer Supporting role: Design Manager The muscular system is about strength, coordination, and skill development. When this system is healthy, the team can execute complex design work with precision, maintain consistent quality, and adapt their craft to new challenges. The Lead Designer is the primary caretaker here. They’re setting design standards, providing craft coaching, and ensuring that shipping work meets the quality bar. They’re the ones who can tell you if a design decision is sound or if we’re solving the right problem. But the Design Manager plays a crucial supporting role. They’re ensuring the team has the resources and support to do their best craft work, like proper nutrition and recovery time for an athlete. Lead Designer tends to:
Definition of design standards and system usage
Feedback on what design work meets the standard
Experience direction for the product
Design decisions and product-wide alignment
Innovation and craft advancement
Design Manager supports by:
Ensuring design standards are understood and adopted across the team
Confirming experience direction is being followed
Supporting practices and systems that scale without bottlenecking
Facilitating design alignment across teams
Providing resources and removing obstacles to great craft work
The Circulatory System: Strategy & Flow
Shared caretakers: Both Design Manager and Lead Designer The circulatory system is about how information, decisions, and energy flow through the team. When this system is healthy, strategic direction is clear, priorities are aligned, and the team can respond quickly to new opportunities or challenges. This is where true partnership happens. Both roles are responsible for keeping the circulation strong, but they’re bringing different perspectives to the table. Lead Designer contributes:
User needs are met by the product
Overall product quality and experience
Strategic design initiatives
Research-based user needs for each initiative
Design Manager contributes:
Communication to team and stakeholders
Stakeholder management and alignment
Cross-functional team accountability
Strategic business initiatives
Both collaborate on:
Co-creation of strategy with leadership
Team goals and prioritization approach
Organizational structure decisions
Success measures and frameworks
Keeping the Organism Healthy
The key to making this partnership sing is understanding that all three systems need to work together. A team with great craft skills but poor psychological safety will burn out. A team with great culture but weak craft execution will ship mediocre work. A team with both but poor strategic circulation will work hard on the wrong things.
Be Explicit About Which System You’re Tending
When you’re in a meeting about a design problem, it helps to acknowledge which system you’re primarily focused on. “I’m thinking about this from a team capacity perspective” (nervous system) or “I’m looking at this through the lens of user needs” (muscular system) gives everyone context for your input. This isn’t about staying in your lane. It’s about being transparent as to which lens you’re using, so the other person knows how to best add their perspective.
Create Healthy Feedback Loops
The most successful partnerships I’ve seen establish clear feedback loops between the systems: Nervous system signals to muscular system: “The team is struggling with confidence in their design skills” → Lead Designer provides more craft coaching and clearer standards. Muscular system signals to nervous system: “The team’s craft skills are advancing faster than their project complexity” → Design Manager finds more challenging growth opportunities. Both systems signal to circulatory system: “We’re seeing patterns in team health and craft development that suggest we need to adjust our strategic priorities.”
Handle Handoffs Gracefully
The most critical moments in this partnership are when something moves from one system to another. This might be when a design standard (muscular system) needs to be rolled out across the team (nervous system), or when a strategic initiative (circulatory system) needs specific craft execution (muscular system). Make these transitions explicit. “I’ve defined the new component standards. Can you help me think through how to get the team up to speed?” or “We’ve agreed on this strategic direction. I'm going to focus on the specific user experience approach from here.”
Stay Curious, Not Territorial
The Design Manager who never thinks about craft, or the Lead Designer who never considers team dynamics, is like a doctor who only looks at one body system. Great design leadership requires both people to care about the whole organism, even when they’re not the primary caretaker. This means asking questions rather than making assumptions. “What do you think about the team’s craft development in this area?” or “How do you see this impacting team morale and workload?” keeps both perspectives active in every decision.
When the Organism Gets Sick
Even with clear roles, this partnership can go sideways. Here are the most common failure modes I’ve seen:
System Isolation
The Design Manager focuses only on the nervous system and ignores craft development. The Lead Designer focuses only on the muscular system and ignores team dynamics. Both people retreat to their comfort zones and stop collaborating. The symptoms: Team members get mixed messages, work quality suffers, morale drops. The treatment: Reconnect around shared outcomes. What are you both trying to achieve? Usually it’s great design work that ships on time from a healthy team. Figure out how both systems serve that goal.
Poor Circulation
Strategic direction is unclear, priorities keep shifting, and neither role is taking responsibility for keeping information flowing. The symptoms: Team members are confused about priorities, work gets duplicated or dropped, deadlines are missed. The treatment: Explicitly assign responsibility for circulation. Who’s communicating what to whom? How often? What’s the feedback loop?
Autoimmune Response
One person feels threatened by the other’s expertise. The Design Manager thinks the Lead Designer is undermining their authority. The Lead Designer thinks the Design Manager doesn’t understand craft. The symptoms: Defensive behavior, territorial disputes, team members caught in the middle. The treatment: Remember that you’re both caretakers of the same organism. When one system fails, the whole team suffers. When both systems are healthy, the team thrives.
The Payoff
Yes, this model requires more communication. Yes, it requires both people to be secure enough to share responsibility for team health. But the payoff is worth it: better decisions, stronger teams, and design work that’s both excellent and sustainable. When both roles are healthy and working well together, you get the best of both worlds: deep craft expertise and strong people leadership. When one person is out sick, on vacation, or overwhelmed, the other can help maintain the team’s health. When a decision requires both the people perspective and the craft perspective, you’ve got both right there in the room. Most importantly, the framework scales. As your team grows, you can apply the same system thinking to new challenges. Need to launch a design system? Lead Designer tends to the muscular system (standards and implementation), Design Manager tends to the nervous system (team adoption and change management), and both tend to circulation (communication and stakeholder alignment).
The Bottom Line
The relationship between a Design Manager and Lead Designer isn’t about dividing territories. It’s about multiplying impact. When both roles understand they’re tending to different aspects of the same healthy organism, magic happens. The mind and body work together. The team gets both the strategic thinking and the craft excellence they need. And most importantly, the work that ships to users benefits from both perspectives. So the next time you’re in that meeting room, wondering why two people are talking about the same problem from different angles, remember: you’re watching shared leadership in action. And if it’s working well, both the mind and body of your design team are getting stronger.
2025-07-23 11 days ago / 未收藏/ MongoDB | Blog/
发送到 kindle
Retrieval-augmented generation (RAG) is becoming increasingly vital for developing sophisticated AI applications that not only generate fluent text but also ensure precision and contextual relevance by grounding responses in real, factual data. This approach significantly mitigates hallucinations and enhances the reliability of AI outputs. This guide provides a detailed exploration of an open-source solution designed to facilitate the deployment of a production-ready RAG application by using the powerful combination of MongoDB Atlas and Cohere Command R+. This solution is built upon and extends the foundational principles demonstrated in the official Cohere plus MongoDB RAG documentation available at Build Chatbots with MongoDB and Cohere. To provide you with in-depth knowledge and practical skills in several key areas, this comprehensive walkthrough will:
Show you how to build a complete RAG pipeline using MongoDB Atlas and Cohere APIs
Focus on data flow, retrieval, and generation
Enable you to enhance answer quality through reranking to improve relevance and accuracy
Enable detailed, flexible deployment with Docker Compose for local or cloud environments
Explain MongoDB’s dual role as a vector store and chat memory for a seamless RAG application
Reasons to choose MongoDB and Cohere for RAG
The convergence of powerful technologies—MongoDB Atlas and Cohere Command R+—unlocks significant potential for creating sophisticated, scalable, and high-performance systems for grounded generative AI (gen AI). This synergistic approach provides a comprehensive toolkit to handle the unique demands of modern AI applications.
MongoDB Atlas and Cohere Command R+ facilitate the development of scalable, high-performing, and grounded AI applications.
MongoDB Atlas provides a scalable, flexible, reliable, and fast database for managing large datasets used to ground generative models.
Cohere Command R+ offers a sophisticated large language model (LLM) for natural language understanding and generation, incorporating retrieved data for factual accuracy and rapid inference.
The combined use of MongoDB Atlas and Cohere Command R+ results in applications with fast and accurate responses, scalable architectures, and outputs informed by real-world data.
This powerful combination represents a compelling approach to building the next generation of gen AI applications, facilitating innovation and unlocking novel opportunities across various sectors.
Architecture overview
In this section, we’ll look at the implementation architecture of the application and how the mixture of Cohere and MongoDB components flow underneath.
Figure 1. Reference architecture, with Cohere and MongoDB components.
The following list divides and explains the architecture components: 1. Document ingestion, chunking, and embedding with Cohere
The initial step involves loading your source documents, which can be in various formats.
These documents are then intelligently segmented into smaller, semantically meaningful chunks to optimize retrieval and processing.
Cohere’s powerful embedding models generate dense vector representations of these text chunks, capturing their underlying meaning and semantic relationships.
2. Scalable vector and text storage in MongoDB Atlas
MongoDB Atlas, a fully managed and scalable database service, serves as the central repository for both the original text chunks and their corresponding vector embeddings.
MongoDB Atlas’s built-in vector search capabilities (with MongoDB Atlas Vector Search) enable efficient and high-performance similarity searches based on the generated embeddings.
This enables the scalable storage and retrieval of vast amounts of textual data and their corresponding vector representations.
3/ Query processing and semantic search with MongoDB Atlas
When a user poses a query, it undergoes a similar embedding process, using Cohere to generate a vector representation of the search intent.
MongoDB Atlas then uses this query vector to perform a semantic search within its vector index.
MongoDB Atlas efficiently identifies the most relevant document chunks based on their vector similarity to the query vector, surpassing simple keyword matching to comprehend the underlying meaning.
4. Reranking with Cohere
To further refine the relevance of the retrieved document chunks, you can employ Cohere’s reranking models.
The reranker analyzes the initially retrieved chunks in the context of the original query, scoring and ordering them based on a more nuanced understanding of their relevance.
This step ensures that you’re prioritizing the most pertinent information for the final answer generation.
5. Grounded answer generation with Cohere Command R+
The architecture then passes the top-ranked document chunks to Cohere’s Command R+ LLM.
Command R+ uses its extensive knowledge and understanding of language to generate a grounded and coherent answer to the user’s query, with direct support from the information extracted from the retrieved documents.
This ensures that the answers are accurate, contextually relevant, and traceable to the source material.
6. Context-aware interactions and memory with MongoDB
To enable more natural and conversational interactions, you can store the history of the conversation in MongoDB.
This enables the RAG application to maintain context across multiple turns, referencing previous queries and responses to provide more informed and relevant answers.
By incorporating conversation history, the application gains memory and can engage in more meaningful dialogues with users.
For a better understanding of what each technical component does, reference the following table, which shows how the architecture assigns roles to each component:
Component
Role
MongoDB Atlas
Stores text chunks, vector embeddings, and chat logs
Cohere Embed API
Converts text into dense vector representations
MongoDB Atlas Vector Search
Performs efficient semantic retrieval via cosine similarity
Cohere Rerank API
Prioritizes the most relevant results from the retrieval
Cohere Command R+
Generates final responses grounded in top documents
In summary, this architecture provides a robust and scalable framework for building RAG applications. It integrates the document processing and embedding capabilities of Cohere with the scalable storage and vector search functionalities of MongoDB Atlas. By combining this with the generative power of Command R+, developers can create intelligent applications that provide accurate, contextually relevant, and grounded answers to user queries, while also maintaining conversational context for an enhanced user experience.
Application Setup
The application requires the following components, ideally readied beforehand.
A MongoDB Atlas cluster (free tier is fine)
A Cohere account and API key
Python 3.8+
Docker and Docker Compose
A configured AWS CLI
Deployment steps
1. Clone the repository.
git clone https://github.com/mongodb-partners/maap-cohere-qs.git
cd maap-cohere-qs
2. Configure the <a href="https://github.com/mongodb-partners/maap-cohere-qs/blob/main/deployment/one-click.ksh" target="_blank">one-click.ksh</a> script: Open the script in a text editor and fill in the required values for various environment variables:
AWS Auth: Specify the AWS_REGION, AWS_ACCESS_KEY_ID, and AWS_SECRET_ACCESS_KEY for deployment.
EC2 Instance Types: Choose suitable instance types for your workload.
Network Configuration: Update key names, subnet IDs, security group IDs, etc.
Authentication Keys: Fetch Project ID and API public and private keys for MongoDB Atlas cluster setup. Update the script file with the keys for APIPUBLICKEY, APIPRIVATEKEY, and GROUPID suitably.
3. Deploy the application.
chmod +x one-click.ksh
./one-click.ksh
4. Access the application:http://<ec2-instance-ip>:8501
Core workflow
Load and chunk data: Currently, data is loaded from a static, dummy source. However, you can update this to a live data source to ensure the latest data and reports are always available. For details on data loading, refer to the documentation. 2. Embed and store: Each chunk is embedded using embed-english-v3.0, and both the original chunk and the vector are stored in a MongoDB collection:
A vector index in MongoDB enables fast, cosine-similarity-based lookups. MongoDB Atlas returns the top-k semantically similar documents, on top of which you can apply additional post filters to get more fine-grained results set in a bounded space.
4. Re-ranking for accuracy: Instead of relying solely on vector similarity, the retrieved documents are reranked using Cohere’s Rerank API, which is trained to order results by relevance. This dramatically improves answer quality and prevents irrelevant context from polluting the response.
A common limitation in RAG systems is that dense vector search alone may retrieve documents that are semantically close but not contextually relevant. The Cohere Rerank API solves this by using a lightweight model to score query-document pairs for relevance.
The ability to combine everything
The end application works and functions on a streamlit UI, as displayed below.
Figure 2. Working application with UI.
To achieve more direct and nuanced responses in data retrieval and analysis, you’ll find that the strategic implementation of prefilters is paramount. Prefilters act as an initial, critical layer of data reduction, sifting through larger datasets to present a more manageable and relevant subset for subsequent, more intensive processing. This not only significantly enhances the efficiency of queries but also refines the precision and interpretability of the results. For instance, instead of analyzing sales trends across an entire product catalogue, a prefilter can limit the analysis to a specific product line, thereby revealing more granular insights into its performance, customer demographics, or regional variations. This level of specificity enables the extraction of more subtle patterns and relationships that might otherwise be obscured within a broader, less filtered dataset.
Figure 3. Prefilters to be applied on top of MongoDB Atlas Vector Search.
Conclusion
Just by using MongoDB Atlas and Cohere’s API suite, you can deploy a fully grounded, semantically aware RAG system that is cost effective, flexible, and production grade. This quick-start enables your developers to build AI assistants that reason with your data without requiring extensive infrastructure.
Start building intelligent AI agents powered by MongoDB Atlas. Visit our GitHub repo to try out the quick-start and unlock the full potential of semantic search, secure automation, and real-time analytics. Your AI-agent journey starts now. Ready to learn more about building AI applications with MongoDB? Head over to our AI Learning Hub.
2025-07-22 12 days ago / 未收藏/ MongoDB | Blog/
发送到 kindle
With technology advancing and innovations emerging daily, customer expectations are also rising. What once served as a differentiator has now become a baseline, like personalization or omnichannel capabilities. Retail, as one of the fastest-moving industries, is often quick to adopt and deploy the latest innovations. But this agility comes with a challenge: keeping pace with technological advancements at every touchpoint while still delivering a high-quality, customer-centric experience that feels seamless and consistent across all channels. In physical stores, associates often play a critical role in closing the gap between online and offline channels. They act as brand ambassadors, providing advice, enhancing shopping experiences, and driving customer loyalty. Recent research has shown that 64% of shoppers are more likely to visit a physical store if sales associates are knowledgeable, and 75% are likely to spend more after receiving high-quality in-store service. This is why it is so important for businesses to equip their store associates with the right tools to succeed and deliver on this promise. This blog post will dive into the consequences of disconnected systems and the absence of real-time inventory, painting a clear picture of how—without a unified view of the business—even the most motivated associates are limited in their ability to provide the experiences customers expect. To overcome these obstacles, it’s essential to empower store associates through a unified commerce approach. But doing so requires a modern, flexible database that can securely integrate siloed complex data from multiple systems, providing 360 degrees of visibility of your data. MongoDB’s modern multi-cloud database, MongoDB Atlas, enables retailers to build agile, scalable solutions that support a unified data layer across experiences.
The challenge: Equipping store associates in an omnichannel world
As the retail landscape moves into an omnichannel environment, the role of the store associate also grows in responsibility and expectations. This blending of channels makes customer inquiries more complex for associates to handle; at the same time, rapidly changing inventory levels make it harder to provide accurate information. Equipping store associates with tools that empower them to be highly knowledgeable sources of information for customers presents challenges. Let’s examine two important ones:
1. Siloed systems
Data silos are a major obstacle for companies that aspire to be data-driven. When each system has its own unique rules and limited access, store associates struggle to retrieve key customer data, such as purchase history or preferences. This makes it difficult to support cross-channel requests like checking the status of a Buy Online, Pick Up in Store (BOPIS) order or confirming an online transaction. It also limits their ability to personalize in-store interactions and often requires additional steps or follow-ups. A well-defined data management strategy is key to developing a single view of data across an organization. MongoDB can help by managing complex data types, offering flexible schemas, and reducing complexity at a low cost.
2. Absence of real-time inventory
When associates lack real-time visibility into inventory, they can’t provide accurate product availability or pricing. Instead, they may need to physically check the storage room to locate items, keeping the customer waiting, generating even more dissatisfaction if the product is no longer available. Without a clear and current view of inventory, associates also miss opportunities to upsell or cross-sell related products. This lack of empowerment for store associates results in demotivated employees who are unable to perform at their best and frustrated customers, whose shopping experience suffers. Over time, this inefficiency in fulfilling requests and building deeper relationships will translate to lost sales opportunities and a disconnect between a brand’s promise and the in-store experience.
The solution: A unified data platform for store associate empowerment
To address these challenges, retailers need to shift toward a unified commerce business strategy—one that integrates all sales channels, data, and back-end systems into a seamless platform and provides a real-time view of the business. This unified approach ensures that store associates can access the same accurate and up-to-date information as any other part of the business. Unified commerce aims to connect all aspects of a business—including online and offline sales channels, inventory management, order fulfillment, marketing, and customer data—into a unified view. Without replacing existing systems, MongoDB Atlas enables them to work together through a unified data strategy, functioning as an operational data layer.
Figure 1. A unified system connecting online and offline aspects of a business.
MongoDB Atlas serves as the centralized data layer, integrating critical operational data such as orders, inventory, customer profiles, transactions, and more. Unlike traditional siloed systems, which require extensive transformation logic and coordination between systems that refresh on different schedules, MongoDB is built to handle complex data structures. This capability enables it to unify data in a single source of truth, eliminating the complexity of syncing multiple systems and formats. Consequently, it simplifies data management and provides the real-time and historical data access necessary for store operations. Giving store associates access to this unified view will boost their confidence and improve their speed in assisting customers.
Key capabilities empowering store associates
In store, a unified commerce strategy comes to life through a user-friendly application, often on a tablet or smartphone, designed to aid associates with daily tasks. Key capabilities include:
Intuitive search: Quickly locate products with full-text search (e.g., “The Duke and I book”), semantic search where context is crucial (e.g., “A romantic book saga for a teenager”), or hybrid search, which blends traditional keyword matching with semantic understanding for smarter results. AI-powered recommendations further enhance the personal shopper experience by suggesting similar or complementary products.
Access to real-time inventory: Instantly check stock availability in the current and nearby stores by connecting to existing inventory systems and real-time updates. An associate could say, “We’re out of stock, but the X location has 10 units.”
Seamless order management and cross-channel fulfillment: Enable follow-up actions like, “The X store has 10 units. Would you like me to place an order for home delivery or in-store pickup?”
Access to customer context: With permissioned access, enable associates to view relevant customer details, including previous purchases or saved products, to provide personalized assistance.
Figure 2. Benefits of unified commerce.
The technology foundation: Why MongoDB Atlas?
With the right modern multi-cloud database, the outlined key capabilities become a reality. MongoDB Atlas reduces complexity and enables this architecture through:
Scalability and a flexible document model: MongoDB Atlas supports complex data types, including vector embeddings, documents, graphs, and time series. This is ideal for diverse and evolving datasets like catalogs, customer profiles, inventory, and transactions.
Real-time data: Atlas enables seamless, real-time responses to operational data changes through Change Streams and Atlas Triggers. These capabilities make it easy to integrate with systems like shipping or inventory management, ensuring timely updates to the unified view.
Built-in search capabilities: Atlas provides native support of full-text Search ($search) and vector search ($vectorSearch) (through MongoDB Atlas Vector Search), which reduces complexity and simplifies the architecture by eliminating the need for third-party tools.
Robust enterprise security and data privacy: MongoDB Atlas provides the strong security required for giving store associates access to a unified view of sensitive data. MongoDB meets privacy regulations and offers built-in features like authentication, authorization, and full-lifecycle data encryption (at rest, in transit, and in use).
Consolidated operational data: Atlas acts as the core data layer, integrating information from systems like points of sale, e-commerce, and customer relationship management into a unified platform.
Figure 3. MongoDB Atlas’s key capabilities.
The business impact: Benefits for retailers and customers
A true unified commerce strategy delivers measurable value to both retailers and customers. Surveys show that 46% of businesses report increased sales and 44% report greater customer loyalty from unified commerce initiatives. Customers value consistency across channels and departments. Well-equipped associates can seamlessly guide customers between online and in-store experiences. In fact, 79% of customers expect consistent interactions across departments, yet 55% feel like they’re dealing with separate departments rather than one company working together. A unified commerce platform reduces this disconnect, improves operational efficiency and streamlines associate workflows, and enables associates to respond to complex inquiries. Equipped with accurate, real-time data, associates can speed up service and help customers find products faster, and companies can reduce out-of-stock frustration for both the associate and the customer. Associates can even offer follow-up actions. In fact, 70% of consumers say they’d be more loyal to a retailer if an out-of-stock item could be shipped directly to their home. Ultimately, having the information needed to effectively assist customers enhances the customer experience, leading to increased sales through better service and recommendations.
Final thoughts
Empowering store associates with real-time data, intelligent search, and cross-channel capabilities is a crucial component of a successful unified commerce strategy. Achieving that level of customer experience requires a powerful and flexible data foundation. MongoDB Atlas provides that foundation, enabling rapid development today, seamless scalability without downtime tomorrow, and secure, cost-efficient operations every day. Its flexible data model, real-time search, and unified data source make it ideal for building and evolving associate-focused solutions that drive business value. What’s more, IT teams benefit not only from a vast, engaged online developer community but also from dedicated expert support from MongoDB, ensuring guidance every step of the way. Explore our MongoDB for retail page to learn more about how MongoDB is helping shape the retail industry.
Discover how MongoDB Atlas can help you deliver seamless customer experiences across all channels.
2025-07-23 11 days ago / 未收藏/ I'm TualatriX/
发送到 kindle
我是在 WWDC25 期间直接把我的工作电脑 MacBook Pro 升级到 macOS 26 Beta 的。当时人还在 Apple Park 参加活动,后面也基本以玩为主,因此没有被这个系统影响到工作。 回国后,从游玩状态中调整过来,准备好好干活。但真的高强度使用 macOS 26 Beta 时,觉得非常别扭。首先,我的 M3 Max 的整体 UI 响应速度,就像回到了用一台 Intel 电脑;其次,Liquid Glass 非常不成熟,过度的动画、透明和阴影,始终觉得内容重点被夺走了;最后让我无法忍受的是,菜单上那些画蛇添足的图标,不再是原本干干净净的 macOS,让我有种在用 Windows 的感觉。于是我决定装双系统,回到 macOS 15 工作。 过去几年,基本每年我都会安装双系统开始我的 Beta 系统的体验,每年的原因都差不多,主要还是新系统无法跑最新 Xcode 稳定版本,虽然这个在今年被解决了,但在可用性方面却大大降低了。我相信(或期望)可用性问题在正式版本会解决(或者在 macOS 27、28)。但那是后话了,本篇我就简单介绍下我是如何进行「乾坤大挪移」式使用双系统。
如何安装双系统
昨天花了几小时装+配置好 macOS 15 环境后,整个立刻就感觉清爽、轻盈了起来。 在 Mac 上装双系统非常简单,只要打开 Disk Utility,新加一个 APFS 卷,然后去 App Store 下载最新 macOS 的稳定版本,然后把这个 macOS 装在新加卷上面就可以了。因为两个 macOS 可以互读硬盘,因此文件也可以共享,很快就可以把自己的需要的环境设置起来。 但是,今年我做了一些不一样的操作,我决定隔离两个系统的环境,进行「乾坤大挪移」。一个重要的出发点是,我的 macOS 26 Beta 的环境已经很乱了,我不想简单的把文档复制或链接过来,我想在使用过程中,把真正需要的文件挪过来,不要的文件就留在「老系统」,直到我不需要并抛弃它。
禁止当前系统索引另外一个系统的文件
默认情况下,双系统的 Mac 会挂载另一个系统的分区,Spotlight 也会自动去索引所有文件,于是你搜索的时候可能会出现重复的内容,这在我过去几年的双系统体验中是一个很烦恼的事情。而且即使在 Spotlight 中设置了排除项,重启以后依然会无效。 今年我找到了一个新方法,那就是在命令行层面禁止索引另一个系统的分区,真正做到互不影响。 禁止索引系统盘: sudo mdutil -i off /Volumes/Macintosh\ HD
禁止索引数据盘: sudo mdutil -i off /Volumes/Macintosh\ HD\ -\ Data
"Nick Schäferhoff" / 2025-07-22 12 days ago / 未收藏/ 岁月如歌/
发送到 kindle
Changing your domain name can feel intimidating and isn't without risks. In this tutorial, you'll learn everything you need to know to change your website's domain name with as little hassle as possible.
"Felix Reda" / 2025-07-23 11 days ago / 未收藏/ Todd Motto/
发送到 kindle
Open source software is critical infrastructure, but it’s underfunded. With a new feasibility study, GitHub’s developer policy team is building a coalition of policymakers and industry to close the maintenance funding gap. The post We need a European Sovereign Tech Fund appeared first on The GitHub Blog.
"alex.silk@okta.com" / 2025-07-22 12 days ago / 未收藏/ Auth0 Blog/
发送到 kindle
Discover how Auth0's new wave of Enterprise-Ready Identity solutions attract buyers, raise the security bar, and reduce customer onboarding costs via seamless integration.
Database normalization is an important process in relational database design aimed at organizing data to minimize redundancy, enhance data integrity, and improve database efficiency. Whether you’re a database administrator, developer, or data analyst, understanding normalization is crucial for creating scalable, reliable, and performant databases. Whether you’re aiming to normalize a database from scratch or improve an existing schema, this guide will walk you through every key step. We will discuss the basics of database normalization and get to know the major normal forms (1NF, 2NF, 3NF and BCNF) in this in-depth guide, provide a set of vivid examples along with transformations, and talk about the cases when it is better to normalize a database and when not.
Database normalization is a step by step approach to structuring data in a way that reduces redundancy and preserves data integrity.
The process is organized into a series of normal forms 1NF, 2NF, 3NF, and BCNF, each designed to resolve specific types of data anomalies and structural problems.
Applying normalization helps prevent insertion, update, and deletion anomalies, leading to more consistent and maintainable databases.
This guide provides clear, step-by-step examples and transformations for each normal form, illustrating how to convert poorly structured tables into optimized ones.
You’ll also learn about the pros and cons of normalization versus denormalization, so you can make informed decisions about which approach best fits your needs.
In addition, the guide includes practical SQL tips, answers to common questions, and further resources to help you confidently implement normalization in real-world database projects.
Before diving into this guide on database normalization, you should have a basic understanding of:
Relational databases: Familiarity with tables, rows, and columns.
SQL basics: Knowing how to write simple SELECT, INSERT, and JOIN queries.
Primary and foreign keys: Understanding how keys are used to uniquely identify records and establish relationships.
Data types: Awareness of common data types like INT, VARCHAR, and DATE. See our SQL data types overview for a quick refresher.
While this guide explains normalization in detail with examples, having this foundational knowledge will help you follow along more effectively and apply the concepts in real-world scenarios.
Database normalization is a systematic process used in relational database design to organize data efficiently by dividing large, complex tables into smaller, related tables. The main motive of this is to confirm redundancy of data (duplicate data) is minimal and unwanted attributes such as insertion, update and deletion anomalies are avoided. Normalization does this through a set of rules known as the normal forms each having distinct requirements that narrow down how the database would be designed. Definition:
Database normalization is the process of structuring a relational database to reduce redundancy and improve data integrity through a set of rules called normal forms.
Understanding how to normalize a database helps eliminate redundancy and improve data clarity, especially in transactional systems. Different types of databases like relational, document, and key-value handle normalization differently based on their design models; you can learn more about these categories in our guide to types of databases.
Eliminate Data Redundancy: By breaking data into logical tables and removing duplicate information, normalization helps us make sure that each piece of data is stored only once. This reduces storage requirements and prevents inconsistencies.
Confirming Data Integrity: Normalization enforces data consistency by establishing clear relationships and dependencies between tables. This maintains accurate and reliable data throughout the database.
Prevent Anomalies: Proper normalization prevents common data anomalies:
Insertion Anomaly: Difficulty adding new data due to missing other data.
Update Anomaly: Inconsistencies that arise when updating data in multiple places.
Deletion Anomaly: Unintended loss of data due to deletion of other data.
Optimize Query Performance: Well-structured tables can improve the efficiency of queries, especially for updates and maintenance, by reducing the amount of data processed.
Database normalization is important for several reasons. It plays a foundational role in confirming that databases are not just collections of tables, but well-structured systems capable of handling growth, change, and complexity over time. By applying normalization, organizations can avoid a wide range of data-related issues while providing consistency and performance across applications, whether in traditional RDBMS or modern workflows like data normalization in Python. This also applies to statistical and scientific environments. See how it works in practice with our guide to normalizing data in R.
Consistency and Accuracy: Without normalization, the same data may be stored in multiple places, leading to inconsistencies and errors. Normalization ensures that updates to data are reflected everywhere, maintaining accuracy is one of the primary benefits of database normalization.
Efficient Data Management: Normalized databases are easier to maintain and modify. Changes to the database structure or data can be made with minimal risk of introducing errors.
Scalability: As databases grow, normalized structures make it easier to scale and adapt to new requirements without major redesigns.
Data Integrity Enforcement: By defining clear relationships and constraints, normalization helps enforce business rules and data integrity automatically.
Reduced Storage Costs: Eliminating redundant data reduces the amount of storage required, which can be significant in large databases.
The main features of database normalization include:
Atomicity: Data is broken down into the smallest meaningful units, ensuring that each field contains only one value (no repeating groups or arrays).
Logical Table Structure: Data is organized into logical tables based on relationships and dependencies, making the database easier to understand and manage.
Use of Keys: Primary keys, foreign keys, and candidate keys are used to uniquely identify records and establish relationships between tables.
Hierarchical Normal Forms: The process follows a hierarchy of normal forms (1NF, 2NF, 3NF, BCNF, etc.), each with stricter requirements to further reduce redundancy and dependency.
Referential Integrity: Relationships between tables are maintained through foreign key constraints, ensuring that related data remains consistent.
Flexibility and Extensibility: Normalized databases can be easily extended or modified to accommodate new data types or relationships without major restructuring.
By following the principles of normalization, database designers can create robust, efficient, and reliable databases that support the needs of modern applications and organizations.
Before we dive into each normal form, here’s a quick visual summary of how 1NF, 2NF, and 3NF differ: To help you quickly compare the most common normal forms, here’s a summary table outlining their purpose and focus:
Normal Form
Rule Enforced
Problem Solved
Dependency Focus
1NF
Atomicity
Repeating/multi-valued data
None
2NF
Full Dependency
Partial dependency
Composite Primary Key
3NF
Transitive
Transitive dependency
Non-key attributes
BCNF
Superkey Rule
Remaining anomalies
All determinants
Database normalization is structured around a series of increasingly strict rules called normal forms. Each normal form addresses specific types of redundancy and dependency issues, guiding you toward a more robust and maintainable relational schema. The most widely applied normal forms are First Normal Form (1NF), Second Normal Form (2NF), Third Normal Form (3NF), and Boyce-Codd Normal Form (BCNF).
First Normal Form (1NF) is the initial stage in the process of database normalization. It ensures that each column in a table contains only atomic, indivisible values, and that each row is uniquely identifiable. By removing repeating groups and multi-valued attributes, 1NF lays the groundwork for a more organized and consistent database structure. This makes querying, updating, and maintaining data more efficient and reliable, and it helps avoid redundancy right from the beginning of database design. Key Requirements:
All columns contain atomic values (no lists, sets, or composite fields).
Each row is unique (typically enforced by a primary key).
No repeating groups or arrays within a row.
Each column contains values of a single data type.
Example: Transforming to 1NF
Suppose you have a table tracking customer purchases, where the “Purchased Products” column contains a comma-separated list of products:
Customer ID
Customer Name
Purchased Products
101
John Doe
Laptop, Mouse
102
Jane Smith
Tablet
103
Alice Brown
Keyboard, Monitor, Pen
Why is this not in 1NF?
Non-atomic values: “Purchased Products” contains multiple items per cell.
Querying and updating are complex: Searching for customers who bought “Mouse” requires string parsing.
Data integrity risks: No way to enforce referential integrity between products and customers.
Inconsistent data entry: Different delimiters or typos can creep in.
Real-World Impact:
Reporting (e.g., “Who bought a Laptop?”) is error-prone.
Updates (e.g., renaming “Mouse” to “Wireless Mouse”) are tedious and unreliable.
Referential integrity cannot be enforced.
Real-World Issues:
Reporting challenges: Generating reports such as “How many customers bought a Laptop?” becomes complicated, as you cannot simply filter a column for “Laptop”, you must parse the string.
Update anomalies: If a product name changes (e.g., “Mouse” to “Wireless Mouse”), you must update every occurrence in every cell, increasing the risk of missing some entries.
Data integrity risks: There is no way to enforce referential integrity between products and customers, which can lead to orphaned or inconsistent data.
Summary:
This unnormalized table structure is easy to read for small datasets but quickly becomes unmanageable and unreliable as the amount of data grows. To comply with First Normal Form (1NF), we must ensure that each field contains only a single value, and that the table structure supports efficient querying, updating, and data integrity. Problems with the Unnormalized Table:
Non-atomic values: The “Purchased Products” column contains multiple items in a single cell, making it difficult to query or update individual products.
Data redundancy and inconsistency: If a customer purchases more products, the list grows, increasing the risk of inconsistent data entry (e.g., different delimiters, typos).
Difficulties in searching and reporting: Queries to find all customers who purchased a specific product become complex and inefficient.
Transformation Steps to Achieve 1NF:
Identify columns with non-atomic values: In this case, “Purchased Products” contains multiple values.
Split the multi-valued column into separate rows: Each product purchased by a customer should be represented as a separate row, ensuring that every field contains only a single value.
Transformed Table in 1NF:
Customer ID
Customer Name
Product
101
John Doe
Laptop
101
John Doe
Mouse
102
Jane Smith
Tablet
103
Alice Brown
Keyboard
103
Alice Brown
Monitor
103
Alice Brown
Pen
Explanation:
Each row now represents a single product purchased by a customer.
All columns contain atomic values (no lists or sets).
The table can be easily queried, updated, and maintained. For example, finding all customers who purchased “Mouse” is now straightforward.
Key Takeaways:
1NF requires that each field in a table contains only one value (atomicity).
Repeating groups and arrays are eliminated by creating separate rows for each value.
This transformation lays the foundation for further normalization steps by ensuring a consistent and logical table structure.
Definition:
A table is in 2NF if it is in 1NF and every non-prime attribute (i.e., non-primary key attribute) is fully functionally dependent on the entire primary key. This addresses partial dependencies, where a non-key attribute depends only on part of a composite key.
Example Transformation to 2NF
1NF Table:
Order ID
Customer ID
Customer Name
Product
201
101
John Doe
Laptop
202
101
John Doe
Mouse
203
102
Jane Smith
Tablet
Issue:
“Customer Name” depends only on “Customer ID”, not the full primary key (“Order ID”, “Customer ID”). This is a partial dependency. Normalization to 2NF:
Definition:
A table is in 3NF if it is in 2NF and all the attributes are functionally dependent only on the primary key, there are no transitive dependencies (i.e., non-key attributes depending on other non-key attributes).
Example Transformation to 3NF
2NF Table:
Order ID
Customer ID
Product
Supplier
201
101
Laptop
HP
202
101
Mouse
Logitech
203
102
Tablet
Apple
Issue:
“Supplier” depends on “Product”, not directly on the primary key. Normalization to 3NF:
Move product and supplier information to separate tables.
To further clarify the 2NF to 3NF normalization process and illustrate the elimination of transitive dependencies, refer to the schema diagram below: This transformation improves maintainability and aligns with best practices for how to normalize a database effectively.
Definition:
BCNF is a stricter version of 3NF. A table is in BCNF if, for every non-trivial functional dependency X → Y, X is a superkey. In other words, every determinant must be a candidate key. When is BCNF Needed?
BCNF addresses certain edge cases where 3NF does not eliminate all redundancy, particularly when there are overlapping candidate keys or complex dependencies.
Example Transformation to BCNF
Let’s walk through a detailed example of how to transform a table that is in Third Normal Form (3NF) but not in Boyce-Codd Normal Form (BCNF). Scenario:
Suppose we have a university database that tracks which students are enrolled in which courses, and who teaches each course. The initial table structure is as follows: Original Table:
StudentID
Course
Instructor
1
Math
Dr. Smith
2
Math
Dr. Smith
3
History
Dr. Jones
4
History
Dr. Jones
Explanation of Columns:
StudentID: Unique identifier for each student.
Course: The course in which the student is enrolled.
Instructor: The instructor teaching the course.
Functional Dependencies in the Table:
(StudentID, Course) → Instructor
Each unique combination of student and course determines the instructor for that course.
Course → Instructor
Each course is always taught by the same instructor.
Candidate Keys:
The only candidate key in this table is the composite key (StudentID, Course), since both are needed to uniquely identify a row.
Why is this Table in 3NF?
All non-prime attributes (Instructor) are fully functionally dependent on the candidate key (StudentID, Course).
There are no transitive dependencies (i.e., no non-prime attribute depends on another non-prime attribute through the candidate key).
Why is this Table Not in BCNF?
The functional dependency Course → Instructor exists, but “Course” is not a superkey (it does not uniquely identify a row in the table).
BCNF requires that for every non-trivial functional dependency X → Y, X must be a superkey. Here, “Course” is not a superkey, so this violates BCNF.
How to Normalize to BCNF: To resolve the BCNF violation, we need to decompose the table so that every determinant is a candidate key in its respective table. This is done by splitting the original table into two separate tables:
StudentCourses Table:
This table records which students are enrolled in which courses.
StudentID
Course
1
Math
2
Math
3
History
4
History
Primary Key: (StudentID, Course)
This table no longer contains the Instructor column, so there are no functional dependencies that violate BCNF.
CourseInstructors Table:
This table records which instructor teaches each course.
Course
Instructor
Math
Dr. Smith
History
Dr. Jones
Primary Key: Course
The dependency Course → Instructor is now valid, as “Course” is the primary key (and thus a superkey) in this table.
Resulting Structure and Benefits:
All functional dependencies in both tables have determinants that are candidate keys, so both tables are in BCNF.
Data redundancy is reduced: the instructor for each course is stored only once, rather than repeated for every student enrolled in the course.
Updates are easier and less error-prone: if an instructor changes for a course, you only need to update one row in the CourseInstructors table.
Summary Table of the Decomposition:
Table Name
Columns
Primary Key
Purpose
StudentCourses
StudentID, Course
(StudentID, Course)
Tracks which students are in which courses
CourseInstructors
Course, Instructor
Course
Tracks which instructor teaches each course
By decomposing the original table in this way, we have eliminated the BCNF violation and created a more robust, maintainable database structure. Summary:
Applying these normal forms in sequence helps you design databases that are efficient, consistent, and scalable. For most practical applications, achieving 3NF (or BCNF in special cases) is sufficient to avoid the majority of data anomalies and redundancy issues.
Understanding the trade-offs between normalization and denormalization is crucial for designing databases that are both performant and maintainable. The tables below summarize the key advantages and disadvantages of each approach.
When designing a database, it’s important to balance data integrity with system performance. Normalization improves consistency and reduces redundancy, but can introduce complexity and slow down queries due to the need for joins. Denormalization, on the other hand, can speed up data retrieval and simplify reporting, but increases the risk of data anomalies and requires more storage. Understanding these trade-offs helps you choose the right approach for your application’s specific needs and workload patterns.
Normalized databases store related data in separate tables, which means retrieving information often requires joining these tables together. This structure assists in ensuring the constancy and integrity of data but may slacken the speed of querying particularly in case of intricate queries or data sets of significant sizes. Denormalized databases on the other hand contain related data in the same table and hence, require fewer joins. This can speed up the read operations, but this would multiply the storage needs and the possibility of duplicating or non-consistent data. Summary of Trade-offs:
Normalized Models: Provide strong data integrity and make updates easier, but can result in slower queries that require many joins.
Denormalized Models: Offer faster reads and simpler reporting, but are more susceptible to data duplication and update anomalies.
Normalization is generally best during the initial design of a database. However, denormalization can be helpful in situations where performance is critical or the workload is heavily focused on reading data. Common scenarios where denormalization is advantageous include:
Analytics and business intelligence (BI) platforms that need to quickly aggregate data across wide tables.
Content delivery systems that use denormalized cache layers to speed up response times.
Data warehouses where historical data snapshots and simplified queries are more important than frequent updates.
Before denormalizing, always weigh the potential performance improvements against the increased risk of data duplication and the added complexity of maintaining consistency.
With the rise of AI, real-time analytics, and distributed systems, the approach to normalization is changing. While traditional relational databases (RDBMS) still benefit from strict normalization, modern data systems often use a mix of normalized and denormalized structures:
Big Data platforms (like Hadoop and Spark) typically use denormalized, wide-column formats to improve performance and enable parallel processing.
NoSQL databases (such as MongoDB and Cassandra) focus on flexible schemas and high performance, often avoiding strict normalization.
AI and machine learning pipelines prefer denormalized datasets to reduce pre-processing and speed up model training.
For hands-on examples of this transformation, see our guide on how to normalize data in Python. R users working with data frames and statistical models can also benefit from proper normalization techniques, explore more in our tutorial on how to normalize data in R. Even as these new technologies emerge, understanding normalization remains important, especially when building core relational systems or preparing data for downstream processes. Many modern architectures use normalized databases for core storage, then create denormalized layers or views to optimize performance for specific use cases.
When designing your tables, it’s also important to choose appropriate data types for each column, refer to our SQL data types tutorial to ensure you’re using the right types for performance and storage efficiency.
Q: What is 1NF, 2NF, and 3NF in database normalization? A: These are the first three stages of database normalization. 1NF removes repeating groups and ensures atomicity. 2NF builds on this by eliminating partial dependencies, meaning every non-key attribute must depend on the entire primary key. 3NF removes transitive dependencies, ensuring non-key attributes only depend on primary keys. Each stage progressively refines the data model, reducing redundancy and improving data consistency. Understanding these forms is crucial for creating scalable, maintainable relational database schemas. Q: What is normalization in a database, and why is it important? A: Normalization is a database design technique that structures data to reduce duplication and improve data integrity. By organizing data into related tables and applying rules (normal forms), it prevents anomalies during data insertion, updates, and deletions. Normalization also makes querying more efficient and ensures logical data grouping. It’s especially important in relational databases where accuracy and consistency are critical. For systems handling large volumes of transactions or frequent updates, normalization is foundational for performance and reliability. Q: What are the rules of database normalization? A: Normalization follows a hierarchy of normal forms 1NF, 2NF, 3NF, and BCNF each with stricter rules. 1NF requires atomic values and unique rows. 2NF requires full functional dependency on the primary key. 3NF eliminates transitive dependencies. BCNF ensures that every determinant is a candidate key. These rules aim to eliminate redundancy, ensure data integrity, and optimize storage. Proper application of these rules results in more reliable, maintainable, and scalable database schemas. Q: How do you normalize a database using SQL? A: Normalizing a database in SQL involves decomposing large tables into smaller ones and establishing foreign key relationships. For example, to convert a table with customer and order data into 2NF, you’d separate customer details into one table and orders into another, linking them with a foreign key. Use SQL CREATE TABLE, INSERT, and FOREIGN KEY constraints to maintain referential integrity. Normalization typically involves restructuring existing data with careful planning to avoid loss or inconsistency during transformation. Q: What are the benefits and drawbacks of normalization? A: Advantages of normalization are less data redundancy, data integrity, and easy updates. It makes sure that modification done at a certain point is reproduced in other connected documents in an appropriate way. Its disadvantages however, are that it has an overhead performance with regards to joins and that it is very complex to write queries especially in highly normalized databases. Denormalization can be more preferable in high-read situations such as analytics dashboards. The rationale to normalize should, therefore, follow the needs of use cases, performance requirements, and maintenance. Q: What is the difference between normalization and denormalization? A: Normalization breaks down data into smaller, related tables to reduce redundancy and improve consistency. Denormalization, on the other hand, combines related data into fewer tables to speed up read operations and simplify queries. While normalization improves data integrity and is ideal for transaction-heavy systems, denormalization is often used in read-heavy systems like reporting tools. The choice depends on the trade-off between write efficiency and read performance. Q: When should I denormalize a database instead of normalizing it? A: Denormalization is suitable when read performance is critical and the data doesn’t change frequently. Use it in analytics, reporting, or caching layers where real-time joins would impact speed. Also, in NoSQL or big data environments, denormalization aligns with the storage and access patterns. However, it should be approached cautiously since it increases data duplication and the risk of inconsistency. In many systems, a hybrid model using both normalized core tables and denormalized views or summaries works best. Q: Is normalization still relevant for modern databases and AI applications? A: Yes, normalization remains essential, especially for transactional systems and data integrity-focused applications. In AI and big data contexts, normalized structures are often used as the source of truth before being transformed into denormalized datasets for training or analysis. Even in NoSQL and distributed systems, understanding normalization helps in modeling relationships and verifying consistency at the design level. While modern workloads may relax strict normalization, its principles are foundational for long-term data quality and manageability.
Knowing how to normalize a database also makes it possible to make effective, scalable systems with minimal duplication and long-term stability. In terms of normalization forms, 1NF, 2NF, 3NF, BCNF Determining the correct form of normalization, by diminishing multiple versions of the data, you will avoid redundancy and uphold integrity of the data and thus enhance the performance of the system. Assess your database requirements and strike the balance between normalization and denormalization depending on the use-case details.
"Julie Rudd" / 2025-07-22 12 days ago / 未收藏/ Elasticsearch/
发送到 kindle
Customer support is about creating seamless customer experiences. These days, customers expect prompt resolutions to their problems. Traditional tiered support models, built to serve internal teams rather than the end user, often stand in the way. These models introduce delays, force customers to repeat themselves, and lead to frustration. Generative AI (GenAI) and knowledge-centered service (KCS) flip that model on its head. The thorough product documentation and articles from KCS fuel the generative AI experience by delivering a data foundation that provides end users with accurate and relevant answers built on your knowledge bases. Your customers are empowered to self-serve to get relevant, personalized answers in real time. Along with customer self-service, support teams can easily discover answers through conversational search so they can solve customers’ problems faster. By pulling from relevant data sources like case history resolutions, tech docs, and more, generative AI can collapse outdated support tiers and help support teams get ahead of issues instead of playing catch-up. The pitfalls of the traditional tiered support modelIn the era of high-speed everything, customer expectations are higher than ever. Traditional support models just can’t provide instant answers, seamless digital experiences, or immediate issue resolutions. Yet, I see many organizations relying on outdated tiered support models that are slow, fragmented, and frustrating for users, and they ultimately stand in the way of the experience customers expect. Traditional support tiers were designed to manage internal workload, not customer experience. A customer query comes in, and it gets passed to human agents, from tier one to tier two and on to tier three until the issue is resolved. Inevitably, customers must repeat themselves as their issue escalates. They’re left waiting as each escalation introduces delays while cases are reassigned. Now, add that support teams are siloed and deal with uneven knowledge distribution and rigid workflows that prioritize case routing over resolution quality. The result? Customers feel unheard, issues linger, and brand loyalty erodes. Empowering customers to self-serve When given the choice, customers prefer self-service support channels. They’re busy — they want to search, find, fix, and move on. Collapsing the traditional tiered support model with GenAI opens up something powerful: the opportunity for customers to solve their issues on their own. When customers can self-serve, they can alleviate the fatigue of searching through knowledge articles and repeating themselves to support representatives as their case goes up the tiers. This enables support engineers to create capacity for customers who truly need assisted support or focus on other high-value work. That means more time can be spent solving complex problems and ensuring customers are making the most of the product. Generative AI can help create more intuitive self-service experiences that don’t just search — they draft initial replies or augment case summaries. Imagine: Instead of static FAQs or clunky knowledge bases, customers interact with GenAI-powered assistants that understand context, intent, and nuance. Conversational AI understands multi-turn dialogue and adapts based on user behavior. Predictive suggestions surface relevant solutions before a customer even finishes typing. Intelligent content surfacing dynamically pulls the right articles, steps, or documentation based on issue type, customer history, and product usage. Self-service offers organizations a strategic advantage. When done well, it delivers faster resolutions, boosts customer satisfaction, and scales far more efficiently than traditional case queues. The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all. In this blog post, we may have used or referred to third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use. Elastic, Elasticsearch, and associated marks are trademarks, logos, or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos or registered trademarks of their respective owners.
"Ksenia Vasileva" / 2025-07-22 12 days ago / 未收藏/ Elasticsearch/
发送到 kindle
Version 9.0.4 of the Elastic Stack was released today. We recommend you upgrade to this latest version. We recommend 9.0.4 over the previous versions 9.0.3 The 9.0.4 Release contains various performance and stability improvements across the stack.
Logstash's persistent queue now has significantly higher throughput when its workers are caught up. We eliminated lock contention in pipeline workers to ensure that queue writers have priority when there aren't yet enough events in the queue to fill batches. Pipelines tuned with larger batch sizes will see greater benefits. For details of the issues that have been fixed and a full list of changes for each product in this version, please refer to the release notes.
"Ksenia Vasileva" / 2025-07-22 12 days ago / 未收藏/ Elasticsearch/
发送到 kindle
Version 8.17.9 of the Elastic Stack was released today. We recommend you upgrade to this latest version. We recommend 8.17.9 over the previous versions 8.17.8 The 8.17.9 Release contains various performance and stability improvements across the stack.
Logstash's persistent queue now has significantly higher throughput when its workers are caught up. We eliminated lock contention in pipeline workers to ensure that queue writers have priority when there aren't yet enough events in the queue to fill batches. Pipelines tuned with larger batch sizes will see greater benefits. For details of the issues that have been fixed and a full list of changes for each product in this version, please refer to the release notes.
"Chris Reddington" / 2025-07-23 11 days ago / 未收藏/ The GitHub Blog/
发送到 kindle
If you’ve ever dusted off an old project and thought, “How did I leave things in such a mess?”, you’re in good company. On my latest Rubber Duck Thursdays stream, I dove back into my OctoArcade Next.js app, only to rediscover a host of UI gremlins. So, we experimented with something that felt like magic: letting GitHub Copilot agent mode, paired with Playwright MCP server, identify and fix UI bugs. Along the way, I learned (again) how crucial it is to provide AI tools like Copilot with clear, detailed requirements. Let’s walk through how I used these agentic tools to debug, test, and (mostly) solve some tricky layout issues, while covering practical tips for anyone looking to leverage Copilot’s agent workflows in real-world projects.
The setup: Revisiting OctoArcade (and its bugs)
I started by firing up OctoArcade, my collection of GitHub-themed mini-games built with Next.js and TypeScript. Within minutes, I realized I had been introducing a new game to the app, but hadn’t quite gotten around to fixing some bugs. Here’s what we accomplished in one stream session:
Problem: Navigation header overlapping game content across all games
Solution: Copilot agent mode and Playwright MCP server identified the issue through visual inspection, and implemented a global header fix
Bonus: Fixed some additional UI issues (unintended gaps between the game canvas and footer) discovered during testing
Result: Hands-off debugging that solved problems I’d stepped away from, and had previously spent some cycles on fixing
Let me walk you through how this worked and what you can learn for your own debugging workflows.
Making sure Copilot custom instructions are set up
With my environment set up in VS Code Insiders, I checked that my Copilot custom instruction files (.github/copilot-instructions.md, *.instructions.md files) were up to date. This is usually my first step before using any agentic features, as these instructions provide important context on my expectations, coding styles, and working practices — influencing how Copilot responds and interacts with my codebase. In my last blog post, we spent time exploring recommended practices when setting up Copilot custom instructions. We also covered how the copilot-setup-steps.yml sets up a developer environment when using Copilot coding agent. Take a look at that blog post on using GitHub Copilot coding agents to refactor and automate developer workflows to learn more. Always keep your Copilot custom instructions current (including descriptions of your repository structure, common steps like building and testing, and any expectations before making commits). Copilot agents depend on this context to deliver relevant changes. When I think my instructions file is out of date, I typically prompt Copilot in agent mode with a prompt along the lines of:
Based on the #codebase, please can you update the custom instructions file for accuracy? Please make sure to keep the structure (i.e. headings etc.) as-is. Thanks!
In some of my instruction files, I’ve even instructed Copilot to keep key documentation (README, .github/copilot-instructions.md, etc.) up to date when it makes significant changes (like refactoring files or adding new features).
Agentic debugging: UI troubleshooting with Playwright MCP
Playwright MCP server is a powerful tool for end-to-end testing and UI automation. Since it’s an MCP server, you can access it through your favorite AI tools that support the Model Context Protocol, like Copilot agent mode and Copilot coding agent! In agent mode, Copilot can use Playwright’s structured tools to:
Load web pages
Simulate user actions (clicks, navigation)
Inspect rendered layouts without needing vision models
This means you can ask Copilot to “see” what a human would, spot layout issues, and even propose CSS or component fixes. To get started with Playwright, it’s as easy as adding the below to your MCP configuration:
With access to a new set of tools to solve the UI challenges, it was time to point Copilot at the problem. Meaning, I now had the task of clearly defining the requirements in my initial prompt…easier said than done.
The debugging journey: Real-time fixes and lessons learned
1. Describe the problem and let agent mode work
I noticed that, in several pages, the main content was tucked behind the navigation bar. This was particularly noticeable on any pages that rendered games. On some pages (like OctoPong), I saw inconsistent spacing between game elements and the footer. To get Copilot agent mode started, I aimed to be as explicit as possible in my prompts:
I have spotted that there is a bit of a UI error. It seems like the main content of any page "starts" behind the navigation bar. This is more evident on the games like octosnap, octopong and octobrickbreaker.
Can you take a look at the site using Playwright (you'll need to spin up an instance of the server), take a look at the pages, and then investigate? Thanks!
It loaded up the pages to configure each game, but didn’t try loading the games themselves (so missed some context). I followed up in a separate prompt:
Sorry, I wanted you to take a look when a game is actually loaded too. Can you play the game Octopong and Octosnap – I think it’s very visible in those? Do that before you build a plan.
Diagnose where and why content was hidden or misaligned
Ultimately, we had to evolve the way that we were rendering the navigation bar. The current implementation had a separate navigation bar (DynamicHeader component) on each of the game pages with its own local state, overlaying the “main” navigation bar. Instead, Copilot suggested using the navigation bar from the root layout and passing the relevant context up, so that only one component is updated and the root layout gets updated as needed.. Hands-off debugging: At this stage, I was literally hands off, watching as Copilot tried fixes, reran the app, and checked the results visually. As it implemented the new approach with a new header-context file, Copilot recognized linting errors, and iteratively fixed them.
2. Iterating on UI requirements
Fixing bugs is rarely one-and-done. I noticed another bug, specifically for OctoPong. There was a small gap between the game board and the footer, which didn’t show up clearly on the livestream, but was noticeable on my own screen. Fortunately as developers, we’re used to small iterative and incremental improvements. So once again, I turned to Copilot. However, as I iterated, Copilot would make changes, but they didn’t fully achieve what I needed. The problem wasn’t Copilot though; it was me and my unclear requirements.
Prompt
Result
Reflection
I’ve noticed a minor UI bug on the Octopong game page (this only happens when the game is actually live). There is a small space between the game itself and the footer. I want the game to extend all the way to the footer (not necessarily push the footer beyond the fold though). Can you use the Playwright MCP server to explore what’s going on, build a structured plan / todo list to resolve the actions? Thanks
It achieved what I had asked, but the pong paddles no longer displayed (which was a side effect of the container now being 0 height). Through no fault of Copilot, I hadn’t asked for the game components (e.g. Paddle/Ball) to be visible in the game area. The game was still playing (in a 0 height container), but the key components were not visible to me as the player.
– Good clarity on tools to use.
– Good clarity on asking for a plan (as Copilot asked me to review/approve before making the changes).
– Lack of clarity on the full requirements (i.e. having the game components be visible and working).
Just to jump in, can you test again? It looks like the paddles and the ball are now missing as a result of the change?
The game began working again, however it introduced the gap that we early sought to resolve.
– Solved the immediate challenge of making game components visible.
– Lack of clarity that the earlier requirements were still required.
Can you check the game once again? The spacing issues are still there.
The requirements are:
1. The game is playable (i.e. balls and paddles are visible and one paddle is usable for the player). 2. The game area covers the “full space” between header and footer.
I think the space problem is back. You must meet both requirements please, thanks.
Once again, Copilot fulfilled the requirements! But this time, the game extended beyond the viewport, and so a user would have to scroll to move the paddle to prevent the ball scoring against them (which is not an ideal experience!).
– Solved all of the requirements we outlined
– Lack of clarity in the actual requirements (that the game should not extend beyond the viewport).
Thanks! Sorry, I forgot to give you a third requirement. Your solution makes the game extend beyond the fold, which makes the user have to “scroll” to play the game.
These are the requirements you must meet:
1. The game is fully functional (paddles/ball working and visible). 2. There is no space between the game and the footer. 3. The game must not extend beyond the fold (i.e. the user must not have to scroll to see any part of the game board. So the game board at maximum must end at the bottom of the screen). The footer can be below the fold.
Please feel free to reword/rewrite my requirements, as I struggled to define them. Make sure you confirm with me the requirements are accurate.
Success! After we prompted Copilot with our full requirements, it was able to think through and iteratively approach the problem to get to the working layout.
– A full set of requirements solved all of the requirements we outlined.
– While there were some minor issues in the mobile view, (a small gap between the navigation bar and game), other pages hadn’t yet been optimised for mobile. Since this isn’t a priority, it can be a task for later.
Each prompt brought incremental improvements, but also new side effects (like games extending past the viewport or missing paddles in Pong).
Key insight: Context is important, and making sure that we clearly articulate our requirements is a key part of that. The biggest challenge wasn’t technical, but precisely describing what I wanted. Getting the requirements right took several attempts…And lots of feedback from our viewers in the livestream chat.
Practical tips: Working with Copilot agent mode and MCP servers
Here’s what I learned (or relearned) during this session:
Keep Copilot custom instructions up to date: The agent relies on these files for repo context and best practices.
Give Copilot more power with MCP: Playwright MCP enables true end-to-end testing and UI inspection, making it invaluable for debugging complex web apps.
Be explicit with requirements: Like any collaborator, Copilot only knows what you tell it. List out your must-haves, expected behaviors, and edge cases.
Iterate in small steps: Commit changes frequently. It’s easier to roll back and diagnose issues when your history is granular.
Conclusion: Progress, not perfection
This live debugging session reminded me of two things:
Agentic tools like Copilot and Playwright MCP can genuinely accelerate troubleshooting. Especially when you provide the right context.
Describing requirements is hard. And that’s okay! Iteration, feedback, and even a few missteps are part of the process (both in terms of learning, and solving bugs).
If you’re navigating similar challenges, dive in, experiment, and remember: progress beats perfection.
Describe your bug or feature clearly in a new chat with Copilot agent mode.
Let Copilot propose and apply fixes. But always review code changes and test results.
Iterate on requirements based on what you see. Clarify as needed. Make sure you’re being clear in your requirements too.
Commit frequently! Work in a branch and save your progress at each step.
Are you using the Playwright MCP server for UI testing? Or maybe you have another favorite MCP server? Let us know — we’d love to hear how you’re using Copilot agent mode and MCP servers as part of your development workflow!
"Eleftheria Drosopoulou" / 2025-07-21 13 days ago / 未收藏/ Java Code Geeks/
发送到 kindle
In Java, working with collections in a multi-threaded environment can lead to race conditions, data corruption, and unexpected behavior if the collections are not thread-safe. Java provides multiple ways to create thread-safe maps, but two of the most discussed are: ConcurrentHashMap SynchronizedMap (usually via Collections.synchronizedMap()) Both approaches serve different concurrency needs, and choosing the right …
"Yatin Batra" / 2025-07-21 13 days ago / 未收藏/ Java Code Geeks/
发送到 kindle
Text-to-SQL is a powerful application of large language models (LLMs) like GPT that enables users to interact with a database using natural language. Let us delve into understanding how to build Text-to-SQL using LLM. 1. What is an OpenAI and LLM? OpenAI is an AI research and deployment company focused on ensuring that artificial general …
"Yatin Batra" / 2025-07-21 13 days ago / 未收藏/ Java Code Geeks/
发送到 kindle
Hibernate is a Java ORM tool that allows interaction with relational databases using entity objects. However, it lacks native support for SQL UNION in JPQL/HQL. Let us delve into understanding Hibernate unions and how they can be implemented effectively with consistent results across different approaches. 1. What is Hibernate? Hibernate is a powerful object-relational mapping …
"Eleftheria Drosopoulou" / 2025-07-22 13 days ago / 未收藏/ Java Code Geeks/
发送到 kindle
Architecting Large Desktop Applications That Can Be Extended at Runtime Modern desktop applications often require flexibility, extensibility, and modularity, especially when they grow over time or are built by multiple teams.Swing, though mature, is still widely used for building Java GUIs in industries like banking, logistics, and engineering. But how do you architect a large …
"Eleftheria Drosopoulou" / 2025-07-22 12 days ago / 未收藏/ Java Code Geeks/
发送到 kindle
When working with Java Persistence API (JPA), managing entity state transitions can become complex—especially when you need to enforce validation rules, audit changes, or initialize data automatically. Fortunately, JPA provides a set of Entity Lifecycle Events that let you hook into different phases of an entity’s journey, from creation to deletion. In this article, you’ll …
"Yatin Batra" / 2025-07-22 12 days ago / 未收藏/ Java Code Geeks/
发送到 kindle
Controlling access to APIs based on the requested URL and HTTP method is a common requirement in modern web applications. Let us delve into understanding how Spring Security enables URL and HTTP method-based authorization to secure web applications effectively. 1. What is Spring Security? Spring Security is a powerful and highly customizable authentication and access-control …
"Omozegie Aziegbe" / 2025-07-22 12 days ago / 未收藏/ Java Code Geeks/
发送到 kindle
Testing Spring Boot applications secured with OAuth2 Single Sign-On (SSO) can be difficult, especially when authentication relies on an external provider. To avoid depending on third-party services during test execution, we can simulate or bypass SSO. This article demonstrates two practical approaches: using MockMvc to bypass authentication and using WireMock to fake an OAuth2 SSO …
"Eleftheria Drosopoulou" / 2025-07-23 12 days ago / 未收藏/ Java Code Geeks/
发送到 kindle
Why Pants Might Be the Secret Weapon Your Monorepo Needs Managing large monorepos with multiple services, libraries, and languages is notoriously difficult. Traditional build tools like Maven and Gradle often start to buckle under the weight of dependency sprawl, slow builds, and complex configurations. That’s where Pants Build comes in—a fast, scalable build system designed …
"MSSQL123" / 2025-07-23 11 days ago / 未收藏/ 博客园_专注,勤学,慎思。戒骄戒躁,谦虚谨慎/
发送到 kindle
【摘要】某系统是一个非常老的MySQL从数据库,某天收到主从复制异常的报警,发现从节点的slave_sql_running线程断开,异常日志显示MySQL *** table is marked as crashed and last (automatic?) repair failed 错误日志中显示cr 阅读全文
"banq" / 2025-07-22 12 days ago / 未收藏/ jdon/
发送到 kindle
各位数学学渣(包括我)请注意!你们的人类尊严正遭受最新暴击,谷歌那个名叫Gemini with Deep Think的 "数字学霸"刚刚在国际数学奥赛(IMO)把金牌揣进了电子口袋。这货不仅用4.5小时解出5道变态难题,还像写情书一样全程用英语写证明过程,最后喜提35分(满分42),直接杀入金牌区!要知道去年它的前辈AlphaProof还只是个需要人类翻译帮忙的"银牌小弟"呢...(人类评委此刻正在后台偷偷抹泪)-----[第一幕:当AI学会"作弊式思考"]-----
"lex" / 2025-07-21 13 days ago / 未收藏/ SRE WEEKLY/
发送到 kindle
View on sreweekly.com A message from our sponsor, Spacelift: IaC Experts! IaCConf Call for Presenters – August 27, 2025 The upcoming IaCConf Spotlight dives into the security and governance challenges of managing infrastructure as code at scale. From embedding security in your pipelines to navigating the realities of open source risk, this event brings together […]
"Eevee" / 2025-07-23 12 days ago / 未收藏/ fuzzy notepad/
发送到 kindle
There are several old, personal events that I’ve been rotating in my head for a very long time. I’m finally writing about them because I’ve just had the staggering realization that they all form one singular story. In some cases I’d never made the connection; in other cases I just plain forgot that things which happened within hours of each other were related. This isn’t pleasant to write, and it won’t be pleasant to read. But I need it out of me. I might have some of the details wrong, since I’m piecing together fragments from decades ago. This is a story, not a documentary. It’s about me, no one else. content warning: underage sex; the active pursuit thereof by adults; bestiality mention.
My family moves from the UK (where my mother is from) to an American military base elsewhere (as my father is in the US military). In the switch from the UK to US school system, my parents push to have me put in second grade, on the grounds that I’ve been absorbing basically anything I’ve been exposed to since I was old enough to walk, and I’d be bored to tears in kindergarten. This puts me two grades ahead for my age, which makes me two years younger than everyone around me, which will remain the case until I graduate from high school. I’m still quicker on the uptake than most everyone in my grade, and later get shifted a third year ahead in math. I never have school-age peers. This is normal.
I’m a picky eater. A lot of foods actively repulse me. My mother keeps making them for dinner anyway. I do my best to eat around them. Once she makes a quiche, and the taste of the cheddar makes me instantly want to vomit, so I can’t eat any of it. My father insists I sit at the table until I’m finished. I try a few bites but can’t bear it at all. I sit there for an hour, alone, before he gives up and lets me slink away. I like computers. I don’t know much I can do with them besides toodle around in QBasic, but being able to write out instructions and have a thing happen feels like magic to me. I’m enamored. I’ll stay enamored for the rest of my life. I’m dimly aware that Windows and Office are also software, but they seem too incomprehensibly vast and complex to have been made, let alone made by fundamentally the same process I’m engaging in when I draw circles on the screen. I don’t consciously think about this, merely take for granted that they emerged fully-formed from a Company, which is somehow a different sort of entity from a person. I think the Internet sounds cool but I don’t really know what there is to do on it besides download utilities I don’t need or read about The Microsoft Windows 95 Product Team! easter egg, which I only ever get to work once. I also find out that you can trick MS Paint into taking a screenshot of its own help window, which is cool because I don’t know how to take actual screenshots. That means I can make fake UIs, which is cool because I don’t know how to make real UIs, and I don’t know how to draw, either. Art, too, seems like some kind of foreign magic. I’m really into Animorphs. I want to turn into a red-tailed hawk like Tobias and just fly away. I’m starting to do less well in school, and feel a budding hostility coming from my parents over it. I don’t have a lot of friends, don’t really have a sense of how to make them, and don’t think about it much. I feel a little out of place everywhere, but I always have, so it’s normal to me. I hear about book 16, The Warning. It’s the one with Jake morphing into a rhino on the cover. I haven’t read it yet, but as I understand it, the plot centers around one of the protagonists typing “yeerk” or something into a search engine and finding exactly one result, which they then go investigate. I think about this. I know about the Internet and search engines. But obviously, I think, entering “Yeerk” wouldn’t find anything, because Yeerks aren’t real. I try it anyway, just to see. I’m stunned to discover the world of fansites. One of them has a forum and even a chat room attached. I join both and am stunned once more to discover that the Internet has other people on it, just hanging out. The other people are all teenagers, a little older than me, but I’m used to that. Half of them also have overbearing parents, and we bond over bitching about them. I can be kind of weird and awkward here and it’s fine. I’m really happy about having found this little sanctuary, and I start spending a lot more time online.
I’m in ninth grade. My parents have put me in a private school, and it is fucking miserable. Homework is so tedious it feels akin to torture, so I just don’t do it, so my grades drop, so I get endlessly scolded and told I’m a disappointment. Chores, too, are agonizingly boring, and my mother regularly screams at me for not doing the dishes. None of the adults in my life — not parents, not teachers, not other school staff — suspect I have ADHD, perhaps because I’m smart and quiet, and I will eventually work it out myself some years later. Everyone else seems to believe their lecture will be the one to finally inspire me. My parents, who had once fought to save me from boredom, don’t recognize it happening in front of them. I’m miserable at home from all the screaming, which makes me even more reclusive and less interested in school, which makes my grades all the more mediocre, which makes my parents yell more, which makes me more miserable. Perhaps luckily, I don’t draw any conscious conclusions from any of this. I have no sense of how other people experience the world, and I haven’t really thought about, say, whether homework is easy for other people. I don’t even understand that I’m struggling, because I have nothing to compare it to. I don’t remember being a little kid very clearly, so as far as I can tell, it’s just always been like this. This is normal. I have a little breakdown once and yell back at my mother, trying to convey… why I’m unhappy, without fully understanding it myself. She stands there, stunned. My father storms into the room, grabs me by my shirt collar, drags me upstairs to my bedroom, and throws me into it. He gets a utility knife and cuts through several random cables on my computer, then leaves without a word. One of the cut cables is my keyboard, so to use my computer, I have to steal the keyboard from his computer and be sure to return it before he gets home and notices. Otherwise I would be completely isolated. I learn a valuable lesson. Adults will hurt me, and this is normal. I hurt quite often, but I can’t do anything about it, and if I try, adults will hurt me more, so I just sit with it. Sometimes I used to cry, but then my mother would hear and come tell me (in a caring voice) not to, because I’d give myself a headache. I took that to mean I just shouldn’t, so I’ve stopped. My parents will later try to send me to a therapist a couple times — the problem is of course with me, not them, never them. I confide the encounter with my father, which makes it through some unseen grapevine, and I end up having to talk to some sort of military-HR person about it. Fearing that I might get put into the foster system and things will somehow end up worse, I lie that I had it coming. I hate lying, but I’ve learned that I have to lie to adults sometimes, so they won’t hurt me as much. It isn’t mentioned again. My parents never say a word to me about it… until over a decade later, when my mother will tell me that I was physically imposing and physically threatened her. I will have no idea what she’s talking about — until that moment, the thought of attacking her in some way never crosses my mind. I’ll also be a late bloomer, insofar as I’ll bloom at all, and one of the few strong images I’ll remember from that day will be my mother looking down at me. But she will remain absolutely convinced that I was a threat, and that is why my father took the therefore-fully-justified actions he did, and I will be unable to disabuse her of this notion up through the end of her life. One day, many years later, she will die of cancer, having never believed me about my own motivations. She will also, in the same conversation, chide me for not doing the dishes. I will be almost thirty years old.
I’m in tenth grade, taking AP calculus. I’m good at it, but the homework is still mindnumbing. I try to coast through my own life, attracting as little attention as possible from the adults around me who have the power to hurt me. I’m not fully successful. But when I’m hurt, it’s normal. I’m still online a lot. I’ve gotten into doing, well, “web stuff”. It started out with posting little JavaScript snippets onto a small forum that doesn’t strip it out, or using a lot of <font> tags to make rainbow text. I’ve also gotten into Pokémon, and I feel a strong affection for tables and lists, so I start to make a Pokédex website. I don’t really know what I’m doing, and much of the effort comes from painstakingly retyping information from strategy guides or just other people’s websites, a process my future self will find comically rudimentary in hindsight. But it still feels like magic, and now I can share it with other people, too. I don’t know if anyone uses my website, but I’m delighted to have made it. I’ve also hit puberty — several grades after everyone else, which has been a little awkward — and am starting to hear about this “sex” thing. It sounds pretty interesting. I end up combining my interests and joining an IRC channel dedicated to Pokémon porn. I’m probably the youngest person here, but no one cares, and I have no sense that there’s any reason anyone would care. There are some older teenagers here, as well as some adults, ranging all the way up to one 40-year-old — but he’s a completely regular cheerful guy who just genuinely enjoys writing fics about Sabrina having sex with an Alakazam or whatever. But there’s also a guy who makes the occasional comment about “little girls”. There are at least one or two people who casually mention they have regular sex with their dogs. No one bats an eye at this, so I don’t, either. I have no basis for comparison, because I am fourteen years old. Maybe this is normal. Everyone else acts like it’s normal. It must be normal. Sometimes people try to have cybersex with me. I’m not very good at it. I don’t really know anything about sex, but I start to pick it up from how other people describe it. It’s fun to write about this thing I’ve never done, this activity so mysterious that it almost feels like it must itself be fictional. It feels like it only exists in a bubble, completely detached from normal life. Offline, I still barely know anyone. I’ve sort of gravitated to a couple other nerds at school, but outside of the fact that we are all vaguely aware how to make a website, we don’t have a lot in common. One of them is just kind of mean, even. This is normal. I’m two years into high school and just barely hitting the age when most people are starting it. I live in Hawai‘i at the moment, and almost everyone else has lived here their whole lives, but I’ve never even been to the same school for more than two years. I find out about a little old-school website where furries can enter their location and find other furries nearby. I put in my zip code. Nobody else, it seems, lives in Hawai‘i.
We move, for the fourth time in my life, this time to the US mainland. I update my zip code on the furry location website. Still nothing. But then, out of nowhere, I get a message from someone I don’t know, who I’ll call 🐨. He’s eighteen, four years older than me, but that’s normal. He says he used to live in my town and he’s passing through for just a day or two, and would I like to meet up? I’m fucking ecstatic and say yes. My mother drives me to where he’s staying. It has that 1970s wood panelling everywhere, which I might be seeing for the first time. It ultimately leaves me with a strange, otherworldly impression. We talk a bit, and then he clearly wants to have sex. This hadn’t come up in our brief conversations beforehand. He seems surprised, but unswayed, that I haven’t had sex before. I don’t see any reason to turn him down — sex is supposed to be The Best Thing, after all. We fool around some. It’s… fine. I don’t really like how he touches me. But hurting is normal, and this barely hurts at all, so I don’t say anything. I don’t even know how to say anything. People don’t show much interest in what I want. If anything, what I want seems to be an inconvenience to everyone else. So I don’t say anything. It’s fine. This is normal. Things peter out. I go home. I’m no longer a virgin. It seems like something should be different. But nothing is. I don’t really think about it. I try to keep in touch with 🐨, but he isn’t around much. He’s part of a little group of furries who all live in the same town and know each other, though, and they start to reach out, and I talk to some of them.
[Hello, future Eevee here. Just letting you know, this is your last chance to back out. –ev] I’ve just graduated high school. I’m so close to being away from my parents, to living on a college campus in a distant state. It’s exhilarating, but also terrifying, because I don’t really know how to live on my own. I’ve never done laundry or bought my own food. I don’t have a car or much money. I don’t really know how to do anything, other than make websites that look like they were made by a sixteen-year-old. Over the past couple years, a number of guys have shown sexual interest in me. Almost all of them have been eighteen or older. I’ve met some of them at furry conventions and had sex with them. I didn’t really like any of it. But I’m desperately starved for affection and still assume the problem is with me, so I keep taking any opportunity I’m given. Maybe the next time will be better? I don’t know what else to do, so I keep doing what I’m doing. I’m sufficiently self-aware of this inner turmoil to post about it. The only relevant comment I get is from someone I do not know and never otherwise speak to. There is absolutely nothing wrong with giving it up for whoever wants it, especially at your age!
I am sixteen years old. This is normal. It can only be normal. No one else thinks anything of it, so I don’t either. I attend another furry convention not long before I’m to move into a college dorm. My family’s situation is a little complicated at the moment — the house has been sold, my mother is in an apartment in our old town, my father is in an apartment in the new town, I’m off to a convention, and somehow this is all intended to coalesce later. I have two sexual encounters that have… ramifications. One is with 🐯, who I met somehow-or-other through 🐨’s group, despite not being local to them. [I have no memory whatsoever of how we met, why we started talking, or what we talked about. –ev] He is twenty-six years old, a full decade my elder. He is openly interested in me because I’m underage. This is normal. After all, I am underage, and most of the people capable of travel are adults, so anyone who would have sex with me would at the very least have to find it acceptable that I’m underage. We meet up at this con. He has sex with me. As usual, I don’t really know why I’m participating. It’s the worst sex I will ever have in my life, deeply unpleasant and uncomfortable. I spend every single moment of it desperately wishing for it to be over, but I don’t know how to ask him to stop. I expect people to hurt me if I push back against what they want from me, but I’m not even cognizant of this — I see myself as just wanting to make people happy. Eventually I can’t take it any more and, in a flash of inspiration, offer to fellate him instead. I don’t really care for that, either, but it’s much less bad. He gets me to promise I won’t tell anyone. I’m vaguely aware that this is the sort of thing he shouldn’t be doing, and I don’t want anyone in trouble on my behalf, so I agree. There’s also 🐸, who I’m at least acquainted with, though we’re not exactly close. We hang out in a couple of the same IRC channels and have friends in common. Also, we’re the same age, almost exactly — we were born in the same month. We also meet up and have sex. This time, at least, it seems like sort of maybe a good idea. At least it’s someone I know. It’s not great, but it’s not nightmarish, either. He leaves his phone in my hotel room. I happen to catch a glance of him a little later, and so I run up to him to return his phone. His father is with him, and is furious. He’s absolutely convinced I’m some kind of sex predator, despite that we’re exactly the same age and I look younger than 🐸. I go for my wallet but he sense my intentions and angrily insists he doesn’t care what kind of ID I have. He declares he’s placing me under citizen’s arrest, a thing I’ve never even heard of. But of course, I believe I have to go along with adults, or they’ll make things even worse. He actually calls the police, who spend about two seconds checking my ID and say “yeah this is fine”. But then they want me to Make A Statement Down At The Station, so I go there, and I awkwardly describe a bland teenaged sexual encounter to someone who is a remarkably slow typist considering it seems to be their whole job. And now I’m at a police station, and the police only want to release me into my parents’ custody, because I am sixteen years old. So they call my father, who is thankfully only a few hours’ drive away. And they put me in a chair and tell me that if I get up they’ll lock me in a cell. And I sit there, for two hours, while cops twenty feet away crack jokes with each other about the fact that two teenagers fucked. It may have been more or less than two hours, but I have undiagnosed ADHD, which has a way of stretching out activies like sitting in a chair doing nothing. My father arrives, so silently furious that he accidentally drives into the wrong state on the way back to his apartment. He demands I log into my laptop, and he changes my password. Once I’m alone, because he’s off at his job as some sort of network administrator, I log into my laptop as admin, and change my password back. [Bright spot in this story. Fucking hilarious. Great job, li’l Eevee. –ev] I then write a public post about the experience, which ends up linked on a now-defunct drama site. A bunch of people — who are we kidding here, more adult men — have a grand laugh about, again, two teenagers having sex. It probably doesn’t help that the post is written in an almost painfully cutesy affect, since I am sixteen years old. Several dramamongers approach me personally to be nasty, including one who calls me a “sick fuck” for “doing kids”. I am sixteen years old. One of the convention staff also emails me with a brief rant, asking why I’m trying to destroy the convention by writing about things that happened to me, because now he’s fielding accusations that the con is full of pedophiles (presumably, again, because I had sex with someone my age). I have no idea what to say to this and never reply. I do show it to 🐯, hoping for support. I happen to think that it’s absurd to blame someone for posting that they had sex at a con. But 🐯 insists I’m wrong and should apologize. I deflate. My father later talks to me about the event. The conversation is extremely one-sided, because I know what happens if I push back against anything. He tells me I’m cold, calculating, manipulative, evil. He tells me I care only about myself. That I have no soul. That he doesn’t want me in the house. I am sixteen years old. All of this is normal. The irony is, unfortunately, lost on me — because as requested, I erased mention of 🐯, the twenty-six-year-old who had sex with a sixteen-year-old, from my story. I erased it so thoroughly that I will forget these two encounters happened on the same weekend until many years later, even as I will continue to be lightly haunted by a memory of horrendous sex I felt trapped in. Sometime in the next week and a half, I admit to someone that I had sex with 🐯. [I don’t know who, but I think I was pointedly asked, and I didn’t really know how to reject questions, and I’ve never liked lying, so I can extremely see how I would end up just saying it. –ev] This makes it through some unseen grapevine, and suddenly 🐯 is furious with me, threatening to end the friendship [lol –ev] unless I fix it somehow, by convincingly lying to someone in this gossip chain that I don’t know. I make a half-hearted attempt, which I hate, and am (unsurprisingly) not believed. Our relationship, such as it is, deteriorates, both because 🐯 himself deteriorates and because I don’t seem to have as much interest in trying to be friends with the person I had inescapable nightmare sex with. I must feel resentful of him without ever wanting to confront him directly, because I will later discover a few remaining scraps of one of our last conversations: 🐯: Gods eevee you’ve become such an annoying little bitch, I can’t beleive I was ever even nice to you. I wouldn’t have come within 20 feet of you had I known you were this kind of person.
I am sixteen years old. I am being spoken to by a twenty-six-year-old man. 🐯: gods, you and your stupid faces
I am sixteen years old, and I use emotes as punctuation o.o to a ridiculous degree ^o.o^ like multiple times per line o.o and the twenty-six-year-old man who was so eager to have sex with me is now sick to death of how juvenile I am. If only there were some way he could have foreseen this. I am sixteen years old, but I begin to realize I do not give a shit about this loser who can only bed teenagers, nor about his big important opinion of me. He’s mad at me, but it doesn’t matter. Adults have been mad at me my entire life. What’s he going to do, type at me? I glaze over. I become laminated. I rebuff everything. He only talks to me once more, to say he misses seeing me around. I don’t care. I am sixteen years old. I start to wonder if this isn’t normal.
Someone new joins the Pokémon porn IRC channel. They are fifteen years old. I don’t think anything of it, just as no one thought anything of it when I first entered. This is normal. Sort of. I recognize their name from the artwork that decorates several Pokémon fansites. I find it fascinating that they were able to create any of that. It’s like magic to me. There are a few artists here already, but this is the first whose art was truly captivating to me. Somehow it feels more impressive yet also more real, like I can believe it was done by a person. It plants the tiniest seed that maybe, one day, I can do it too. I approach them to say hi, that I like their art. We have an actual conversation, then another. It’s like a breath of fresh air. So many people I’ve talked to have just wanted to hit on me way past the point of comfort and barely have a personality beyond that. But nothing like that happens here. Instead we talk about actual things: Pokémon, and art, and our lives, and all the wrinkles they’ve had so far. They like cats. I like puzzles. Sometimes they struggle with pressure from overbearing commissioners, and something about that must resonate with me, so I try to be supportive. Later I’ll admit I’m still struggling with affection and my inability to tell people no, and they’ll be supportive of me, too. It’s nice. One day, it’ll even be normal.
I’m at the DMV. My best friend, someone I met a lifetime ago — in a Pokémon porn chat, of all places! — is here with me. We live together, now, with our five cats, and we’ve recently escaped someone we both struggled to push back against. It feels like a small victory, but it was hard-earned. We both sign the marriage certificate.
I’m thinking back on a lot of things. It’s almost dizzying to see so many little threads of causality. My parents, even teachers, practically training me to think that whatever other people want is paramount. The deeply fucked-up culture of early-00’s Internet, where people could just openly announce their interest in doing sex crimes and no one batted an eye. Even the notion of a 14yo in a space dedicated to porn sounds unthinkable by today’s standards, but I poked my head in a lot of sex-themed places back in the day and not one of them cared how old I was. I suppose I was well-spoken enough to sound older (aside from the hailstorm of o.o), but at the same time my social development was… almost non-existent. Hence how I had 20-somethings talking to me like I was an equal, all while I didn’t even understand how to say “I don’t like this”. It took me a few more years to extricate myself from the weird little rut I’d dug for myself. It certainly helped that, around nineteen or twenty, vastly fewer random older men were interested in me. I’ll just, uh, try not to think too hard about that. I don’t know what would have helped me avoid this. I keep thinking back to the vague ambient warnings about the Internet in the early 00s, which mainly focused on how anyone might be lying to you, might be pretending to be your age to trick you into sex later. But that never happened to me. It was so unlike my experience that it almost feels laughable. Everyone I had sex with was pretty open that they wanted to have sex with me, and I agreed. No one ever warned me that sex without pretense could have emotional consequences. Everything in my (regular, offline) life that tried to tell me anything about sex was laser-focused on either pregnancy, STIs, or a guy in a van offering me candy. Like, hello, I was a deeply lonely sixteen-year-old. They didn’t need to offer me candy. They just offered me sex! And there are lingering consequences — although now that I’m happily married and no longer on the radar of a bunch of people who really want to sleep with a teenager, they largely don’t matter in practice. But I had so much terrible, uncaring sex with men that I feel a little anxious even considering the thought of doing it again. There’s no one besides my spouse who I want to have sex with at the moment, but I still don’t like having that stuck in me. Like a shackle around my ankle that isn’t chained to anything, but it’s still there, and occasionally I feel it rattle. But what really struck me, what really compelled me to write this down, was the realization of a strange pattern in the post-con sequence of events. I think it’s fair to say that 🐯 used me for sex. I played along, but I think there’s at least a little bit of a responsibility gradient here. But then, wait. Some group of people confirmed with me that I’d had sex with 🐯, and then I guess started gossipping about it, possibly even harassing him. Do you know how many people from that circle reached out to me, to see how I was doing? Zero. Nada. I was useful only as long as it took to crystallize a nugget of Drama™, and then I was no longer needed. So let me recap, this time with some editorializing:
A man ten years my elder used me for sex.
A bunch of adult men used me for laughs.
Some kind of gossip ring used me for, well, gossip.
A con staff member used me to vent about something that, frankly, furry conventions seemed to deal with a lot in the 00s.
Not one of these many adults reached out to see if I was okay. The con staff guy didn’t know about 🐯, of course, but they did know I’d had a harrowing experience and now was having at least one more — because those are what my whole fucking post was about! — and yet the only reason they went through the effort to find my email and reach out was to blame me for it again. But it’s the gossip ring that I truly cannot excuse. The sole reason there was any gossip to be had at all was the idea that a twenty-six-year-old having sex with a sixteen-year-old is, in some sense, bad. But this clearly didn’t actually mean anything to them! It was “bad” only in the abstract, “bad” only in the sense that it gave them an excuse to ostracize the “bad” person, or laugh, or whatever the fuck they were doing. It’s no different than that drama-site clown calling me a “sick fuck for doing kids” or whatever the hell. You could not possibly read a post about how I had to wait for my dad to pick me up because the cops wouldn’t release a minor and not grasp that I am a minor. Like, I AM “THEKIDS”! You, my fucking guy, right now, are being cruel towards the people you’re feigning concern for! But it just didn’t matter what happened or who was involved or who was hurt by it. Some asshole — almost certainly yet another adult — just wanted to be nasty, and they thought they saw someone they were allowed to be nasty to, so they were. None of these people were interested in helping a sixteen-year-old. They only wanted to lash out at someone. The best I got was a tiny apology from 🐯, of all fucking people, who eventually caught on that I had not fully enjoyed our time together. But he can, of course, shove that entirely up his ass. For many, many years, I’ve avoided making any mention of the thing with 🐸, my first exposure to the Internet “Drama” Circuit. I feared it would happen again, or that I’d be called a pedophile some more by people who just conveniently forget that we were the same age. I’d completely forgotten that 🐯 happened at the same time — because he’d basically asked me to detach him from the rest of it! Rediscovering that little tidbit has sure cast this story in a different light. But like, fuck that, regardless? I will talk about my own life in whatever goddamn way I please. As soon as I decided to write this down, I couldn’t even remember why I’d ever been scared to do it. I guess I had been pretty thoroughly punished for writing it down the first time. And sure, with decades’ worth of hindsight, it was perhaps not a good idea to have described my underage sex life — or the brief entanglement of the police with it — in public. But I still reject the idea that it was wrong to do so, or that any subsequent ragging on the convention was my fault. The actual story here (once 🐯 was stripped from it) was that Some Fucking Guy overreacted and called the cops because his teenaged kid got laid and he didn’t like that. That is fucking bananas behavior for a grown-ass man, but somehow fingers ended up pointed at literally everyone else. Clown world. And various people have been calling me a pedophile ever since anyway. I’m often not privy to why. Like, as best as I could discern, the Something Awful Pokémon crowd branded me a pedo at one point because I had some cutesy, non-sexual, unremarkable artwork of myself (i.e., an Eevee person) as the background of my website for a while. Like that’s it, that’s the whole thing. Conspicuously, I am not attracted to, or otherwise interested in, teenagers or children, but that just doesn’t seem to factor in. You’d think it would be kind of important, right? But there’s this weird chain of semantic implications that lets you suggest someone actively molests children based purely on vibes, without ever having to identify any concrete child, and that seems kind of bad to me, but if I try to explain it I’ll probably be called a pedophile, because why would anyone but a pedophile defend pedophiles by nitpicking the definition of “pedophile”, huh? Meanwhile, I was actively pursued by much older adults! 🐯 isn’t even the oldest guy who had sex with me when I was sixteen! But I’ve spent half a lifetime nervous about even admitting that, out of some nebulous fear of the reaction, all while I get lumped in with the sort of people who did it to me because my website background doesn’t have a suit and tie or what the fuck ever. What a joke. It makes me feel fucking crazy, sometimes, to watch our culture obsess over rooting out anyone with a whiff of “pursues sex with a minor” with the same furor and accuracy as we once rooted out people possessed by Satan, but with “the minor” — a person — reduced to a sort of… fantasy hypothetical? Or just dropped entirely, I guess. “Pedophile” is the thing you call someone that makes you win, because that’s the worst thing, and they can’t prove you wrong. Even the richest man in the world does it. Sometimes I think about what might happen in another timeline, where I’m sixteen now and I post this story. I’m sure 🐯 would be absolutely roasted right off the Internet — but how many people would still check on me for anything other than more sordid details? …But then, who have I checked on? How many times have I had the opportunity, and not taken it? I can definitely think of one or two. But that’s a whole other rabbit hole. This sucks. I feel like basically every adult in my teenaged life let me down, and I have no idea what to do with that information. I guess all I can do is try to reach back in time with the power of blogging and say what I desperately needed to hear. If you are a teenager reading this — I don’t know how or why, but I am functionally powerless to stop you — and even a little bit of it has resonated with you, then let me impress upon you this: how you feel matters. Even if it doesn’t seem to matter to the people around you, the people with power over your life, it should still matter to you. Hold onto it, even if you have to hide it, and do not let go for anyone. I’m sorry for whatever you may feel trapped in. I’m sorry if it’s hard. It might keep being hard for a little while. But if you keep looking, you will find people who care about what you want, who will have your back when you struggle to stand up for yourself, and who won’t punish you for hurting. Please take care of yourself. P.S.: Sex is an amplifier, not an automatic good time. It’s like Mario Party: a hilarious chaotic mess with the right people, but a horrible fucking slog with the wrong people. I am thirty-eight years old. I still think about what happened to me when I was sixteen. Not all the time. But sometimes. Maybe after today, I can finally stop.
"Bruce Schneier" / 2025-07-20 14 days ago / 未收藏/ Schneier on Security/
发送到 kindle
ProPublica is reporting: Microsoft is using engineers in China to help maintain the Defense Department’s computer systems—with minimal supervision by U.S. personnel—leaving some of the nation’s most sensitive data vulnerable to hacking from its leading cyber adversary, a ProPublica investigation has found. The arrangement, which was critical to Microsoft winning the federal government’s cloud computing business a decade ago, relies on U.S. citizens with security clearances to oversee the work and serve as a barrier against espionage and sabotage. But these workers, known as “digital escorts,” often lack the technical expertise to police foreign engineers with far more advanced skills, ProPublica found. Some are former military personnel with little coding experience who are paid barely more than minimum wage for the work.
This sounds bad, but it’s the way the digital world works. Everything we do is international, deeply international. Making anything US-only is hard, and often infeasible. EDITED TO ADD: Microsoft has stopped the practice.
"Bruce Schneier" / 2025-07-22 13 days ago / 未收藏/ Schneier on Security/
发送到 kindle
Law journal article that looks at the Dual_EC_PRNG backdoor from a US constitutional perspective: Abstract: The National Security Agency (NSA) reportedly paid and pressured technology companies to trick their customers into using vulnerable encryption products. This Article examines whether any of three theories removed the Fourth Amendment’s requirement that this be reasonable. The first is that a challenge to the encryption backdoor might fail for want of a search or seizure. The Article rejects this both because the Amendment reaches some vulnerabilities apart from the searches and seizures they enable and because the creation of this vulnerability was itself a search or seizure. The second is that the role of the technology companies might have brought this backdoor within the private-search doctrine. The Article criticizes the doctrine particularly its origins in Burdeau v. McDowelland argues that if it ever should apply, it should not here. The last is that the customers might have waived their Fourth Amendment rights under the third-party doctrine. The Article rejects this both because the customers were not on notice of the backdoor and because historical understandings of the Amendment would not have tolerated it. The Article concludes that none of these theories removed the Amendment’s reasonableness requirement.
2025-07-23 12 days ago / 未收藏/ ongoing by Tim Bray/
发送到 kindle
I just posted a big
PR representing months of work, brought on
by the addition of a small basic regular-expression feature. This ramble doesn’t exactly have a smooth story arc but I’m
posting it anyhow because I know there are people
out there interested in state-machine engineering and they are my people.Quamina As far as I can tell, a couple of the problems I’m trying to solve
haven’t been addressed before, at least not by anyone who published their findings.
Partly because of that, I’m starting to wonder if all
might
be worked into a small book or monograph or something. State machines are really freaking useful software constructs!
So yeah, this is a war story not an essay, but if you like finite automata you’ll likely be interested in bits of it.these disorderly Quamina postings Prior to beginning work on Regular Expressions, I’d already wired shell-style “” wildcards into Quamina, which
forced me to start working with NFAs and ε-transitions. The implementation wasn’t crushingly difficult, and
the performance was… OK-ish.* Which leads me to The Benchmark From Hell.
I wondered how the wildcard functionality would work under heavy stress, so I pulled in a list of 12,959 five-letter strings
from the Wordle source code, and inserted a “” at a random position in each. Here are the first ten:* I created an NFA for each and merged them together
. Building and merging the automata were
plenty fast enough, and the merged NFA had 46,424 states, which felt reasonable.
Matching strings against it ran at under ten thousand per second, which is pretty poor given that Quamina can do a million or
two per second on patterns encoded in a DFA.as described here But, I thought, still reasonably usable. Last year, my
had led me
to the zero-or-one quantifier “”. The state machine for these things is not rocket science; there’s a discussion
with pictures in my recent
.slow grind through the regexp featuresEpsilon Wrangling? So I implemented that and fired off the unit tests, most of which
, and they all failed.
Not a surprise I guess.I didn’t have to write It turned out that the way I’d implemented ε-transitions for the wildcards
, as in it worked for the tight-loop
state-to-itself ε-transitions, but not for more general-purpose things like “” requires.was partially wrong? In fact, it turns out that merging NFAs is hard (DFAs are easy), and I found precious little help online.
does give an answer: Make an
otherwise-empty state with two ε-transitions, one to each of the automata, and it’ll do the right thing. Let’s call that
a “splice state”. It’s easy to implement, so I did. Splicing is hardly “merging” in the Quamina sense, but still.Thompson’s construction Unfortunately, the performance was hideously bad, just a few matches per second while pegging the CPU.
A glance at the final NFA was sobering; endless chains of splice states, some thousands long. At this point
I became very unhappy and got stalled for months dealing with real-life issues while this problem lurked at the back
of my mind, growling for attention occasionally. Eventually I let the growler out of the cave and started to think through approaches. But first… Is it, really? What sane person is going to want to search for the union of thousands of regular expressions in general or
wild-carded strings in particular? I didn’t think about this problem at all, because of my experience with Quamina’s parent,
. When it became popular among several AWS and Amazon teams, people
sometimes found it useful to match the union of not just thousands but a million or more different patterns. When you write
software that anyone actually uses, don’t expect the people using it to share your opinions on what is and isn’t
reasonable. So I wasn’t going to get any mental peace until I cracked this nut.Ruler I eventually decided that three approaches were worth trying: I ended up doing all of these things and haven’t entirely given up on any of them.
The most intellectually-elegant was the transform-to-DFA approach, because if I did that, I could remove the fairly-complex
NFA-traversal logic from Quamina. It turns out that the Net is rich with textbook extracts and YouTubes and slide-shows about how to do the NFA-to-DFA
conversion. It ended up being quite a pleasing little chunk of code, only a couple hundred lines. The bad news: Converting each individual wildcard NFA to a DFA was amazingly fast, but then as I merged them in one by one,
the number of automaton states started increasing explosively and the process slowed down so much that I never had the patience
to let it finish. Finite-automata theory warns that this can happen, but it’s hard to characterize the cases where it does.
I guess this one of them. Having said that, I haven’t discarded the code, because perhaps I ought to offer a Quamina option to
apply this if you have some collection of patterns that you want to run really super fast and are willing to wait for a while
for the transformation process to complete. Also, I may have missed opportunities to optimize the conversion; maybe it’s making
more states than it needs to?nfa2Dfa Recently in
I described how NFA traversal has to work,
relying heavily on implementing a thing called an ε-closure.Epsilon wrangling So I profiled the traversal process and discovered, unsurprisingly, that most of the time was going into memory allocation
while computing those ε-closures. So now Quamina has an ε-closure cache and will only compute each one once. This helped a lot but not nearly enough, and the profiler was still telling me the pain was in Go’s allocation and
garbage-collection machinery. Whittling away at this kind of stuff is not rocket science. The standard Go trick I’ve seen over
and over is to keep all your data in slices, keep re-using them then chopping them back to
for each request. After a while they’ll have grown to the
point where all the operations are just copying bytes around, no allocation required.[:0] Which also helped, but the speed wasn’t close to what I wanted. I coded multiple ways to do this, and they kept failing. But I eventually found a way to build those
automata so that any two of them, or any one of them and a DFA, can merged and generate dramatically
fewer ε-transition chains. I’m not going to write this up here for two reasons: First of all, it’s not
interesting, and second, I worry that I may have to change the approach further as I go on implementing new regxp operators.that In particular, at one point I was looking at the code while it wasn’t working, and I could see that if I added a particular
conditional it would work, but I couldn’t think of a principled reason to do it. Obviously I’ll have to sort this out
eventually. In the meantime, if you’re the sort of um special person who is now burning with curiosity, check out my branch from
that PR and have a look at the type.spinout Anyhow, I added that conditional even though it puzzled me a bit, and now you can add wildcard patterns to Quamina at 80K/second,
and my 12.9K wildcards generate an NFA with with almost 70K states, which can scan events at almost 400K/second. And that’s good
enough to ship the feature.“?” By the way, I tried feeding that 70K-state automaton to the DFA converter, and gave up after it’d burned an hour of CPU and
grown to occupy many GB of RAM. Add “” and “”, and really hope I don’t have to redesign the NFA machinery again.+* Also, figure out the explanation for that puzzling statement.if Despite the very narrow not to say obsessive focus of this series, I’ve gotten a few bits and pieces of positive feedback. So
there are a few people out there who care about this stuff. To all of you, thanks.

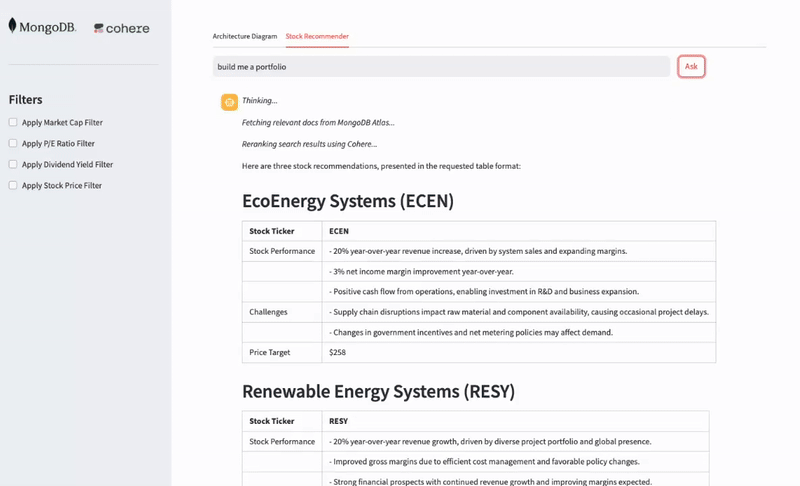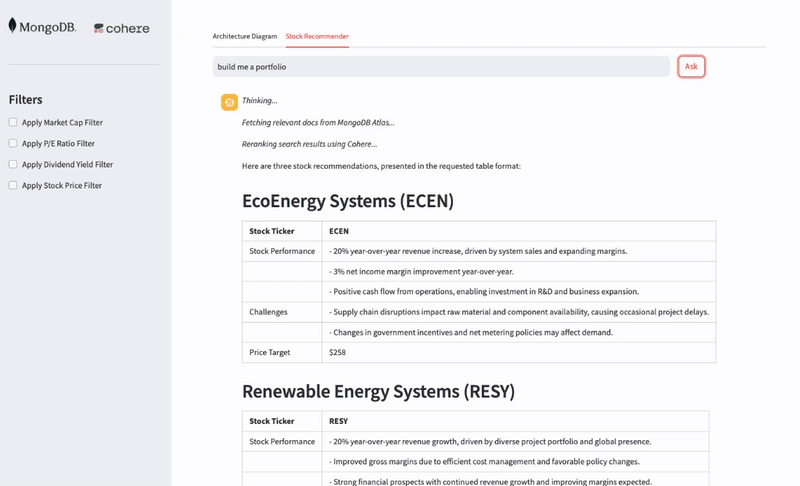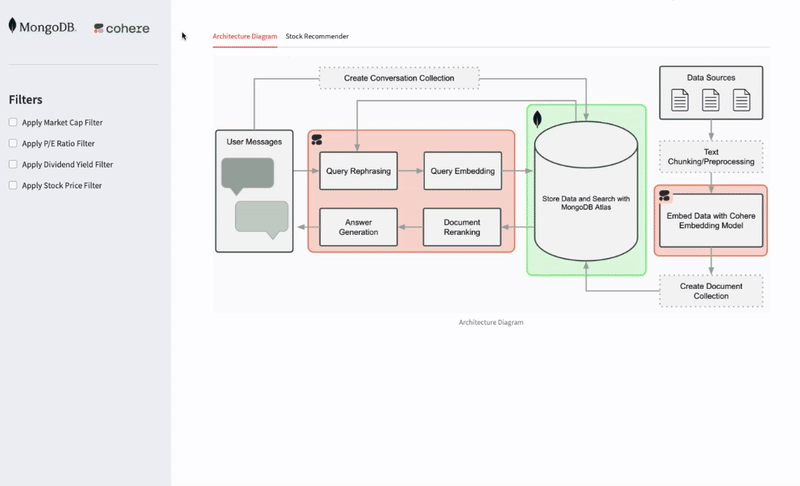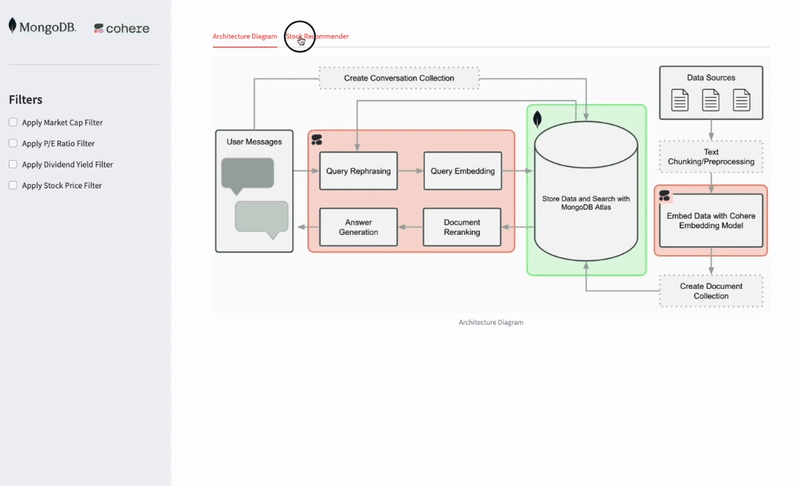






 本站發布了大量的「Blogger 小工具」,其中程式碼比較多的,需要將部份 JS 打包並外連以節省空間。因 JS 外連需要網路空間,原本寫了篇公告「WFU BLOG 外連 JS 操作說明」,建議將外連 JS 放到 Google Drive 或 Dropbox 等,並搭配外連產生器製作 JS 連結。
但可惜的是,近年來這些免費網路空間都中止了公開外連服務。也就是說,若曾使用 Google Drive、Dropbox 的 JS/CSS 外連,現在都會變成死連結了。
為了避免再發生 JS 外連失效的憾事,本篇提供了幾個長遠來看比較有效的作法,也包含了專門提供 JS 外連的服務 jsDelivr 、 Githack,除了比一般免費空間安全一些,令人驚豔的是還有 CDN 加速效果。
本站發布了大量的「Blogger 小工具」,其中程式碼比較多的,需要將部份 JS 打包並外連以節省空間。因 JS 外連需要網路空間,原本寫了篇公告「WFU BLOG 外連 JS 操作說明」,建議將外連 JS 放到 Google Drive 或 Dropbox 等,並搭配外連產生器製作 JS 連結。
但可惜的是,近年來這些免費網路空間都中止了公開外連服務。也就是說,若曾使用 Google Drive、Dropbox 的 JS/CSS 外連,現在都會變成死連結了。
為了避免再發生 JS 外連失效的憾事,本篇提供了幾個長遠來看比較有效的作法,也包含了專門提供 JS 外連的服務 jsDelivr 、 Githack,除了比一般免費空間安全一些,令人驚豔的是還有 CDN 加速效果。
 參考上圖:
參考上圖:
 如上圖是進入「test.js」這個檔的頁面,有兩個方式取得 raw 連結:
如上圖是進入「test.js」這個檔的頁面,有兩個方式取得 raw 連結:
 進入「Githack」官網後如上圖:
進入「Githack」官網後如上圖:
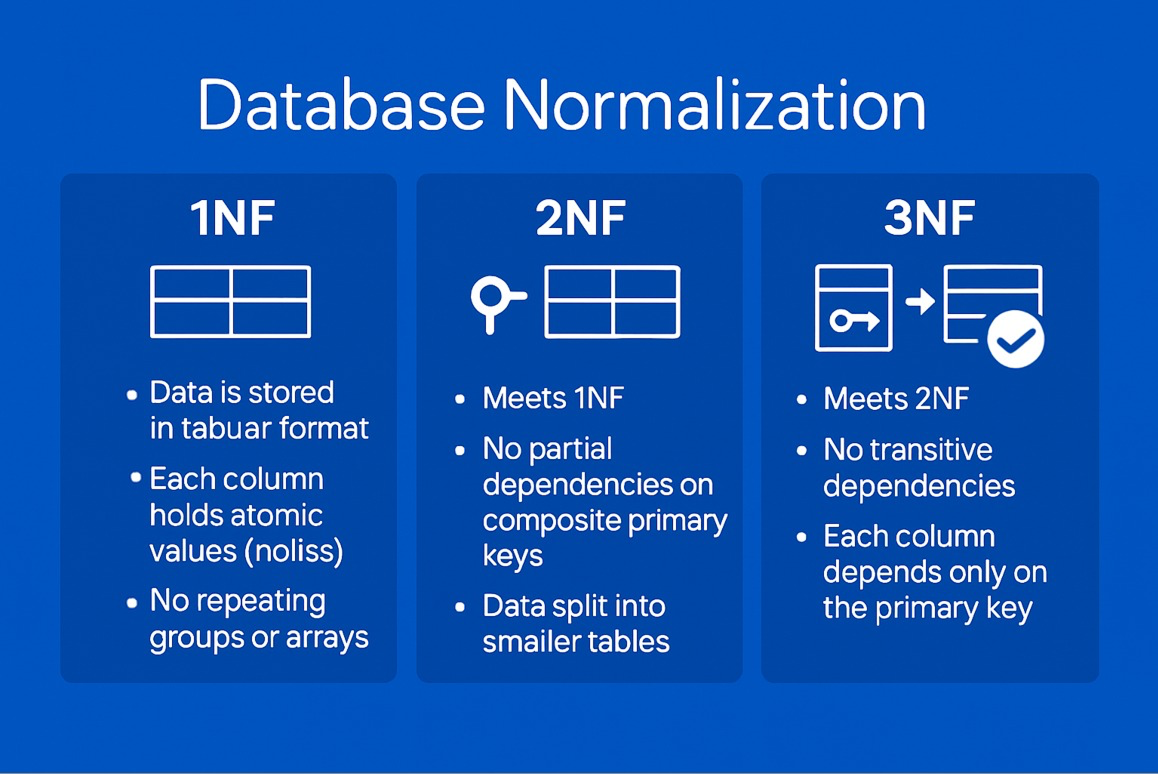
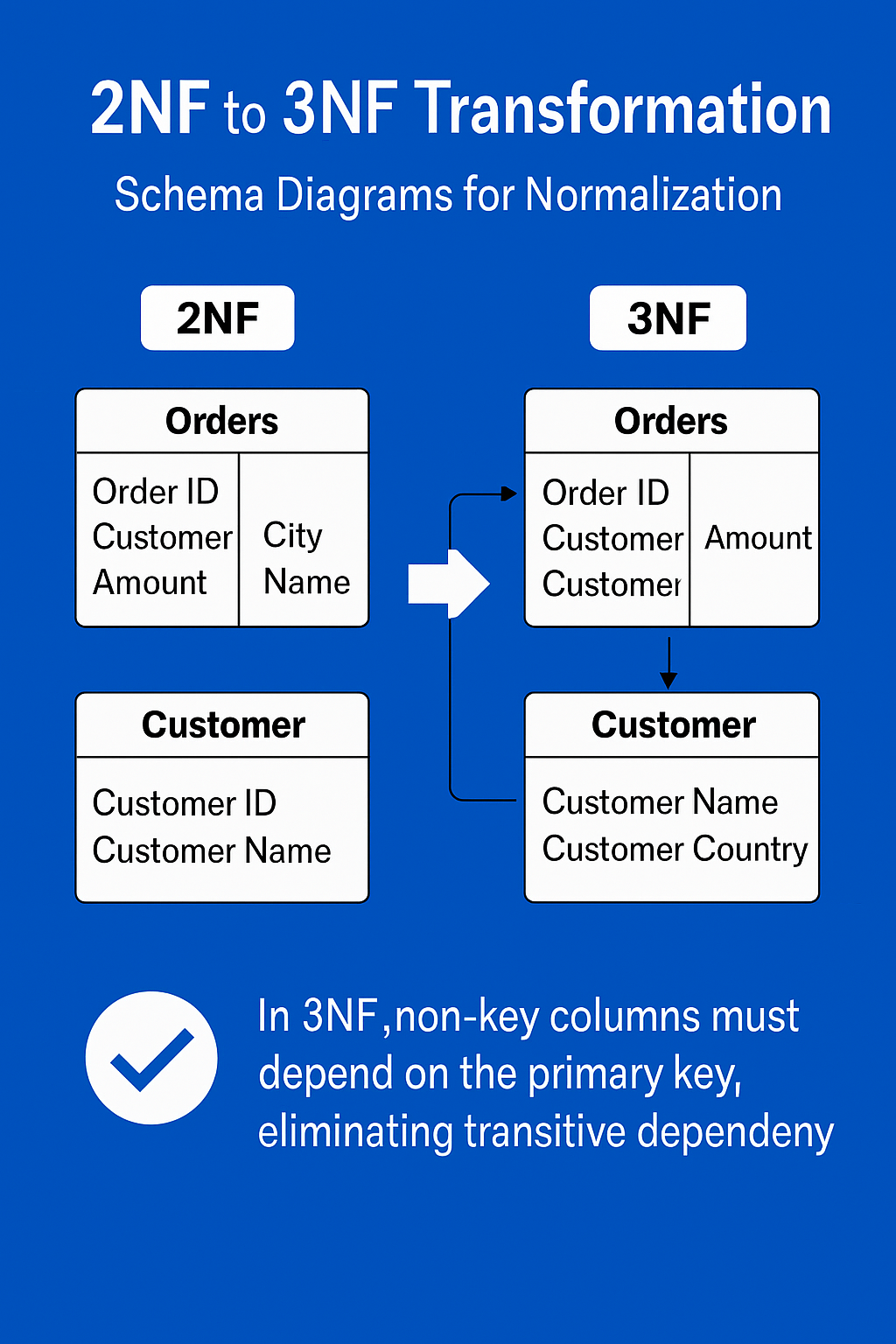
 Worktile 9.55.0 版本主要优化了项目集相关的功能,包括:
Worktile 9.55.0 版本主要优化了项目集相关的功能,包括: